最通俗易懂的 HashMap 源码分析解读
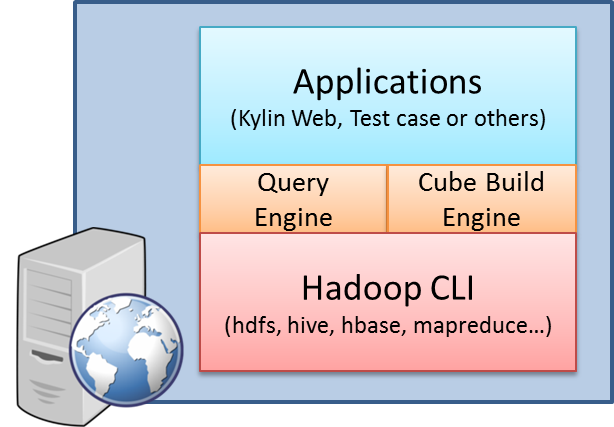
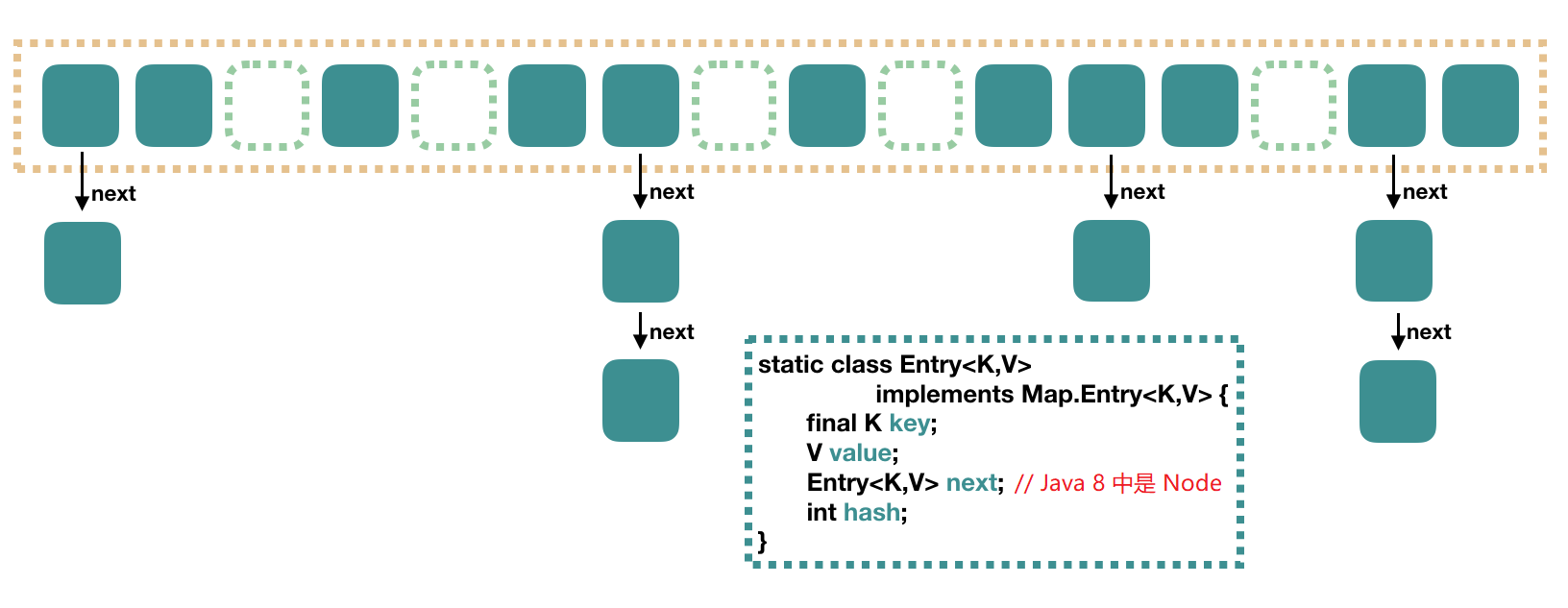
文章已经收录在 Github.com/niumoo/JavaNotes ,更有 Java 程序员所需要掌握的核心知识,欢迎Star和指教。 欢迎关注我的公众号,文章每周更新。 HashMap 作为最常用的集合类之一,有必要深入浅出的了解一下。这篇文章会深入到 HashMap 源码,剖析它的存储结构以及工作机制。 1. HashMap 的存储结构 HashMap 的数据存储结构是一个 Node<k,v> 数组,在(Java 7 中是 Entry<k,v> 数组,但结构相同) public class HashMap<k,v> extends AbstractMap<k,v> implements Map<k,v>, Cloneable, Serializable { // 数组 transient Node<k,v>[] table; static class Node<k,v> implements Map.Entry<k,v> { final int hash; final K key; V value; // 链表 Node<k,v> next; .... } ..... } 存储结构主要是数组加链表,像下面的图。 2. HashMap 的 put() 在 Java 8 中 HashMap 的 put 方法如下,我已经详细注释了重要代码。 public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } // 计算哈希值 与(&)、非(~)、或(|)、异或(^) static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); } final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<k,v>[] tab; Node<k,v> p; int n, i; // 如果数组为空,进行 resize() 初始化 if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; // 如果计算的位置上Node不存在,直接创建节点插入 if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { // 如果计算的位置上Node 存在,链表处理 Node<k,v> e; K k; // 如果 hash 值,k 值完全相同,直接覆盖 if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k)))) e = p; // 如果 index 位置元素已经存在,且是红黑树 else if (p instanceof TreeNode) e = ((TreeNode<k,v>)p).putTreeVal(this, tab, hash, key, value); else { // 如果这次要放入的值不存在 for (int binCount = 0; ; ++binCount) { // 尾插法 if ((e = p.next) == null) { // 找到节点链表中next为空的节点,创建新的节点插入 p.next = newNode(hash, key, value, null); // 如果节点链表中数量超过TREEIFY_THRESHOLD(8)个,转化为红黑树 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } // 如果节点链表中有发现已有相同key if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } // 如果节点 e 有值,放入数组 table[] if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; // 当前大小大于临界大小,扩容 if (++size > threshold) resize(); afterNodeInsertion(evict); return null; } 举个例子,如果 put 的 key 为字母 a,当前 HashMap 容量是初始容量 16,计算出位置是 1。 # int hash = key.hashCode() # hash = hash ^ (hash >>> 16) # 公式 index = (n - 1) & hash // n 是容量 hash HEX(97) = 0110 0001 n-1 HEX(15) = 0000 1111 -------------------------- 结果 = 0000 0001 # 计算得到位置是 1 总结 HashMap put 过程。 计算 key 的 hash 值。 计算方式是 (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); 检查当前数组是否为空,为空需要进行初始化,初始化容量是 16 ,负载因子默认 0.75。 计算 key 在数组中的坐标。 计算方式:(容量 - 1) & hash. 因为容量总是2的次方,所以-1的值的二进制总是全1。方便与 hash 值进行与运算。 如果计算出的坐标元素为空,创建节点加入,put 结束。 如果当前数组容量大于负载因子设置的容量,进行扩容。 如果计算出的坐标元素有值。 如果坐标上的元素值和要加入的值 key 完全一样,覆盖原有值。 