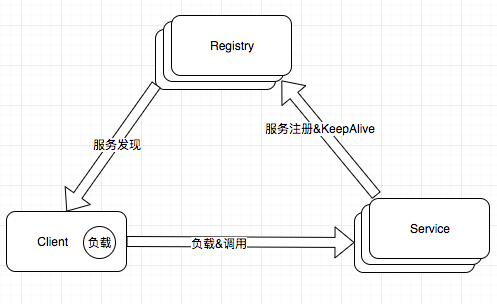
服务的注册与发现是微服务必不可少的功能,这样系统才能有更高的性能,更高的可用性。go-micro框架的服务发现有自己能用的接口Registry。只要实现这个接口就可以定制自己的服务注册和发现。
go-micro在客户端做的负载,典型的Balancing-aware Client模式。
![]()
服务端把服务的地址信息保存到Registry, 然后定时的心跳检查,或者定时的重新注册服务。客户端监听Registry,最好是把服务信息保存到本地,监听服务的变动,更新缓存。当调用服务端的接口是时,根据客户端的服务列表和负载算法选择服务端进行通信。
go-micro的能用Registry接口
type Registry interface {
Register(*Service, ...RegisterOption) error
Deregister(*Service) error
GetService(string) ([]*Service, error)
ListServices() ([]*Service, error)
Watch(...WatchOption) (Watcher, error)
String() string
Options() Options
}
type Watcher interface {
// Next is a blocking call
Next() (*Result, error)
Stop()
}
这个接口还是很简单明了的,看方法也大概能猜到主要的作用
Register方法和Deregister是服务端用于注册服务的,Watcher接口是客户端用于监听服务信息变化的。
接下来我以go-micro的etcdv3为Registry的例给大家详细讲解一下go-micro的详细服务发现过程
go-micro 服务端注册服务
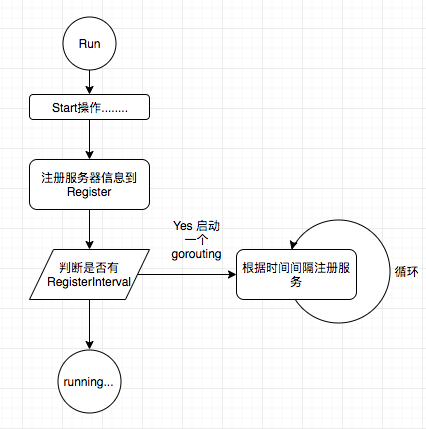
流程图
![]()
服务端看上去流程还是比较简单的,当服务端调用Run()方法时,会调用service.Start()方法。这个除了监听端口,启动服务,还会把服务的ip端口号信息,和所有的公开接口的元数据信息保存到我们选择的Register服务器上去。
看上去没有问题,但是,如果我们的节点发生故障,也是需要告诉Register把我们的节点信息删除掉。
Run()方法中有个go s.run(ex) 方法的调用,这个方法就是根据我们设置interval去重新注册服务,当然比较保险的方式是我们把服务的ttl也设置上,这样当服务在未知的情况下崩溃,到了ttl的时间Register服务也会自动把信息删除掉。
