笔记:C#和C++常见容器整合
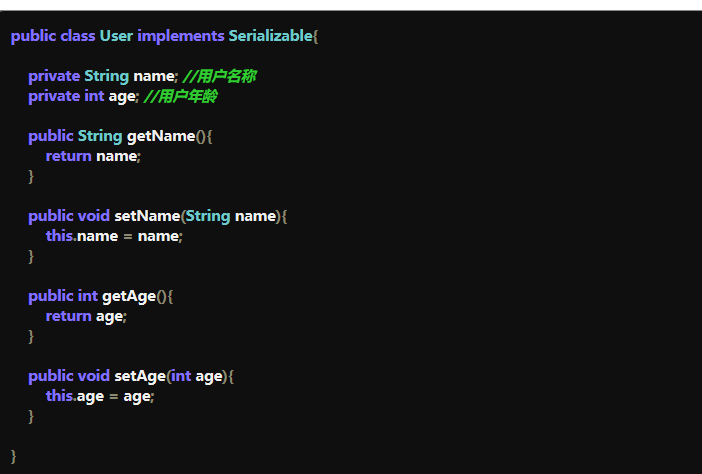
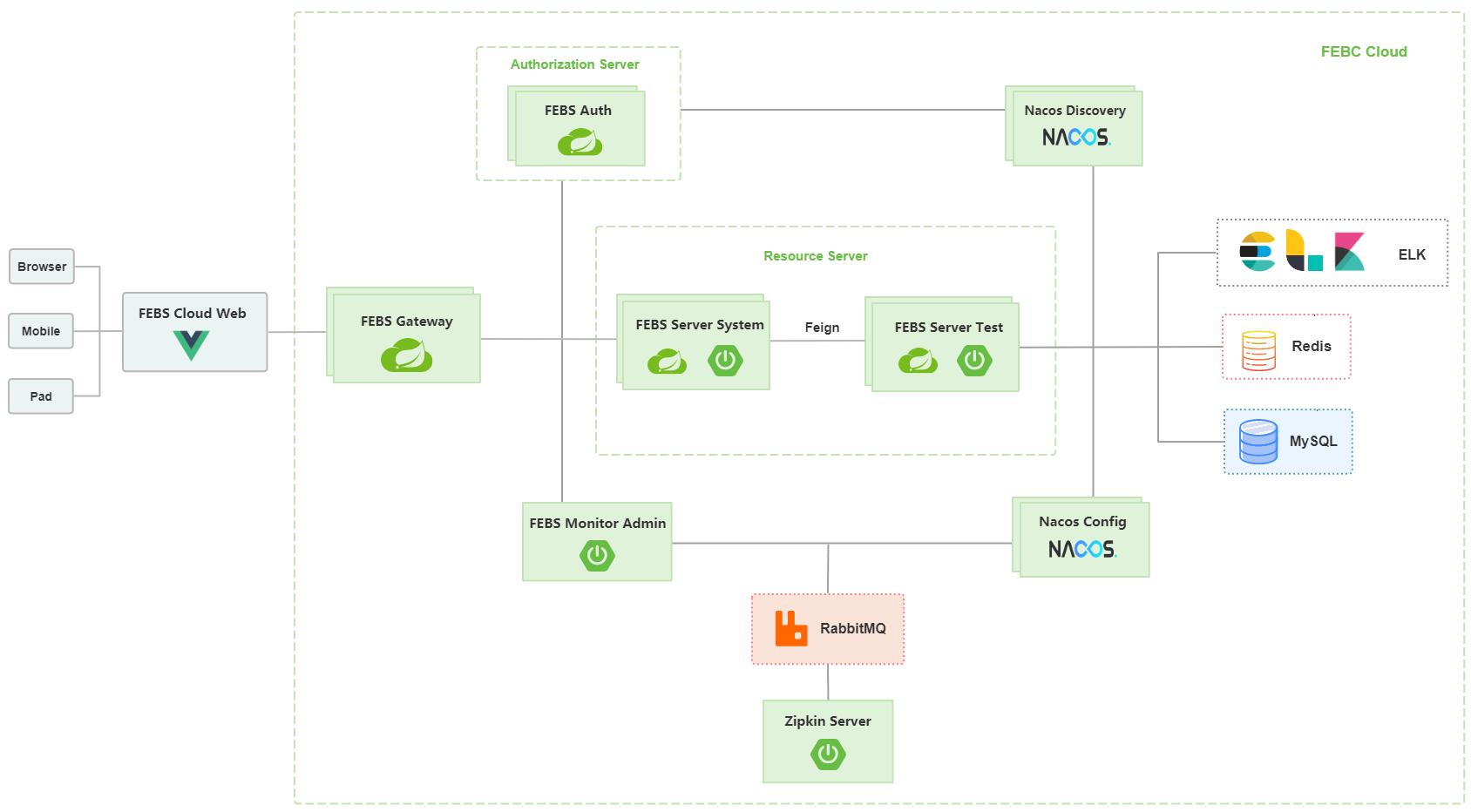
前言 有一段时间未使用c#/c++,因此写个合集用来回忆常用容器,也方便以后复习记忆 C#常见容器 Array 【数组】 简单的数组集合特点:内存中连续存储,索引快,赋值修改也快。缺点:需要事先声明数组长度,插值复杂。 String[] array = new String[5]; array[0] = '1'; ArrayList 【数组列表】 特点: 无需像Array需要初始长度,可以动态增加。 底层是Array,但继承了List接口 可以存储不同类型数据,所有元素视为object,也因此会出现类型不匹配,即不是类型安全。在拆箱操作时,性能消耗大。 ArrayList Alist = new Arraylist(); Alist.add('there') Alist.add(2333) List< T > 泛型 可以自定义list中元素的结构 public class TeamMate { public string name; public int age; public int groupNum; public override string ToString() { return "name=" + name + ",age=" + age + ",groupNum=" + groupNum; } } static void Main(string[] args) { List<TeamMate> list = new List<TeamMate>(); list.Add(new TeamMate { name = "Tom", age = 20, groupNum = 12 }); list.Add(new TeamMate { name = "Jerry", age = 22, groupNum = 13 }); foreach(Person p in list) { Console.WriteLine(p.ToString()); } } LinkedList< T > 【双向链表】 LinkedList< T >集合类没有非泛型类的版本,相当于C++中的list,内部实现是双链表 优点:如果要插入一个元素到链表的中间位置,会非常的快,原因:如果插入,只需要修改上一个元素的Next与下一个元素的Previous的引用则可。而像ArrayList数组列表中,如果插入,需要移动其后的所有元素。缺点:链表只能是一个接着一个的访问,这样就要用较长的时间来查找定位位于链表中间的元素。 因此从时间复杂度上,要在第K个位置插入一个元素,无论是ArrayList还是LinkedList的时间复杂度都为O(n)+O(1)=O(n)其中数组列表查找时间为O(1),但由于要将后续元素向后移动,则插入时间为O(n);而链表查找时间为O(n),但插入时间为O(1)。 将 List.Add方法和LinkedList的Add方法相比较,真正的性能差别不在于Add操作,而在LinkedList在给GC(垃圾回收机制)的压力上。一个List本质上是将其数据保存在一个堆栈的数组上,而LinkedList是将其所有节点保存在一系列堆栈上。这就使得GC需要更多地管理堆栈上LinkedList的节点对象。 LinkedListNode被LinkedList类包含,用LinkedListNode类,可以获得元素的上一个与下一个元素的引用。 LinkedList<int> list = new LinkedList<int>(); list.AddFirst(2); list.AddFirst(1); list.AddLast(4); list.AddLast(5); 此时链表结构为:1 2 4 5 LinkedListNode<int> NewList = list.Find(4); //4节点的位置 list.AddBefore(NewList, 3); //在4前增加3 此时链表结构为:1 2 3 4 5 HashTable【哈希表】 哈希表是通过key-value形式来存取数据的,相同存储形式的还有字典Dictionary,由于存储对象都是object,因而可以满足任意形式的键值对,但也因此有装箱和拆箱的性能消耗。 