如果坐标上的元素是红黑树,把要加入的值和 key 加入到红黑树。 如果坐标上的元素和要加入的元素不同(尾插法增加)。 如果 next 节点为空,把要加入的值和 key 加入 next 节点。 如果 next 节点不为空,循环查看 next 节点。 如果发现有 next 节点的 key 和要加入的 key 一样,对应的值替换为新值。 如果循环 next 节点查找超过8层还不为空,把这个位置元素转换为红黑树。 3. HashMap 的 get() 在 Java 8 中 get 方法源码如下,我已经做了注释说明。 public V get(Object key) { Node<k,v> e; return (e = getNode(hash(key), key)) == null ? null : e.value; } final Node<k,v> getNode(int hash, Object key) { Node<k,v>[] tab; Node<k,v> first, e; int n; K k; // 只有在存储数组已经存在的情况下进入这个 if if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) { // first 是获取的坐标上元素 if (first.hash == hash && // always check first node ((k = first.key) == key || (key != null && key.equals(k)))) // key 相同,说明first是想要的元素,返回 return first; if ((e = first.next) != null) { if (first instanceof TreeNode) // 如果是红黑树,从红黑树中查找结果 return ((TreeNode<k,v>)first).getTreeNode(hash, key); do { // 循环遍历查找 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } while ((e = e.next) != null); } } return null; } get 方法流程总结。 计算 key 的 hash 值。 如果存储数组不为空,且计算得到的位置上的元素不为空。继续,否则,返回 Null。 如果获取到的元素的 key 值相等,说明查找到了,返回元素。 如果获取到的元素的 key 值不相等,查找 next 节点的元素。 如果元素是红黑树,在红黑树中查找。 不是红黑树,遍历 next 节点查找,找到则返回。 4. HashMap 的 Hash 规则 计算 hash 值 int hash = key.hashCode()。 与或上 hash 值无符号右移16 位。 hash = hash ^ (hash >>> 16)。 位置计算公式 index = (n - 1) & hash ,其中 n 是容量。 这里可能会有同学对 hash ^ (hash >>> 16) 有疑惑,很好奇为什么这里要拿 hash 值异或上 hash 值无符号右移 16 位呢?下面通过一个例子演示其中道理所在。 假设 hash 值是 0001 0100 1100 0010 0110 0001 0010 0000,当前容量是 16。 hash = 0001 0100 1100 0010 0110 0001 0010 0000 --- | 与或计算 hash >>> 16 = 0000 0000 0000 0000 0001 0100 1100 0010 --- ------------------------------------------------------ hash 结果 = 0001 0100 1100 0010 0111 0101 1110 0100 --- | & 与运算 容量 -1 = 0000 0000 0000 0000 0000 0000 0000 1111 --- ------------------------------------------------------ # 得到位置 = 0000 0000 0000 0000 0000 0000 0000 0100 得到位置是 4 如果又新增一个数据,得到 hash 值是 0100 0000 1110 0010 1010 0010 0001 0000 ,容量还是16,计算它的位置应该是什么呢? hash = 0100 0000 1110 0010 1010 0010 0001 0000 --- | 与或计算 hash >>> 16 = 0000 0000 0000 0000 0001 0100 1100 0010 --- ------------------------------------------------------ hash 结果 = 0100 0000 1110 0010 1011 0110 1101 0010 --- | & 与运算 容量 -1 = 0000 0000 0000 0000 0000 0000 0000 1111 --- ------------------------------------------------------ # 得到位置 = 0000 0000 0000 0000 0000 0000 0000 0010 得到位置是 2 上面两个例子,得到位置一个是 4,一个是 2,上面只是我随便输入的两个二进制数,那么这两个数如果不经过 hash ^ (hash >>> 16) 运算,位置会有什么变化呢? hash = 0001 0100 1100 0010 0110 0001 0010 0000 容量 -1 = 0000 0000 0000 0000 0000 0000 0000 1111 ------------------------------------------------------ 结果 = 0000 0000 0000 0000 0000 0000 0000 0000 # 得到位置是 0 hash = 0100 0000 1110 0010 1010 0010 0001 0000 容量 -1 = 0000 0000 0000 0000 0000 0000 0000 1111 ------------------------------------------------------ 结果 = 0000 0000 0000 0000 0000 0000 0000 0000 # 得到位置是 0 可以发现位置都是 0 ,冲突概率提高了。