


记一次800多万XML文本文件预处理经历
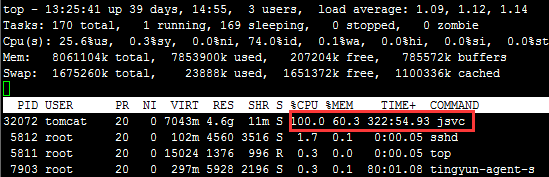
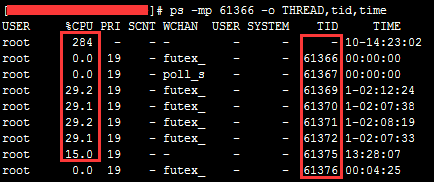
一.背景 由于某些需求,现需对系统在最近几个月生成的xml文件进行预处理,提取标签内的数据进行分析。这些需要预处理的数据大概有280GB左右880多万,存放在gysl目录下,gysl的下一层按天命名,分为若干个目录,接下来一层目录下又有多个目录,我们所需的xml目录就在这一层。我们现在需要将此目录下面的xml文件使用Python脚本进行处理,并将处理结果按天(与源文件一致)保存到~/temp目录下。 二.操作过程 2.1 Python脚本准备。 #!/usr/bin/python3 # -*- coding:utf-8 -*- import glob,os,sys, re from concurrent.futures import ProcessPoolExecutor import argparse import random def find_xs(str, list): i = 0 for i in range(0,len(str)): if str[i] in list: return i return -1 def segement_aux(para, OUT, sep_l...