![]()
设置服务的ttl和 interval
// 初始化服务
service := micro.NewService(
micro.Name(common.ServiceName),
micro.RegisterTTL(time.Second*30),
micro.RegisterInterval(time.Second*20),
micro.Registry(reg),
)
ttl就是注册服务的过期时间,interval就是间隔多久再次注册服务。如果系统崩溃,过期时间也会把服务删除掉。客户端当然也会有相应的判断,下面会详细解说
客户端发现服务
客户端的服务发现要步骤多一些,但并不复杂,他涉及到服务选择Selector和服务发现Register两部分。
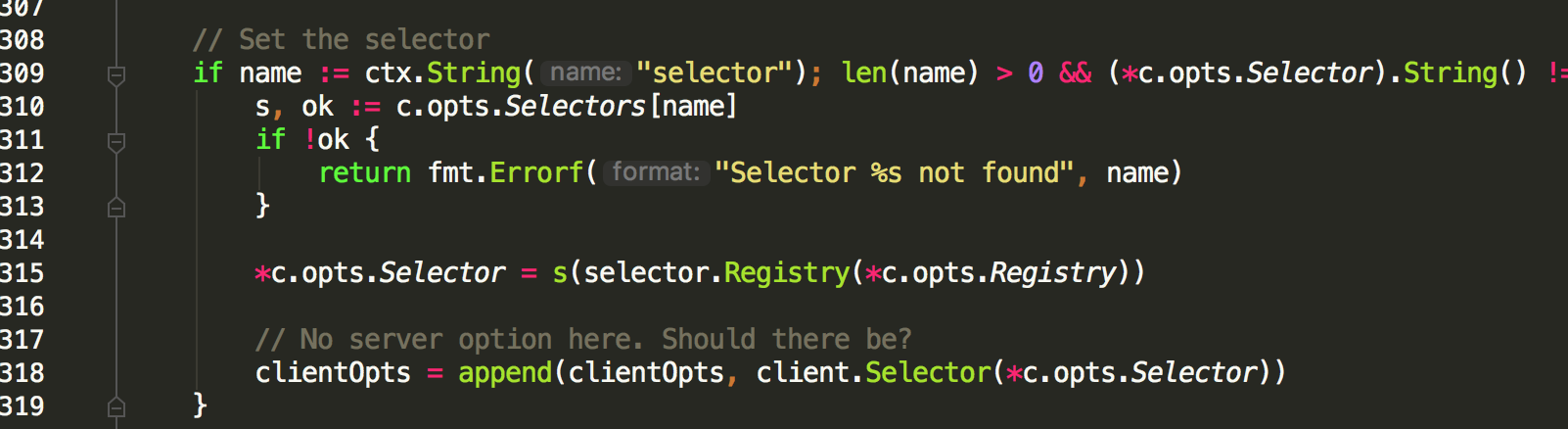
Selector是基于服务发现的,根据你选择的主机选择算法,返回主机的信息。默认的情况,go-micro是每次要得到服务器主机的信息都要去Register去获取。但是查看cmd.go的源码你会发现默认初始化的值,selector的默认flag是cache。DefaultSelectors里的cache对应的就是初始化cacheSelector方法
![]()
但是当你在执行service.Init()方法时
![]()
go-micro会把默认的selector替换成cacheSelector,具体的实现是在cmd.go的Before方法里
![]()
cacheSelector 会把从Register里获取的主机信息缓存起来。并设置超时时间,如果超时则重新获取。在获取主机信息的时候他会单独跑一个协程,去watch服务的注册,如果有新节点发现,则加到缓存中,如果有节点故障则删除缓存中的节点信息。当client还要根据selector选择的主机选择算法才能得到主机信息,目前只有两种算法,循环和随机法。为了增加执行效率,很client端也会设置缓存连接池,这个点,以后会详细说。
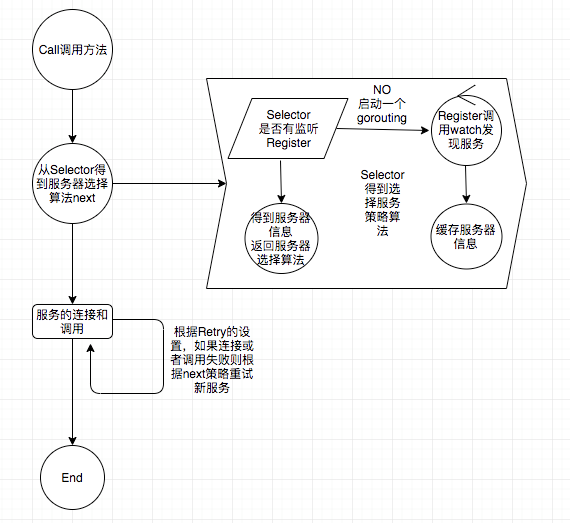
所以大概的客户端服务发现流程是下面这样
![]()
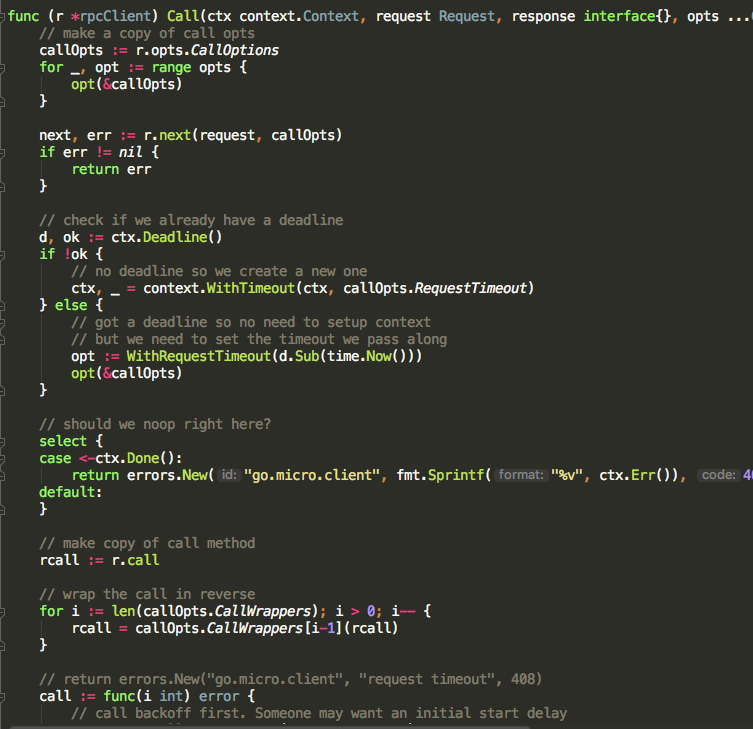
主要的调用过程都在Call方法内
![]()
主要的思路是
从Selector里得到选择主机策略方法next。
根据Retory是否重试调用服务,调用服务的过程是,从next 方法内得到主机,连接并传输数据 ,如果失败则重试,重试时,会根据主机选择策略方法next重新得到一个新的主机进行操作。