可见 hash ^ (hash >>> 16) 让数据的 hash 值的高 16 位与低 16 位进行与或混合,可以减少低位相同时数据插入冲突的概率。 5. HashMap 的初始化大小 初始化大小是 16,为什么是 16 呢? 这可能是因为每次扩容都是 2 倍。而选择 2 的次方值 16 作为初始容量,有利于扩容时重新 Hash 计算位置。为什么是 16 我想是一个经验值,理论上说只要是 2 的次方都没有问题。 6. HashMap 的扩容方式 负载因子是多少?负载因子是 0.75。 扩容方式是什么?看源码说明。 /** * Initializes or doubles table size. If null, allocates in * accord with initial capacity target held in field threshold. * Otherwise, because we are using power-of-two expansion, the * elements from each bin must either stay at same index, or move * with a power of two offset in the new table. * * @return the table */ final Node<k,v>[] resize() { Node<k,v>[] oldTab = table; // 现有容量 int oldCap = (oldTab == null) ? 0 : oldTab.length; // 现有扩容阀值 int oldThr = threshold; int newCap, newThr = 0; if (oldCap > 0) { // 如果当前长度已经大于最大容量。结束扩容 if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } // 如果扩大两倍之后小于最大容量,且现有容量大于等于初始容量,就扩大两倍 else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) // 扩容阀值扩大为两倍 newThr = oldThr << 1; // double threshold } // 当前容量 = 0 ,但是当前记录容量 > 0 ,获取当前记录容量。 else if (oldThr > 0) // initial capacity was placed in threshold // 进入这里,说明是通过指定容量和负载因子的构造函数 newCap = oldThr; else { // zero initial threshold signifies using defaults // 进入这里说明是通过无参构造 // 新的容量 newCap = DEFAULT_INITIAL_CAPACITY; // 新的阀值 newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } if (newThr == 0) { float ft = (float)newCap * loadFactor; // 计算扩容阀值 newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } threshold = newThr; @SuppressWarnings({"rawtypes","unchecked"}) Node<k,v>[] newTab = (Node<k,v>[])new Node[newCap]; table = newTab; // 如果 oldTab != null,说明是扩容,否则是初始化,直接返回 if (oldTab != null) { for (int j = 0; j < oldCap; ++j) { Node<k,v> e; if ((e = oldTab[j]) != null) { oldTab[j] = null; // 如果当前元素 next节点没有元素,当前元素重新计算位置直接放入 if (e.next == null) newTab[e.hash & (newCap - 1)] = e; else if (e instanceof TreeNode) // 如果当前节点是红黑树 ((TreeNode<k,v>)e).split(this, newTab, j, oldCap); else { // preserve order Node<k,v> loHead = null, loTail = null; Node<k,v> hiHead = null, hiTail = null; Node<k,v> next; do { next = e.next; // == 0 ,位置不变 if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } // e.hash & oldCap != 0 ,位置变为:位置+扩容前容量 else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } } return newTab; } 扩容时候怎么重新确定元素在数组中的位置,我们看到是由 if ((e.hash & oldCap) == 0) 确定的。 