JavaScript日期选择控件Kalendae
在线演示 本地下载
数据可视化是数据分析或机器学习项目中十分重要的一环。通常,你需要在项目初期进行探索性的数据分析(EDA),从而对数据有一定的了解,而且创建可视化确实可以使分析的任务更清晰、更容易理解,特别是对于大规模的高维数据集。在项目接近尾声时,以一种清晰、简洁而引人注目的方式展示最终结果也是非常重要的,让你的受众(通常是非技术人员的客户)能够理解。
读者可能阅读过我之前的文章「5 Quick and Easy Data Visualizations in Python with Code」,我通过那篇文章向大家介绍了 5 种基础的数据可视化方法:散点图、线图、直方图、条形图和箱形图。这些都是简单而强大的可视化方法,通过它们你可以对数据集有深刻的认识。在本文中,我们将看到另外 4 个数据可视化方法!本文对这些方法的介绍会更详细一些,可以在您阅读了上一篇文章中的基本方法之后接着使用,从而从数据中提取出更深入的信息。
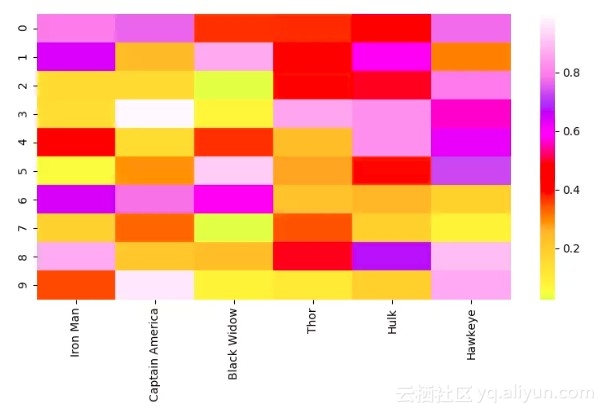
热力图
热力图(Heat Map)是数据的一种矩阵表示方法,其中每个矩阵元素的值通过一种颜色表示。不同的颜色代表不同的值,通过矩阵的索引将需要被对比的两项或两个特征关联在一起。热力图非常适合于展示多个特征变量之间的关系,因为你可以直接通过颜色知道该位置上的矩阵元素的大小。通过查看热力图中的其他点,你还可以看到每种关系与数据集中的其它关系之间的比较。颜色是如此直观,因此它为我们提供了一种非常简单的数据解释方式。
现在让我们来看看实现代码。与「matplotlib」相比,「seaborn」可以被用于绘制更加高级的图形,它通常需要更多的组件,例如多种颜色、图形或变量。「matplotlib」可以被用于显示图形,「NumPY」可被用于生成数据,「pandas」可以被用于处理数据!绘图只是「seaborn」的一个简单的功能。
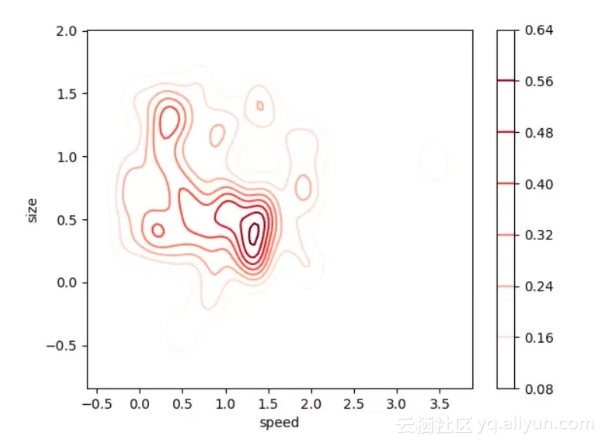
二维密度图
二维密度图(2D Density Plot)是一维版本密度图的直观扩展,相对于一维版本,其优点是能够看到关于两个变量的概率分布。例如,在下面的二维密度图中,右边的刻度图用颜色表示每个点的概率。我们的数据出现概率最大的地方(也就是数据点最集中的地方),似乎在 size=0.5,speed=1.4 左右。正如你现在所知道的,二维密度图对于迅速找出我们的数据在两个变量的情况下最集中的区域非常有用,而不是像一维密度图那样只有一个变量。当你有两个对输出非常重要的变量,并且希望了解它们如何共同作用于输出的分布时,用二维密度图观察数据是十分有效的。
事实再次证明,使用「seaborn」编写代码是十分便捷的!这一次,我们将创建一个偏态分布,让数据可视化结果更有趣。你可以对大多数可选参数进行调整,让可视化看结果看起来更清楚。
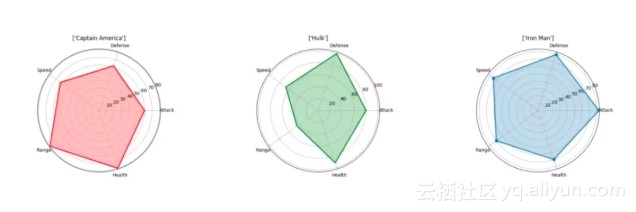
蜘蛛网图
蜘蛛网图(Spider Plot)是显示一对多关系的最佳方法之一。换而言之,你可以绘制并查看多个与某个变量或类别相关的变量的值。在蜘蛛网图中,一个变量相对于另一个变量的显著性是清晰而明显的,因为在特定的方向上,覆盖的面积和距离中心的长度变得更大。如果你想看看利用这些变量描述的几个不同类别的对象有何不同,可以将它们并排绘制。在下面的图表中,我们很容易比较复仇者联盟的不同属性,并看到他们各自的优势所在!(请注意,这些数据是随机设置的,我对复仇者联盟的成员们没有偏见。)
在这里,我们可以直接使用「matplotlib」而非「seaborn」来创建可视化结果。我们需要让每个属性沿圆周等距分布。我们将在每个角上设置标签,然后将值绘制为一个点,它到中心的距离取决于它的值/大小。最后,为了显示更清晰,我们将使用半透明的颜色来填充将属性点连接起来得到的线条所包围的区域。
