一.大数据平台测试简述
大数据平台测试包括2部分:基础能力测试和性能测试
Ⅰ).基础能力测试
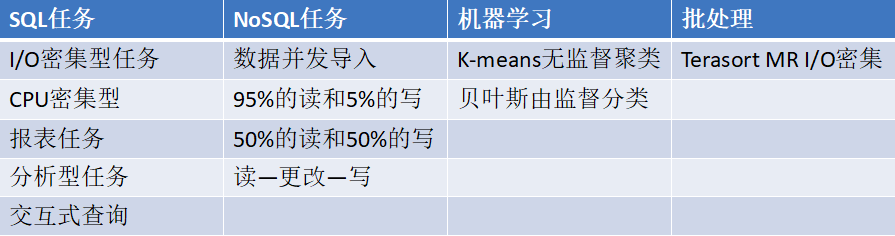
- 大数据平台的基本功能和数据的导入导出对SQL任务、NoSQL任务、机器学习、批处理任务的支持
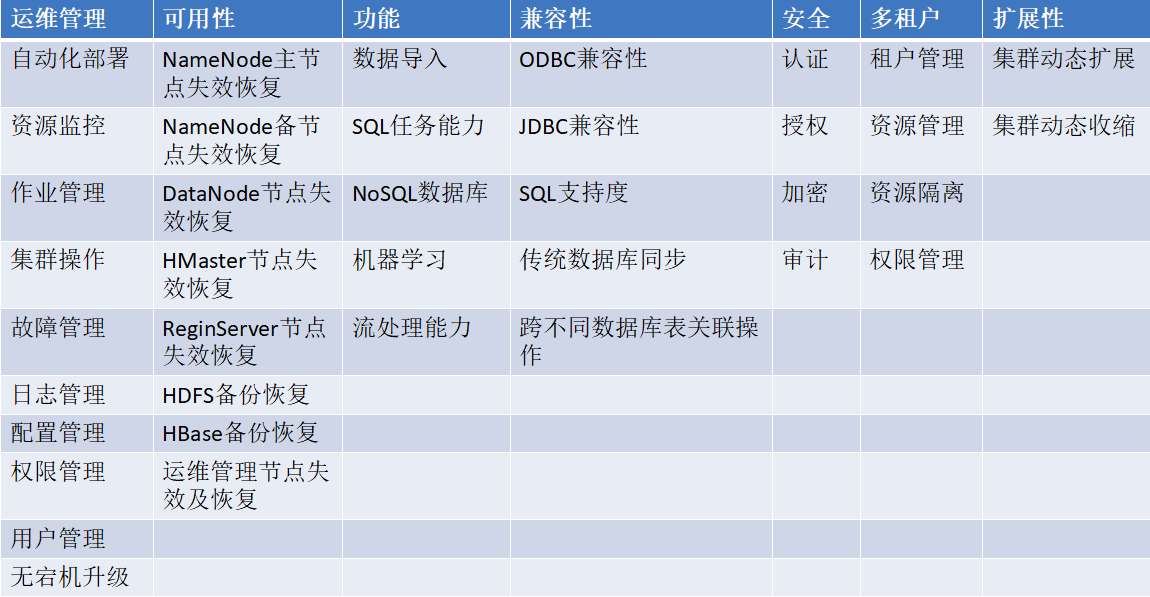
- 大数据平台是否能够通过界面的形式方便用户进行非运行维护,主要包括集群的安装、监控、配置、操作等
- 大数据平台是否能够提供基本的安全方案
- a).是否具备认证功能以防止恶意访问和攻击
- b).是否能够进行细粒度的权限管理
- c).是否能够提供审计和数据加密功能
- 大数据平台是否具备高可用的机制,防止机器的失效带来的任务失败以及数据丢失
- 大数据平台是否能够支持机器快速平滑地扩展和缩容时带来线性的计算能力
- 大数据平台是否能够支持多个调用接口以及对SQL语法的支持情况
- 大数据平台是否能够根据队列、用户的权重来细粒度地分配计算资源
Ⅱ).性能测试
- 基准测试:数据生成、负载选择和明确测试指标等内容
- 性能测试:基准测试之上的扩展
二.大数据平台测试流程
Ⅰ).数据生成
BDGS: 能够快速生成保持真实数据特性的文本、表和图数据的数据生成工具
BDGS构造方法
- a).数据筛选:选取代表性的真实数据集和相应的建模方法或工具
- b).原始数据处理:对真实数据采样并建模,提取数据特性
- c).数据生成:通过参数控制数据规模和并行度
- d).格式转化:根据负载的输入需求转换生成数据的格式
Ⅱ).负载选择