特点:当前HashTable中的被占用空间达到一个百分比的时候就将该空间自动扩容,在.net中这个百分比是72%,也叫.net中HashTable的填充因子为0.72。 构造哈希表 Hashtable table = new Hashtable(); table.Add("Name", "Tom"); table.Add("Age", 20); 遍历哈希表 Hashtable table = new Hashtable(); table.Add("Name", "Tom"); table.Add("Age", 20); foreach(DictionaryEntry entry in table) { Console.Write(entry.Key + ":"); Console.WriteLine(entry.Value); } Dictionary< T >【字典】(HashTable的泛型) 相当于C++中的map。只不过map的内部实现是红黑树,Dictionary的内部实现是哈希表,是类型安全的容器。在单线程的时候使用Dictionary更好,多线程的时候使用HashTable更好。 class Person { public string name; public int age; public override string ToString() { return "name=" + name + ",age=" + age; } } class Program { static void Main(string[] args) { Dictionary<string, Person> dictionary = new Dictionary<string, Person>(); Person person1 = new Person() { name = "Tom", age = 20 }; Person person2 = new Person() { name = "Jerry", age = 21}; dictionary.Add("学生1", person1); dictionary.Add("学生2", person2); foreach(KeyValuePair<string, Person> pair in dictionary) { Console.Write(pair.Key + ":"); Console.WriteLine(pair.Value.ToString()); } } } //只取Key值 foreach (string key in dictionary.Keys) { Console.WriteLine(key); } //只取value foreach (Person person in dictionary.Values) { Console.WriteLine(person); } HashSet< T > 特点: 一组不包含重复元素的集合 用O(n)的space来换取O(n)的时间,也就是查找元素的时间是O(1) HashSet<string> set = new HashSet<string>(); set.Add("Tom"); set.Add("Jerry"); set.Add("Tom"); foreach(var n in set) { Console.WriteLine(n); } 上述集合元素中Tom有2个,是重复值,那么输出HashSet结果就只显示一个,这就是不显示重复值的功能。 Queue【队列】 特点:先进先出的对象集合当需要对各项进行先进先出的访问时,则使用队列。当在列表中添加一项,称为入队,当从列表中移除一项时,称为出队。 