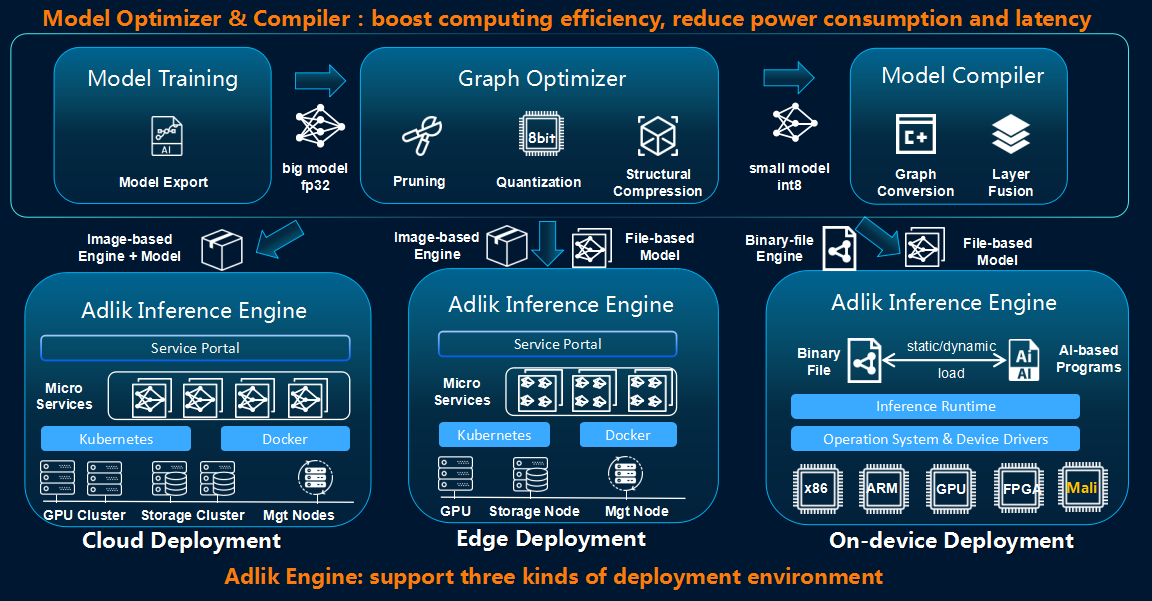
IPython 8.0 发布,Python 命令行交互工具
IPython 是 Python 的原生交互式 shell 的增强版,可以完成许多不同寻常的任务,比如帮助实现并行化计算;主要使用它提供的交互性帮助,比如代码着色、改进了的命令行回调、制表符完成、宏功能以及改进了的交互式帮助。 IPython8.0 酝酿了许久,主要对现有代码库和几个新功能进行了改进。新功能包括在 CLI 中使用 Black 重新格式化代码、ghost 建议以及突出错误节点的更好的回溯,从而使复杂的表达式更易于调试。 追溯改进 之前的错误回溯显示一个散列表(hash),用于编译 Python AST: In [1]: def foo(): ...: return 3 / 0 ...: In [2]: foo() --------------------------------------------------------------------------- ZeroDivisionError Traceback (most recent call last) <ipython-input-2-c19b6d9633cf> in <module> ----> 1 foo() <ipython-input-1-1595a74c32d5> in foo() 1 def foo(): ----> 2 return 3 / 0 3 ZeroDivisionError: division by zero 现在错误回溯的格式正确,会显示发生错误的单元格编号: In [1]: def foo(): ...: return 3 / 0 ...: Input In [2]: foo() --------------------------------------------------------------------------- ZeroDivisionError Traceback (most recent call last) input In [2], in <module> ----> 1 foo() Input In [1], in foo() 1 def foo(): ----> 2 return 3 / 0 ZeroDivisionError: division by zero 第二个回溯改进是 stack_data 包的集成;在回溯中提供更智能的信息;它会突出显示发生错误的 AST 节点,这有助于快速缩小错误范围,比如 def foo(i): x = [[[0]]] return x[0][i][0] def bar(): return foo(0) + foo( 1 ) + foo(2) 调用 bar() 会在IndexError 的返回行上引发一个 foo,IPython 8.0 可以告诉你索引错误发生在哪里: IndexError Input In [2], in <module> ----> 1 bar() ^^^^^ Input In [1], in bar() 6 def bar(): ----> 7 return foo(0) + foo( ^^^^ 8 1 ^^^^^^^^ 9 ) + foo(2) ^^^^ Input In [1], in foo(i) 1 def foo(i): 2 x = [[[0]]] ----> 3 return x[0][i][0] ^^^^^^^ 用 ^ 标记的位置在终端会高亮显示。 第三个回溯改进是最谨慎的,但对生产力有很大影响,在回溯中的文件名后面附加一个冒号:: 和行号: ZeroDivisionError Traceback (most recent call last) File ~/error.py:4, in <module> 1 def f(): 2 1/0 ----> 4 f() File ~/error.py:2, in f() 1 def f(): ----> 2 1/0 许多终端和编辑器具有的集成功能,允许在使用此语法时直接跳转到错误相关的文件/行。 自动建议 Ptpython 允许用户在 ptpython/config.py 中启用自动建议功能,此功能包含丰富的代码补全建议,如图: 目前,自动建议仅在 emacs 或 vi 插入编辑模式中显示: ctrl e、ctrl f 和 alt f 快捷键默认在 emacs 模式下工作。 要在 vi 插入模式下使用这些快捷键,必须在 config.py 中创建自定义键绑定。 使用“?”和"??"查看对象信息 在 IPDB 中,现在可以使用“?”和”? ?“来显示对象的信息,在使用 IPython 提示符时也可如此操作: ipdb> partial? Init signature: partial(self, /, *args, **kwargs) Docstring: partial(func, *args, **keywords) - new function with partial application of the given arguments and keywords. File: ~/.pyenv/versions/3.8.6/lib/python3.8/functools.py Type: type Subclasses: 历史范围全局功能 之前使用 %history功能时,用户可以指定会话和行的范围,例如: ~8/1-~6/5 # see history from the first line of 8 sessions ago, # to the fifth line of 6 sessions ago.`` 或者可以指定全局模式(global): -g <pattern> # glob ALL history for the specified pattern. 但无法同时指定两者,如果用户确实指定了范围和全局模式,则将使用 glob 模式(通配所有历史记录),并且将忽略范围。 现在此功能获得了增强,如果用户同时指定范围和 glob 模式,则 glob 模式将应用于指定的历史范围。 此外,Ipython 8.0 还取消了对 Python 3.7 的支持,仅支持 3.8 以上版本。有关Ipython 8.0 的更多新功能,可在发布页面查看。