投资家兼企业家Peter Thiel最喜欢的问题是:很少人赞同你的重要事实有哪些?
如果你在2010年向Geoffrey Hinton教授提出这个问题,他会回答道,卷积神经网络(CNN)有可能在解决图像分类问题上发挥巨大的作用。当时,该领域的研究人员并不重视这一言论,因为深度学习太平淡无奇了。
2010年ImageNet项目的大规模视觉识别挑战(ILSVRC)启动。
在随后的两年时间里,Alex Krizhevsky,Ilya Sutskever和Geoffrey E. Hinton的论文“利用深度卷积神经网络对图像进行分类”发表,这是前所未有的震撼!这篇论文以一种巧妙的手法打破了旧观念,开创了计算机视觉的新局面。
在接下来的几年里,多个团队将构建CNN体系结构,以期望超越人类层面的准确性。2012年论文中使用的架构通常被称为AlexNet,是用第一作者Alex Krizhevsky的名字命名。本文将回顾AlexNet的架构并讨论它的主要贡献。
输入
AlexNet是2012年ImageNet项目的大规模视觉识别挑战(ILSVRC)中的胜出者。AlexNet解决了图像分类的问题,输入是1000个不同类型图像(如猫、狗等)中的一个图像,输出是1000个数字的矢量。输出向量的第i个元素即为输入图像属于第i类图像的概率。因此,输出向量的所有元素之和为1。
AlexNet的输入是一个大小为256×256的RGB图像。因此所有的训练集图像和测试图像的大小都要为256×256。
如果输入图像的大小不是256×256,那么用它来训练神经网络之前需要将其转换成256×256的大小。为了实现这一转换,将图像尺寸缩小成256,最终剪裁获得一个大小为256×256的图像。下图显示了一个示例:
![a30d752652138dca9f45b8cc59c872622fe4836b]()
如果输入图像为灰度图像,可以通过复制单个通道将其转换成一个3通道的RGB图像。由256×256的图像可产生随机大小的图像,其中大小为227×227的图像来填充AlexNet的第一层。
AlexNet架构
与用于计算机视觉设计的CNN相比,AlexNet要大得多。AlexNet拥有6000万个参数和65万个神经元,并且花了五到六天的时间来训练两个GTX 580。现在有很多更复杂的CNNs,即使是在非常大的数据集中,也可以高效地运行在更快的GPUs上。
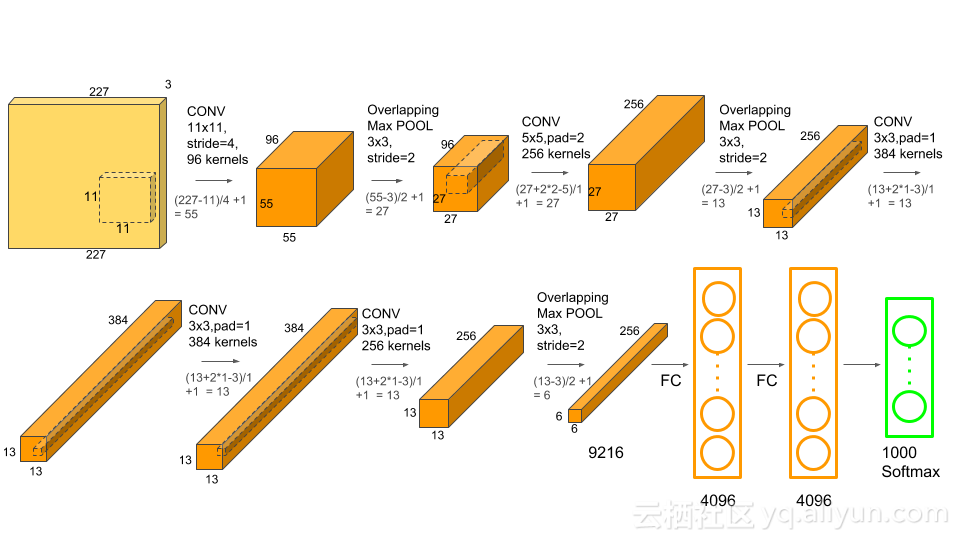