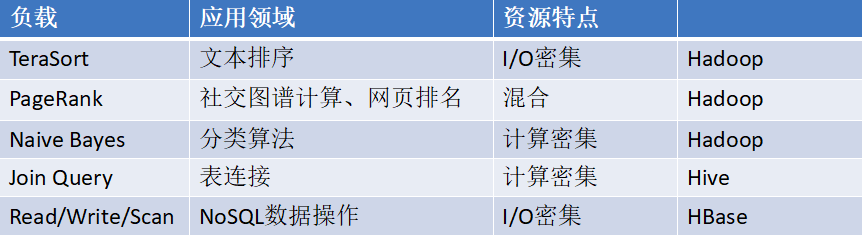
负载选择策略: 负载需覆盖大数据处理平台的主要组件即分布式计算框架、分布式文件系统和分布式存储的能力
![]()
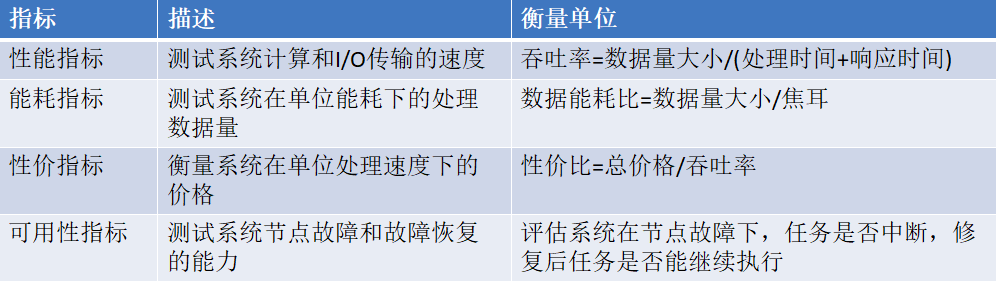
Ⅲ).测试指标
主要从性能、能耗、性价比和可用性4个维度来测试对比平台性能
![]()
三.大数据平台测试工具
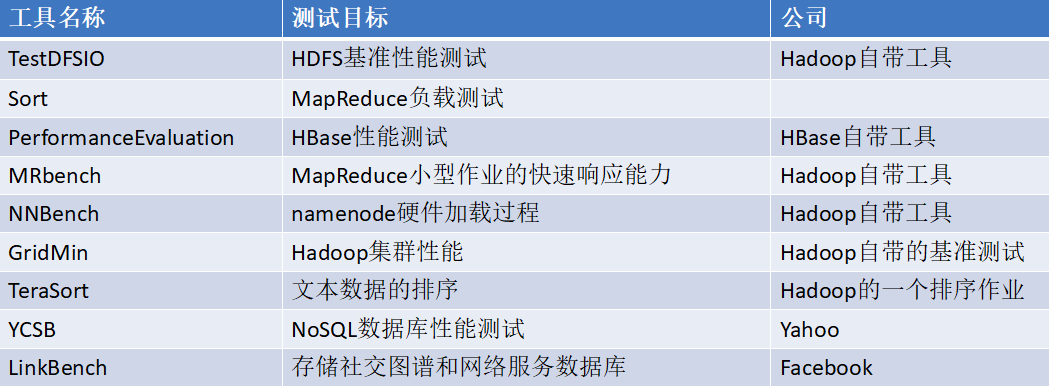
Ⅰ).平台单组件测试
测试应用单一、效率高、成本低,但无法全面衡量大数据平台性能
![]()
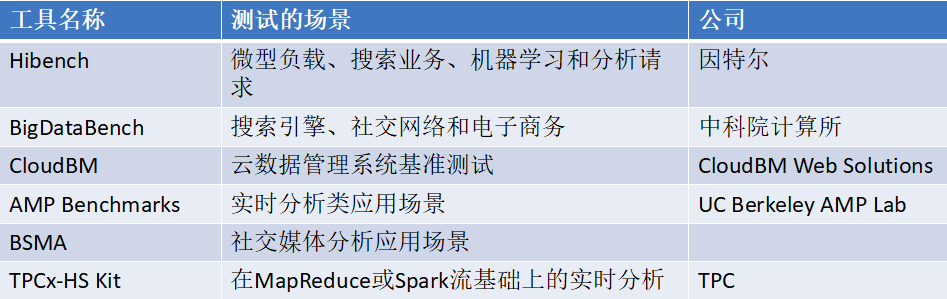
Ⅱ).综合平台测试
覆盖面广,可以较全面测试衡量大数据平台不同类型任务的性能,通用性好
![]()
- a).概念:是一个跨系统、体系结构、数据管理 3个领域的大数据基准测试开源程序集
- b).应用领域:搜索引擎、电子商务、社交网络、多媒体、生物信息
- c).负载类型:离线分析、交互式分析、在线服务、Nosql
- d).数据类型:结构化、半结构化、非结构化
- a).概念:是一个大数据基准测试套件,可帮助评估大数据框架的速度,吞吐量和系统资源利用率
- b).测试范围:HadoopBench、SparkBench、StormBench、FlinkBench、GearpumpBench、机器学习、网页搜索
- c).负载类型:实时场景、离线场景
- d).数据类型:结构化、半结构化
