【Python学习 】Python获取命令行参数的方法
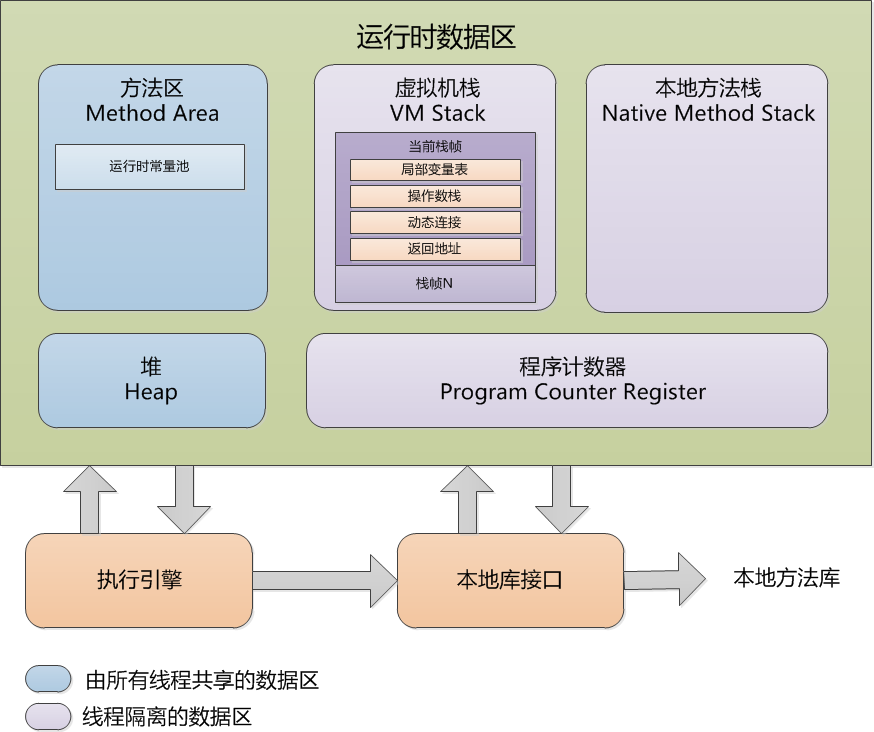
背景 最近编写一个python程序的时候,需要去获取python命令行的参数,因此这里记录下如何获取命令行参数的方法。 一、sys 模块 在 Python 中,sys 模块是一个非常常用且十分重要的模块,通过模块中的 sys.argv 就可以访问到所有的命令行参数,它的返回值是包含所有命令行参数的列表(list), 参数个数: len(sys.argv) 脚本名: sys.argv[0] 参数1: sys.argv[1] 参数2: sys.argv[2] 下面我们通过程序来说明它的用法: #!/usr/bin/python # -*- coding: UTF-8 -*- import sys def main(): """ 通过sys模块来识别参数demo, http://blog.csdn.net/ouyang_peng/ """ print('参数个数为:', len(sys.argv), '个参数。') print('参数列表:', str(sys.argv)) print('脚本名为:', sys.argv[0]) for i in range(1, len(sys.argv)): print('参数 %s 为:%s' % (i, sys.argv[i])) if __name__ == "__main__": main() 下面我们通过命令行来运行该python脚本 1.1、不传递参数 我们执行命令 python test.py (venv) C:\Code Python\SMTP>python test.py 参数个数为: 1 个参数。 参数列表: ['test.py'] 脚本名为: test.py 识别到的参数只有一个,就是脚本名 test.py 1.2、传递多个参数 当我们传递参数的时候, 我们执行命令 python test.py ouyangpeng csdn (venv) C:\Code Python\SMTP>python test.py ouyangpeng csdn 参数个数为: 3 个参数。 参数列表: ['test.py', 'ouyangpeng', 'csdn'] 脚本名为: test.py 参数 1 为:ouyangpeng 参数 2 为:csdn (venv) C:\Code Python\SMTP> 识别到的参数有3个,分别是脚本名 test.py,参数 1 为:ouyangpeng,参数 2 为:csdn 1.3、传递多个参数和命令行选项 当我们传递命令行选项和参数的时候, 我们执行命令 python test.py ouyangpeng csdn -u username -p password (venv) C:\Code Python\SMTP>python test.py ouyangpeng csdn -u username -p password 参数个数为: 7 个参数。 参数列表: ['test.py', 'ouyangpeng', 'csdn', '-u', 'username', '-p', 'password'] 脚本名为: test.py 参数 1 为:ouyangpeng 参数 2 为:csdn 参数 3 为:-u 参数 4 为:username 参数 5 为:-p 参数 6 为:password 识别到的参数有6个,分别是脚本名 test.py,参数 1 为:ouyangpeng,参数 2 为:csdn,命令行选项 -u 和 -p 都被识别为参数了,这样不合理,因此我们需要引入getopt模块来识别命令行选项。 二、getopt模块 getopt模块是专门处理命令行参数的模块,用于获取命令行选项和参数,也就是sys.argv。命令行选项使得程序的参数更加灵活。支持短选项模式(-)和长选项模式(–)。 该模块提供了两个方法及一个异常处理来解析命令行参数。 2.1 getopt.getopt 方法 getopt.getopt 方法用于解析命令行参数列表,语法格式如下: getopt.getopt(args, options[, long_options]) 方法参数说明: args: 要解析的命令行参数列表。 options: 以字符串的格式定义,options后的冒号(:)表示该选项必须有附加的参数,不带冒号表示该选项不附加参数。 long_options: 以列表的格式定义,long_options 后的等号(=)表示如果设置该选项,必须有附加的参数,否则就不附加参数。 