《一统江湖的大前端》系列是自己的前端学习笔记,旨在介绍javascript在非网页开发领域的应用案例和发现各类好玩的js库,不定期更新。如果你对前端的理解还是写写页面绑绑事件,那你真的是有点OUT了,前端能做的事情已经太多了, 手机app开发 , 桌面应用开发 , 用于神经网络人工智能的库 , 页面游戏 , 数据可视化 , 甚至 嵌入式开发 ,什么火就搞什么,活脱脱一个蹭热点小能手。如果你也觉得前端的日常开发有些枯燥,不妨一起来看看前端的另一番模样。
![img_4bb4848189a52e346a67d405c1cd1fcb.jpe]()
为什么你总是下不了班
大部分工程化的项目为方便维护,大多都会采用前后端分离的开发方式,而前端和后端的工作基本也是同时下发的,这时前端开发人员就会很尴尬,后端在干活的时候,领导几乎一定会让你先做个静态页面看看,这时候你和后端之间可能只是约定了接口(当然也可能连接口都没约定,那我只能祝你幸福了),并没有数据的传输,没法直接拿到填充网页的数据,如果一次将前端代码写到位,那么打开网页时轻则页面提示没有获取到数据,重则直接报错退出脚本。
而真正的问题在于静态页面做起来是非常快的,以至于你的领导会认为当你把静态页面中加入javascript的逻辑部分的代码后也应该非常快,而实际上逻辑部分的代码量和联调的工作量几乎是写一个静态页面的5-10倍。
基本上前端的一个需求的开发至少需要经历静态页面——>业务逻辑+静态数据——>业务逻辑+http请求及数据处理这几种不同形态才能交工,那么真实的时间轴变成了这样:
| 角色 |
阶段1 |
阶段2 |
阶段3 |
阶段4 |
阶段5 |
阶段6 |
| 后端 |
写后台代码 |
写后台代码 |
回家睡觉 |
回家睡觉或忙其他事 |
修改前端提交的bug |
重复4-5直到能上线 |
| 前端 |
写静态页面 |
漫无目的改样式 |
写前端逻辑 |
边开发前端边测试接口 |
漫无目的改样式 |
重复4-5直到能上线 |
无论从哪个方面看,前端都是一个打杂的活,无论从哪个角度看,前端也都是一个小弟脸,下不了班好像也是应该的。
Node.js
Node火起来的时候,前端就流行这样一句话:不会Node.js的前端,是不完整的,简单地说,Node.js将javascript能力扩展至服务端的关键一步,js也是从此开始了自己无孔不入的风骚操作,网上关于如何使用Node.js搭起一个本地服务器数不胜数,本篇中使用express框架来快速搭建Mock服务器。
![img_54c990e88ea488deff630c9287f98c4c.jpe]()
Mock.js
Mock.js(github仓库地址)是一个生成Mock数据(也就是虚拟数据)js库,语法简单明了却非常好用,支持前端和服务端两种环境引用,感兴趣的读者可以点击上面链接进行学习,官方Wiki提供了全套文档,最多1小时就可以上手。
| 工作方式 |
优势 |
劣势 |
| 客户端 |
操作方便,纯前端本地即可实现 |
1.不易进行接口管理 2.协作人员无法获得Mock数据 |
| 服务端 |
1.前端代码几乎不需改动 2.其他人员可访问获得Mock数据 |
需要搭建Mock服务器,相较前者稍复杂 |
简单浏览一下其使用方式:
![img_7fde230149e3442225ac5d9cba169024.jpe]()
# 安装
npm install mockjs
// 使用 Mock
var Mock = require('mockjs')
var data = Mock.mock({
// 属性 list 的值是一个数组,其中含有 1 到 10 个元素,每个元素均包含id,name,description属性
'list|1-10': [{
'id|+1': 1,// 属性 id 是一个自增数,起始值为 1,每次增 1
'name': '@cname',//占位符语法,生成一个中文名称
'description|3-5':'@csentence',//占位符语法,生成3-5个中文句子
'area':'@province',//省份占位符,将随机生成省份名称
}]
})
// 输出结果
console.log(JSON.stringify(data))
前端的任务到底是什么
前端开发的本质,是数据的采集和数据的呈现,即把用户提交的数据准确安全地发送给服务器,把服务器传递的数据按照设计图展示在界面上,无论是否界面是否经过CSS的美化,是否经过交互设计的易用性优化,最本质的东西是一样的。
换句话说,你需要做到的是后端给的数据正确时,确保将其按设计稿展示出来,后端给的数据不正确时,给出提示并尽可能不要让脚本报错退出。
使用Nodejs和Mockjs搞事情
建议的做法是:使用node.js框架express快速搭建服务器,与后端人员约定好接口后,使用Mock.js在服务端生成各类型虚拟数据,前端开发人员直接对接Mock服务器