Queue q = new Queue(); //入队操作 q.Enqueue("A"); q.Enqueue("B"); q.Enqueue("C"); //出队操作 q.Dequeue() Queue< T >【泛型队列】 class Person { public string name; public int age; public override string ToString() { return "name=" + name + ",age=" + age; } } class Program { static void Main(string[] args) { Person person1 = new Person() { name = "Tom", age = 20}; Person person2 = new Person() { name = "Jerry", age = 20 }; Queue<Person> q = new Queue<Person>(); q.Enqueue(person1); q.Enqueue(person2); Console.WriteLine(q.Dequeue()); } } Stack【栈】 特点:后进先出的对象集合。当需要对各项进行后进先出的访问时,则使用栈。当在列表中添加一项,称为推入元素,当从列表中移除一项时,称为弹出元素。 Stack st = new Stack(); //入栈 st.Push("A"); st.Push("B"); //出栈 st.Pop() C++常见容器 转载 C++ STL的实现:1.vector 底层数据结构为数组,支持快速随机访问 2.list 底层数据结构为双向链表,支持快速增删 3.deque 底层数据结构为一个中央控制器和多个缓冲区,支持首尾(中间不能)快速增删,也支持随机访问注:deque是一个双端队列(double-ended queue),也是在堆中保存内容的.它的保存形式如下:[堆1] --> [堆2] -->[堆3] --> ...每个堆保存好几个元素,然后堆和堆之间有指针指向,看起来像是list和vector的结合品4.stack 底层一般用list或deque实现,封闭头部即可,不用vector的原因应该是容量大小有限制,扩容耗时 5.queue 底层一般用list或deque实现,封闭头部即可,不用vector的原因应该是容量大小有限制,扩容耗时(stack和queue其实是适配器,而不叫容器,因为是对容器的再封装) 6.priority_queue 的底层数据结构一般为vector为底层容器,堆heap为处理规则来管理底层容器实现 7.set 底层数据结构为红黑树,有序,不重复 8.multiset 底层数据结构为红黑树,有序,可重复 9.map 底层数据结构为红黑树,有序,不重复 10.multimap 底层数据结构为红黑树,有序,可重复 11.hash_set 底层数据结构为hash表,无序,不重复 12.hash_multiset 底层数据结构为hash表,无序,可重复 13.hash_map 底层数据结构为hash表,无序,不重复 14.hash_multimap 底层数据结构为hash表,无序,可重复 stl容器区别: vector list deque set map-底层实现 在STL中基本容器有: vector、list、deque、set、map set 和map都是无序的保存元素,只能通过它提供的接口对里面的元素进行访问 set:集合, 用来判断某一个元素是不是在一个组里面,使用的比较少map:映射,相当于字典,把一个值映射成另一个值,如果想创建字典的话使用它好了底层采用的是树型结构,多数使用平衡二叉树实现,查找某一值是常数时间,遍历起来效果也不错, 只是每次插入值的时候,会重新构成底层的平衡二叉树,效率有一定影响. vector、list、deque是有序容器 1.vector vector就是动态数组.它也是在堆中分配内存,元素连续存放,有保留内存,如果减少大小后,内存也不会释放.如果新值>当前大小时才会再分配内存. 它拥有一段连续的内存空间,并且起始地址不变,因此它能非常好的支持随即存取,即[]操作符,但由于它的内存空间是连续的,所以在中间进行插入和删除会造成内存块的拷贝,另外,当该数组后的内存空间不够时,需要重新申请一块足够大的内存并进行内存的拷贝。