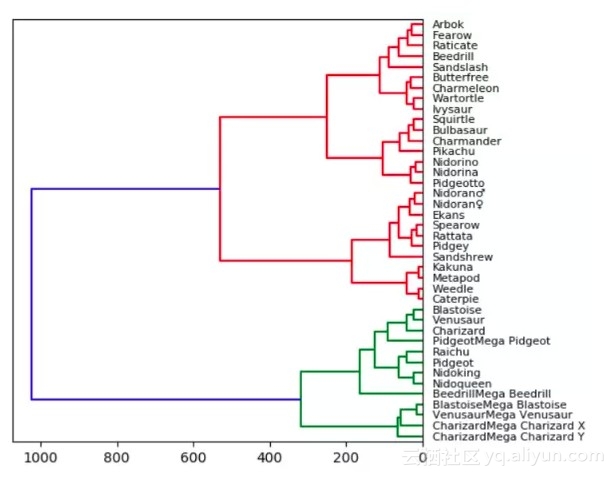
树状图
我们从小学就开始使用树状图(Tree Diagram)了!树状图是自然而直观的,这使它们容易被解释。直接相连的节点关系密切,而具有多个连接的节点则不太相似。在下面的可视化结果中,我根据 Kaggle 的统计数据(生命值、攻击力、防御力、特殊攻击、特殊防御、速度)绘制了一小部分口袋妖怪游戏的数据集的树状图。
因此,统计意义上最匹配的口袋妖怪将被紧密地连接在一起。例如,在图的顶部,阿柏怪 和尖嘴鸟是直接连接的,如果我们查看数据,阿柏怪的总分为 438,尖嘴鸟则为 442,二者非常接近!但是如果我们看看拉达,我们可以看到其总得分为 413,这和阿柏怪、尖嘴鸟就具有较大差别了,所以它们在树状图中是被分开的!当我们沿着树往上移动时,绿色组的口袋妖怪彼此之间比它们和红色组中的任何口袋妖怪都更相似,即使这里并没有直接的绿色的连接。
对于树状图,我们实际上需要使用「Scipy」来绘制!读取数据集中的数据之后,我们将删除字符串列。这么做只是为了使可视化结果更加直观、便于理解,但在实践中,将这些字符串转换为分类变量会得到更好的结果和对比效果。我们还设置了数据帧的索引,以便能够恰当地将其用作引用每个节点的列。最后需要告诉大家的是,在「Scipy」中计算和绘制树状图只需要一行简单的代码。
原文发布时间为:2018-12-5
本文作者:机器之心
本文来自云栖社区合作伙伴“ 数据分析”,了解相关信息可以关注“ecshujufenxi”微信公众号

微信关注我们
转载内容版权归作者及来源网站所有!
低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
为解决软件依赖安装时官方源访问速度慢的问题,腾讯云为一些软件搭建了缓存服务。您可以通过使用腾讯云软件源站来提升依赖包的安装速度。为了方便用户自由搭建服务架构,目前腾讯云软件源站支持公网访问和内网访问。
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service 的首字母简称,一个易于构建 AI Agent 应用的动态服务发现、配置管理和AI智能体管理平台。Nacos 致力于帮助您发现、配置和管理微服务及AI智能体应用。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据、流量管理。Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。
Rocky Linux(中文名:洛基)是由Gregory Kurtzer于2020年12月发起的企业级Linux发行版,作为CentOS稳定版停止维护后与RHEL(Red Hat Enterprise Linux)完全兼容的开源替代方案,由社区拥有并管理,支持x86_64、aarch64等架构。其通过重新编译RHEL源代码提供长期稳定性,采用模块化包装和SELinux安全架构,默认包含GNOME桌面环境及XFS文件系统,支持十年生命周期更新。
WebStorm 是jetbrains公司旗下一款JavaScript 开发工具。目前已经被广大中国JS开发者誉为“Web前端开发神器”、“最强大的HTML5编辑器”、“最智能的JavaScript IDE”等。与IntelliJ IDEA同源,继承了IntelliJ IDEA强大的JS部分的功能。
扫码在手机上查看文章
扫描二维码,手机阅读更方便
有任何问题或合作意向欢迎联系我们
Email: 99873273@qq.com
QQ: 99873273