该方法返回值由两个元素组成: 第一个是 (option, value) 元组的列表。 第二个是参数列表,包含那些没有’-‘或’–’的参数。 2.1 Exception getopt.GetoptError 在没有找到参数列表,或选项的需要的参数为空时会触发该异常。 异常的参数是一个字符串,表示错误的原因。属性 msg 和 opt 为相关选项的错误信息。 2.3 实例 了解了 sys 模块和 getopt 模块,我们就可以来自己编写一个带有命令行的程序并且在该程序中,我们还使用了 getopt.GetoptError 来进行异常处理。代码如下: #!/usr/bin/python # -*- coding: UTF-8 -*- import sys import getopt def main(argv): """ 通过 getopt模块 来识别参数demo, http://blog.csdn.net/ouyang_peng/ """ username = "" password = "" try: """ options, args = getopt.getopt(args, shortopts, longopts=[]) 参数args:一般是sys.argv[1:]。过滤掉sys.argv[0],它是执行脚本的名字,不算做命令行参数。 参数shortopts:短格式分析串。例如:"hp:i:",h后面没有冒号,表示后面不带参数;p和i后面带有冒号,表示后面带参数。 参数longopts:长格式分析串列表。例如:["help", "ip=", "port="],help后面没有等号,表示后面不带参数;ip和port后面带冒号,表示后面带参数。 返回值options是以元组为元素的列表,每个元组的形式为:(选项串, 附加参数),如:('-i', '192.168.0.1') 返回值args是个列表,其中的元素是那些不含'-'或'--'的参数。 """ opts, args = getopt.getopt(argv, "hu:p:", ["help", "username=", "password="]) except getopt.GetoptError: print('Error: test_arg.py -u <username> -p <password>') print(' or: test_arg.py --username=<username> --password=<password>') sys.exit(2) # 处理 返回值options是以元组为元素的列表。 for opt, arg in opts: if opt in ("-h", "--help"): print('test_arg.py -u <username> -p <password>') print('or: test_arg.py --username=<username> --password=<password>') sys.exit() elif opt in ("-u", "--username"): username = arg elif opt in ("-p", "--password"): password = arg print('username为:', username) print('password为:', password) # 打印 返回值args列表,即其中的元素是那些不含'-'或'--'的参数。 for i in range(0, len(args)): print('参数 %s 为:%s' % (i + 1, args[i])) if __name__ == "__main__": # sys.argv[1:]为要处理的参数列表,sys.argv[0]为脚本名,所以用sys.argv[1:]过滤掉脚本名。 main(sys.argv[1:]) 2.4 运行结果 2.4.1、不传递参数 当我们不传递参数的时候, 我们执行命令 python test_arg.py (venv) C:\Code Python\SMTP>python test_arg.py username为: password为: (venv) C:\Code Python\SMTP> 2.4.2、使用短格式选项,不传递参数 当我们使用短格式选项,不传递参数的时候, 我们执行命令 python test_arg.py -h (venv) C:\Code Python\SMTP>python test_arg.py -h test_arg.py -u <username> -p <password> or: test_arg.py --username=<username> --password=<password> 2.4.3、使用长格式选项,不传递参数 当我们使用长格式选项,不传递参数的时候, 我们执行命令 python test_arg.py --help (venv) C:\Code Python\SMTP>python test_arg.py --help test_arg.py -u <username> -p <password> or: test_arg.py --username=<username> --password=<password> (venv) C:\Code Python\SMTP> 2.4.4、使用短格式选项,传递参数 当我们使用短格式选项,传递参数的时候, 我们执行命令 python test_arg.py -u ouyangpeng -p csdn (venv) C:\Code Python\SMTP>python test_arg.py -u ouyangpeng -p csdn username为: ouyangpeng password为: csdn (venv) C:\Code Python\SMTP> 2.4.5、使用长格式选项,传递参数 当我们使用长格式选项,传递参数的时候, 我们执行命令 python test_arg.py --username=ouyangpeng --password=csdn (venv) C:\Code Python\SMTP>python test_arg.py --username=ouyangpeng --password=csdn username为: ouyangpeng password为: csdn (venv) C:\Code Python\SMTP> 2.4.6、使用长短混合格式选项,传递参数 当我们使用长短混合格式选项,传递参数的时候, 我们执行命令 python test_arg.py -u ouyangpeng --password=csdn (venv) C:\Code Python\SMTP>python test_arg.py -u ouyangpeng --password=csdn username为: ouyangpeng password为: csdn (venv) C:\Code Python\SMTP> 2.4.7、使用格式选项,传递部分参数 当我们使用长短混合格式选项,传递参数的时候, 我们执行命令 python test_arg.py -u ouyangpeng (venv) C:\Code Python\SMTP>python test_arg.py -u ouyangpeng username为: ouyangpeng password为: (venv) C:\Code Python\SMTP> 2.4.8、传递错误的选项参数 当我们使用错误的格式选项传递参数的时候, 我们执行命令 python test_arg.py -e,-e选项不正确 (venv) C:\Code Python\SMTP>python test_arg.py -e Error: test_arg.py -u <username> -p <password> or: test_arg.py --username=<username> --password=<password> (venv) C:\Code Python\SMTP> 2.4.9、传递选项参数以及不带选项的参数 当我们传递选项参数以及不带选项的参数的时候, 我们执行命令 python test_arg.py -u ouyangpeng --password=csdn arg1 arg2 arg3 arg4 (venv) C:\Code Python\SMTP>python test_arg.py -u ouyangpeng --password=csdn arg1 arg2 arg3 arg4 username为: ouyangpeng password为: csdn 参数 1 为:arg1 参数 2 为:arg2 参数 3 为:arg3 参数 4 为:arg4 (venv) C:\Code Python\SMTP> 作者:欧阳鹏 欢迎转载,与人分享是进步的源泉! 转载请保留原文地址:http://blog.csdn.net/ouyang_peng/article/details/79390920 如果觉得本文对您有所帮助,欢迎您扫码下图所示的支付宝和微信支付二维码对本文进行随意打赏。您的支持将鼓励我继续创作!