这些都大大影响了vector的效率。 对最后元素操作最快(在后面添加删除最快), 此时一般不需要移动内存,只有保留内存不够时才需要 对中间和开始处进行添加删除元素操作需要移动内存,如果你的元素是结构或是类,那么移动的同时还会进行构造和析构操作,所以性能不高 (最好将结构或类的指针放入vector中,而不是结构或类本身,这样可以避免移动时的构造与析构)。访问方面,对任何元素的访问都是O(1),也就是是常数的,所以vector常用来保存需要经常进行随机访问的内容,并且不需要经常对中间元素进行添加删除操作. 相比较可以看到vector的属性与string差不多,同样可以使用capacity看当前保留的内存,使用swap来减少它使用的内存. capacity()返回vector所能容纳的元素数量(在不重新分配内存的情况下) 总结需要经常随机访问请用vector 2.list list就是双向链表,元素也是在堆中存放,每个元素都是放在一块内存中,它的内存空间可以是不连续的,通过指针来进行数据的访问,这个特点使得它的随机存取变的非常没有效率,因此它没有提供[]操作符的重载。但由于链表的特点,它可以以很好的效率支持任意地方的删除和插入。 list没有空间预留习惯,所以每分配一个元素都会从内存中分配,每删除一个元素都会释放它占用的内存. list在哪里添加删除元素性能都很高,不需要移动内存,当然也不需要对每个元素都进行构造与析构了,所以常用来做随机操作容器.但是访问list里面的元素时就开始和最后访问最快访问其它元素都是O(n) ,所以如果需要经常随机访问的话,还是使用其它的好 总结如果你喜欢经常添加删除大对象的话,那么请使用list要保存的对象不大,构造与析构操作不复杂,那么可以使用vector代替list<指针>完全是性能最低的做法,这种情况下还是使用vector<指针>好,因为指针没有构造与析构,也不占用很大内存 3.deque deque是一个双端队列(double-ended queue),也是在堆中保存内容的.它的保存形式如下:[堆1]...[堆2]...[堆3]每个堆保存好几个元素,然后堆和堆之间有指针指向,看起来像是list和vector的结合品. 它支持[]操作符,也就是支持随即存取,可以让你在前面快速地添加删除元素,或是在后面快速地添加删除元素,然后还可以有比较高的随机访问速度,和vector的效率相差无几,它支持在两端的操作:push_back,push_front,pop_back,pop_front等,并且在两端操作上与list的效率也差不多。在标准库中vector和deque提供几乎相同的接口,在结构上它们的区别主要在于这两种容器在组织内存上不一样,deque是按页或块来分配存储器的,每页包含固定数目的元素.相反vector分配一段连续的内存,vector只是在序列的尾段插入元素时才有效率,而deque的分页组织方式即使在容器的前端也可以提供常数时间的insert和erase操作,而且在体积增长方面也比vector更具有效率 总结:vector是可以快速地在最后添加删除元素,并可以快速地访问任意元素list是可以快速地在所有地方添加删除元素,但是只能快速地访问最开始与最后的元素deque在开始和最后添加元素都一样快,并提供了随机访问方法,像vector一样使用[]访问任意元素,但是随机访问速度比不上vector快,因为它要内部处理堆跳转deque也有保留空间.另外,由于deque不要求连续空间,所以可以保存的元素比vector更大,这点也要注意一下.还有就是在前面和后面添加元素时都不需要移动其它块的元素,所以性能也很高。 因此在实际使用时,如何选择这三个容器中哪一个,应根据你的需要而定,一般应遵循下面的原则:1、如果你需要高效的随即存取,而不在乎插入和删除的效率,使用vector2、如果你需要大量的插入和删除,而不关心随即存取,则应使用list3、如果你需要随即存取,而且关心两端数据的插入和删除,则应使用deque。 c++部分的原文出处