hash HEX(97) = 0110 0001 n HEX(16) = 0001 0000 -------------------------- 结果 = 0000 0000 # e.hash & oldCap = 0 计算得到位置还是扩容前位置 hash HEX(17) = 0001 0001 n HEX(16) = 0001 0000 -------------------------- 结果 = 0001 0000 # e.hash & oldCap != 0 计算得到位置是扩容前位置+扩容前容量 通过上面的分析也可以看出,只有在每次容量都是2的次方的情况下才能使用 if ((e.hash & oldCap) == 0) 判断扩容后的位置。 7. HashMap 中的红黑树 HashMap 在 Java 8 中的实现增加了红黑树,当链表节点达到 8 个的时候,会把链表转换成红黑树,低于 6 个的时候,会退回链表。究其原因是因为当节点过多时,使用红黑树可以更高效的查找到节点。毕竟红黑树是一种二叉查找树。 节点个数是多少的时候,链表会转变成红黑树。 链表节点个数大于等于 8 时,链表会转换成树结构。 节点个数是多少的时候,红黑树会退回链表。 节点个数小于等于 6 时,树会转变成链表。 为什么转变条件 8 和 6 有一个差值。 如果没有差值,都是 8 ,那么如果频繁的插入删除元素,链表个数又刚好在 8 徘徊,那么就会频繁的发生链表转树,树转链表。 8. 为啥容量都是2的幂? 容量是2的幂时,key 的 hash 值然后 & (容量-1) 确定位置时碰撞概率会比较低,因为容量为 2 的幂时,减 1 之后的二进制数为全1,这样与运算的结果就等于 hash值后面与 1 进行与运算的几位。 下面是个例子。 hash HEX(97) = 0110 0001 n-1 HEX(15) = 0000 1111 -------------------------- 结果 = 0000 0001 # 计算得到位置是 1 hash HEX(99) = 0110 0011 n-1 HEX(15) = 0000 1111 -------------------------- 结果 = 0000 0011 # 计算得到位置是 3 hash HEX(101) = 0110 0101 n-1 HEX(15) = 0000 1111 -------------------------- 结果 = 0000 0101 # 计算得到位置是 5 如果是其他的容量值,假设是9,进行与运算结果碰撞的概率就比较大。 hash HEX(97) = 0110 0001 n-1 HEX(09) = 0000 1001 -------------------------- 结果 = 0000 0001 # 计算得到位置是 1 hash HEX(99) = 0110 0011 n-1 HEX(09) = 0000 1001 -------------------------- 结果 = 0000 0001 # 计算得到位置是 1 hash HEX(101) = 0110 0101 n-1 HEX(09) = 0000 1001 -------------------------- 结果 = 0000 0001 # 计算得到位置是 1 另外,每次都是 2 的幂也可以让 HashMap 扩容时可以方便的重新计算位置。 hash HEX(97) = 0110 0001 n-1 HEX(15) = 0000 1111 -------------------------- 结果 = 0000 0001 # 计算得到位置是 1 hash HEX(97) = 0110 0001 n-1 HEX(31) = 0001 1111 -------------------------- 结果 = 0000 0001 # 计算得到位置是 1 9. 快速失败(fail—fast) HashMap 遍历使用的是一种快速失败机制,它是 Java 非安全集合中的一种普遍机制,这种机制可以让集合在遍历时,如果有线程对集合进行了修改、删除、增加操作,会触发并发修改异常。 它的实现机制是在遍历前保存一份 modCount ,在每次获取下一个要遍历的元素时会对比当前的 modCount 和保存的 modCount 是否相等。 快速失败也可以看作是一种安全机制,这样在多线程操作不安全的集合时,由于快速失败的机制,会抛出异常。 10. 线程安全的 Map 使用 Collections.synchronizedMap(Map) 创建线程安全的 Map. 实现原理:有一个变量 final Object mutex; ,操作方法都加了这个 synchronized (mutex) 排它锁。 使用 Hashtable 使用 ConcurrentHashMap 最后的话 文章已经收录在 Github.com/niumoo/JavaNotes ,欢迎Star和指教。更有一线大厂面试点,Java程序员需要掌握的核心知识等文章,也整理了很多我的文字,欢迎 Star 和完善,希望我们一起变得优秀。 文章有帮助可以点个「赞」或「分享」,都是支持,我都喜欢! 文章每周持续更新,要实时关注我更新的文章以及分享的干货,可以关注「 未读代码 」公众号或者我的博客。