- e).功能模块:对于hive:(aggregation,scan,join)、排序(sort,TeraSort)、大数据基本算法(wordcount,pagerank,nutchindex)、机器学习算法(kmeans,bayes)、集群调度(sleep)、吞吐(dfsio)、5.0版本的流测试
- a).概念:第一个标准化的大数据基准测试,旨在对Hadoop集群进行压力测试
- b).囊括模块:HSGen数据生成器、HSDataCheck检查数据集和副本的符合性、HSSort数据排序、HSValidatate排序后的数据校验
- c).测试指标:性能、价格性能和可用性
- d).负载类型:实时场景、离线场景
- a).概念:基于Yahoo的YCSB的大数据性能测试工具
- b).测试场景:社交网络查询、热点查询、时间线查询
- c).负载类型:离线分析、Nosql
- d).测试指标:吞吐量、延时、可伸缩性
Ⅲ).应用领域端到端测试
可以与企业场景的实际业务场景结合,覆盖企业大数据业务的全流程模拟测试
![]()
- a).概念:于2016年2月被TPC委员会接受以后被命名为TPCx-BB,在此之前叫BigBench;TPCx-BB性能评估标准有两个,一是根据软硬件性能评估,二是根据软硬件性价比评估
- b).测试领域:零售商
- c).负载类型:离线分析
- d).数据类型:结构化、半结构化、非结构化
四.大数据平台测试用例
Ⅰ).平台基准测试用例
主要是从性能的角度衡量大数据平台,包括数据生成、负载选择和明确测试指标等内容
![]()
Ⅱ).平台性能测试用例
在基准测试的基础上扩展测试内容,增加SQL任务测试比重
![]()
Ⅲ).平台基础能力测试用例
![]()