现在想改变一下写作方式,以问答的形式来讲解这些枯燥无味的知识,尽量把每一个为什么都讲透,每个知识点都不迷惑。
桃翁桃翁,问个问题呢,据说 js 里面有个执行上下文,这个概念是个什么东东哦?据说挺重要的,给我科普科普呗。
Emm… 这个概念非常的抽象,简单来说呢,就是 JS 在执行某段代码的时候做的一些事情。
具体做的事情就是定义了变量或函数有权访问的其他数据决定了它们各自的行为(作用域链)。每个执行环境都有一个与之关联的变量对象(variable object),环境中定义的所有变量和函数都保存在这个对象中(变量包括 this、arguments)。虽然我们编写的代码无法访问这个对象,但解析器在处理数据时会在后台使用它。
哇,还是好抽象啊,你能不能画个图举个栗子呢?
在之前说的执行上下文就是解释器在执行 JS 某段代码的时候做的一些事,那么首先我们把代码分个类。
Global 代码:代码第一次执行时默认的环境。
Function 代码:执行到一个函数中。
Eval 代码:文本在eval函数内部执行。
![72c6d3580a87228022e7f61fa1d055415a7994d7]()
看到这个图相信现在分清楚各种类型的代码,每种类型代码会都会产生执行上下文,我们把 Global 代码产生的执行环境叫「全局执行上下文」,把 Function 代码产生的执行环境叫「执行上下文」吧,Eval 代码不考虑。
那我看这个图似乎有很多执行上下文(execution context),这个具体是怎么来的呢?
全局执行上下文只有一个,而执行环境的话是每次函数调用都会产生一个执行上下文。注意要调用才会产生哦,不调用是不会产生的。
那这个执行上下文基本知道是个什么东西了,那执行上下文栈又是啥呢?
见名知意,执行上下文栈就是执行上下文(包含全局执行上下文)形成的栈嘛。
那为什么要有这个执行上下文栈呢?
浏览器中 JavaScript 解释器是单线程的,这就是说同一时间代码只会做一件事,那么创建这么多执行上下文,又不能同一时间执行多个上下文,所以就必须要有个顺序,这个顺序就是就是先进后出,这很明显就是一个栈结构嘛。
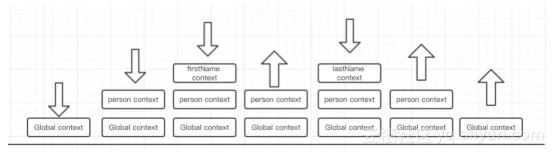
那我就疑惑了,为啥要先进后出,不先进先出呢?
![6b477666c31d23a1ab7d3de968a1d32125e67faf]()
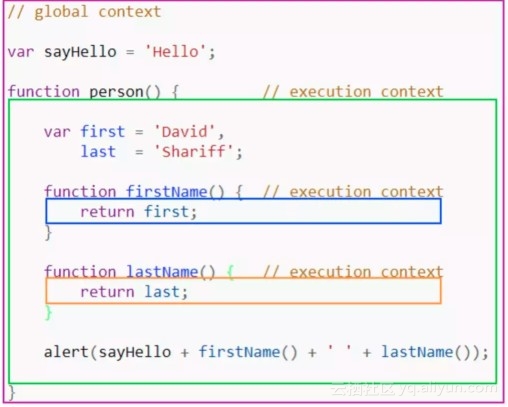
我们分析一下图一的代码,结合上图,首先我们看图 1,解释代码的时候首先创建的就是全局上下文,然后再创建 person 的执行上下文,然后再创建 firstName 的上下文,然后再执行完毕 firstName ,就把 firstName 的上下文弹出,再 创建 lastName 的上下文,然后执行完毕,再弹出 lastName 的上下文,然后执行完 person 的上下文,再弹出 person 的上下文,再执行全局上下文,然后全局上下文弹出。
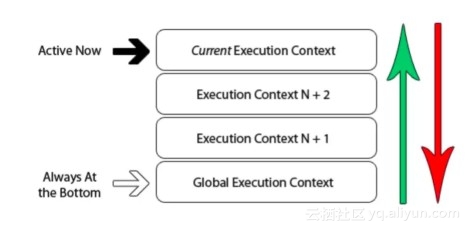
如下是一张经典的执行上下文栈的图。
![18d42dd7bc9acc28cf28adf159b129aead62fc0e]()
默认进入全局上下文。如果你的全局代码中调用了一个函数,那么程序将会进入这个被调用函数的上下文,创建一个新的执行上下文,并把当前上下文放到栈顶。浏览器总是会把当前执行上下文放到栈的顶部,一旦函数执行完成,这个执行上下文就会从栈中移除,返回到栈中的下一个上下文。
这些大概明白了,不过你说在创建执行上下文做的那些事儿,我还是有点迷糊,能再详细说说吗?
那我们首先看点代码:
// 例1
console.log(a); // 报错,a is not defined
// 例2
console.log(a); // undefined
var a;
// 例 3
console.log(a); // undefined
var a = 666;
// 例 4
console.log(this); // window 对象
// 例 5
function foo(x) {
console.log(arguments); // [666]
console.log(x); // 666
}
foo(666);
// 例 6
// 函数表达式
console.log(foo); // undefined
var foo = function foo() {}
// 例 7
// 函数声明
console.log(foo); // function() {}
function foo() {}
这 7 个例子相信大家对这些答案都是没有疑惑的,最基础的东西,例 1 报错,a 未定义,很正常。例 2、例 3 输出都是 undefined,说明浏览器在执行 console.log(a) 时,已经知道了 a 是 undefined,但却不知道 a 是 666(例 3)。
看例 4 就知道,当执行这条语句的时候 this 已经被赋值了。
在例 5 中展示了在函数体的语句执行之前,arguments 变量和函数的参数都已经被赋值。从这里可以看出,函数每被调用一次,都会产生一个新的执行上下文环境。因为不同的调用可能就会有不同的参数。
然后就是例 6,例 7 中可以看出函数表达式跟变量声明一样,只是给变量赋值成 undefined,而函数声明会将会把函数整个赋值了。
总结在执行上下文做的赋值事情
变量、函数表达式——变量声明,默认赋值为undefined;
this——赋值;
函数声明——赋值;
执行上下文就介绍到这里,如果你对相关知识还是感到迷惑,比如当在创建执行上下文的时候还有作用域,以及变量对象等概念,后面再一一介绍,不要担心,跟着我的文章走,这块一定能啃动。
原文发布时间为:2018-09-21
原文作者: 桃翁
本文来自云栖社区合作伙伴“ 前端桃园”,了解相关信息可以关注“ 前端桃园”。