你应该做的,是一次性将前端代码写到位并能够快速定位联调异常,然后回家睡觉,而不是漫无目的劳作和等待跟其他人互相扯皮。
1.安装node.js
+ 安装后打开cmd命令行,输入`node -v`, 若正确显示版本号则安装成功。
附件中包含: nodeV8.9.4版本windows安装包
2.安装其他依赖包
-
yarn(替代npm的包管理工具): npm install yarn(可选)
-
express (express框架): npm install express -g
-
express-generator (express项目生成插件): npm install express-generator -g
-
mockjs(模拟数据生成库): npm install mockjs
若安装速度较慢,可切换npm源为cnpm或使用Yarn进行包管理
3.生成新的express项目并编写服务端
本篇力求简单粗暴,只讲使用不讲express目录结构,感兴趣的同学可自行研究
3.1 在指定路径下打开命令行,输入express mockserver,即可生成名为mockserver的项目
3.2 打开app.js文件,在 var app = express() 之后加入如下代码,屏蔽跨域:
app.all('*', function(req, res, next) {
res.header("Access-Control-Allow-Origin", "*");
res.header("Access-Control-Allow-Methods","PUT,POST,GET,DELETE,OPTIONS");
next();
});
3.3 仿照users.js文件的格式及其在app.js文件中的路由挂载方式(任何一个熟练地代码搬运工肯定看得懂),引入mockjs,生成需要的随机数据,当接收到前端发送的请求时,返回生成的数据:
//服务端响应代码片段/routes/operationboard.js:
//业务逻辑为查询系统告警信息列表
//node服务器启动后,请求地址为:127.0.0.1:3000/operationboard/systemwarn
//3000端口为express默认启动端口
var express = require('express');
var router = express.Router();
var Mock = require('mockjs');
var Random = Mock.Random;
router.get('/systemwarn', function (req, res, next) {
var data =Mock.mock({
'list|20':[{
'id|+1':1,
'serial_number|1-100':1,
'warn_number|1-100':1,
'warn_name|1':['流水线编排服务异常','磁盘占用超过阈值'],
'warn_level|1':['紧急','重要'],
'warn_detail':'环境IP:10.114.123.12,服务名称:XX',
'create_time':Random.datetime(),
'finish_time':Random.datetime(),
'contact|4':'abc'
}]
});
res.send({
meta : {
message: 'success'
},
status:true,
data: data.list
})
})
module.exports = router;
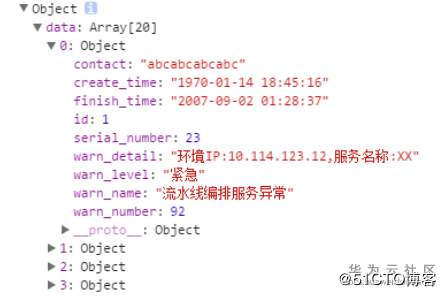
浏览器访问可在控制台打出返回数据:
![img_c27625c2b5739b745510ca5c729160cb.jpe]()
3.4 在mockserver项目目录下打开命令行工具,输入npm start,待服务启动后,打开前端页面即可看到服务器返回的模拟数据。
3.5 开启其他人员的访问能力,其实就是在本地搭建一个服务器。
实现方式1——通过express工程来实现node服务器
将前端代码拷贝至express项目目录中public文件夹(本例中为/mockserver/public),打开命令行工具输入ipconfig查询本机IP,将127.0.0.1替换为本机IP,然后在浏览器直接访问即可打开网页。
实现方式2——传统Apache服务器
为方便管理,直接使用开源XAMPP集成环境,安装完成后一键开启apache服务器,并将前端代码拷贝至安装目录中htdoc文件夹中的子文件夹中,然后以方式1中类似的方式在浏览器中访问即可,由于服务端代码取消了跨域限制,故即使端口号不同,apache服务器中的网站仍然可以访问node服务器中的接口并拿到数据。
3.6 最后,项目是大家一起做的,不是你撇清责任就完事了的,为你所做的一切提供一个可参考访问的excel文档并把它发给与你合作开发的后端是有礼貌的做法。