需求
有个朋友提出,希望把目录中的许多 markdown 文件,批量转换为对应名称的 pdf 格式文件。我于是编写了一个 Python 脚本,并且分享给你。如果你有类似的需求,欢迎使用。
由于使用了 pandoc 作为转换工具,因此 Markdown 文件里的图片链接,不论是本地存储的(只测试了绝对路径情况),还是图床上的,都可以正确转换并且显示到 pdf 文件里。
环境
因为提出需求的朋友,使用的是 macOS 系统,因此这里我们以 macOS 系统的安装方式为准。注意下述工具实际上都是跨平台的。因此如果你使用的是 Windows 或者 Linux ,理论上也都是可以使用的。
这个脚本在 macOS 下测试通过,欢迎你把其他平台测试的结果告诉我。
python 3
建议使用 anaconda 软件包。请到这个地址下载适合自己操作系统的 Python 3 版本,并且进行安装。我曾经做了一个视频教程,完整展示和讲解了 anaconda 的安装流程,并且介绍了如何进行相关的命令行操作。欢迎点击这个链接,观看相关的介绍说明。
pandoc
请到这个链接,下载最新版本的 pandoc 并且进行安装。
tinytex
因为需要转换的 markdown 文件,大部分都是中文文档,因此转换到 pdf 的时候,需要 xelatex 的支持。
xelatex 可以用各种 latex 集成包来安装使用,例如 texlive 等。但是这里推荐谢益辉的 tinytex 包,简单小巧。
不过使用之前,建议删除掉系统里面原有的 texlive 等包。否则可能会造成冲突。
在终端窗口下,执行这个命令:
curl -sL "https://yihui.name/gh/tinytex/tools/install-unx.sh"
tinytex 就安装好了。
之后,为了能够更好地辅助我们进行转换,需要执行下列命令,安装扩展:
tlmgr install unicode-math filehook xecjk xltxtra realscripts fancyhdr lastpage ctex ms cjk ulem environ trimspaces zhnumber collection-fontsrecommended
代码
请到这个 github repo 下载运行代码。或者直接点击这个链接,下载压缩包并且解压。
压缩包里面,有两个文件。
其中的batch-markdown-to-pdf.py是运行脚本,template.tex是转换是采用的模板,这个模板并非我做的,它来自于这个 github 项目。
如果你对 latex 有研究,可以自行修改 template.tex 的内容,以控制输出 pdf 的样式。
准备
请把要转换的全部 markdown 文件(需要用".md"结尾),都放在同一个目录中。
注意我的样例目录,使用的是 macOS 的下载文件夹下面的“测试目录”,路径如下:
"~/Downloads/测试目录/"
你的目录,大概会与此不同,所以请你在使用之前,先打开 batch-markdown-to-pdf.py ,并且把其中第一行的路径,替换成自己电脑上的目录名称。
运行
运行起来,就很简单了。
进入终端,通过 cd 命令转换到解压后的代码所在目录。如果你对 cd 命令不是很清楚,请回顾刚才我提到的视频教程 。
之后,执行:
python batch-markdown-to-pdf.py
如果一切正常,你会看到程序在运行,不过没有什么输出提示的。
因为转换 pdf 的工作需要一些时间。所以如果你的 Markdown 文件很多,可能需要等一会儿。
请不要着急。去喝杯茶,看看书,休息一下。
当你回来的时候,(但愿)已经转换完毕了。
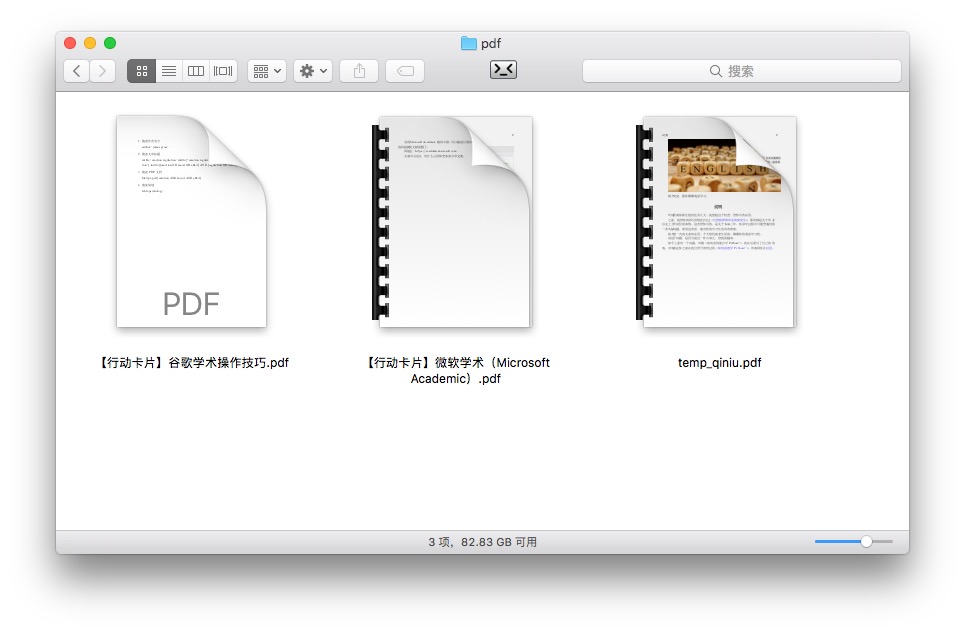
你会看到,在原先的 markdown 文件所在目录下面,生成了一个新的文件夹,叫做 pdf 。
你的转换后 pdf 文件,应该已经在里面了。
如果遇到问题,欢迎反馈给我。
祝使用愉快!
喜欢请点赞和打赏。还可以微信关注和置顶我的公众号“玉树芝兰”(nkwangshuyi)。
如果你对 Python 与数据科学感兴趣,不妨阅读我的系列教程索引贴《如何高效入门数据科学?》,里面还有更多的有趣问题及解法。