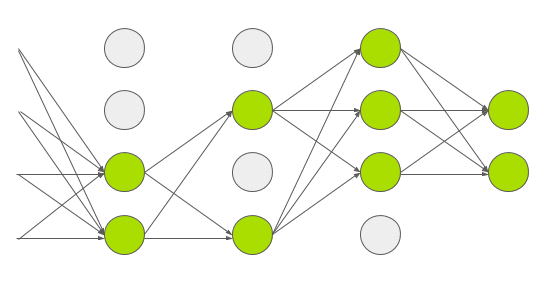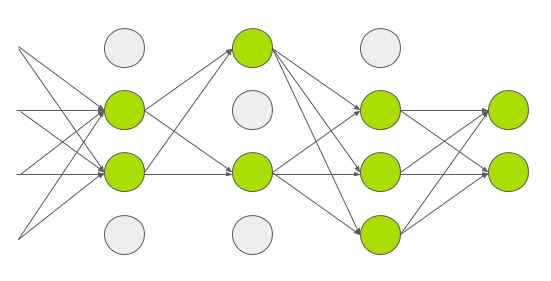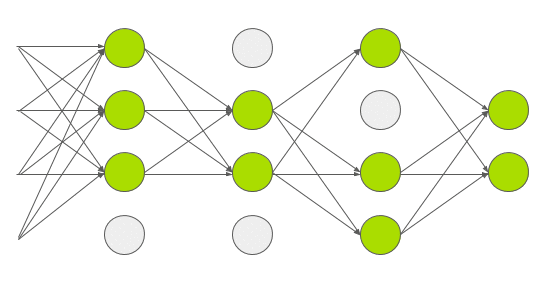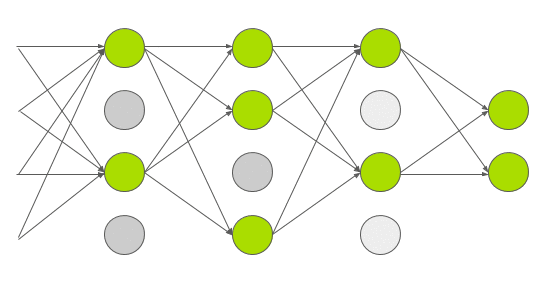
AlexNet架构如下图所示:
![50406bc5020b03655e525f64df06c75b8e1aab57]()
AlexNet由5个卷积层和3个全连接层组成
多个卷积内核(a.k.a过滤器)可以提取图像中有趣的特征。通常,同一卷积层中内核的大小是相同的。例如,AlexNet的第一个Conv层包含96个大小为11x11x3的内核。值得注意的是,内核的宽度和高度通常是相同的,深度与通道的数量是相同的。
前两个卷积层后面是重叠的最大池层,第三个、第四个和第五个卷积层都是直接相连的。第5个卷积层后面是一个重叠的最大池层,它的输出会进入两个全连接层。第二个全连接层可以给softmax分类器提供1000类标签。
在所有的卷积层和全连接层之后,都应用了ReLU非线性函数。首先第一和第二个卷积层都应用ReLU非线性函数,然后进行局部标准化,最后执行pooling操作方法。但后来研究人员发现标准化并不是很有用,所以这里不详细论述。
重叠最大池化
通常使用最大池化层来对张量的宽度和高度进行采样,且保持深度不变。重叠的最大池层与最大池层类似,除了重叠最大池层的相邻窗口是相互重叠的。作者使用的池化窗口是大小为3×3,相邻窗口步幅为2的窗口。在输出尺寸相同的情况下,与使用大小为2×2,相邻窗口步幅为2的非重叠池化窗口相比,重叠池化窗口能够分别将第一名的错误率降低0.4%,第5名的错误率降低0.3%。
ReLU非线性
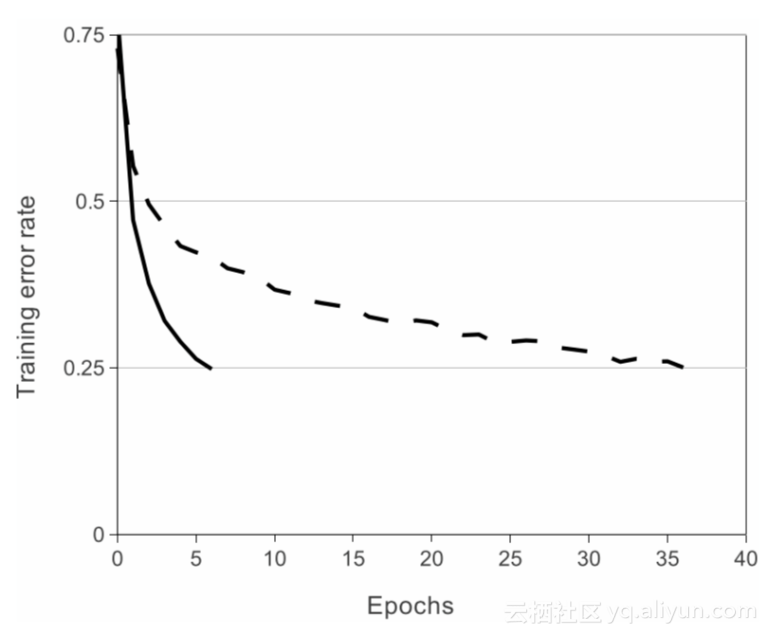
AlexNet的另一个重要特性就是使用了ReLU(整流线性单元)的非线性。Tanh或sigmoid激活函数曾是训练神经网络模型的常用方法。与使用像tanh或sigmoid这样的饱和激活函数相比,使用ReLU非线性可以使深度CNNs训练更快。本文的下图显示,与使用tanh(点线)的等效网络相比,使用ReLUs(solid曲线)的AlexNet能以6倍快的速度到达25%的训练错误率。这是在CIFAR-10数据集中完成的测试。
![bfcaf2488f837f81ebcc29b97b6b4620b4d5686a]()
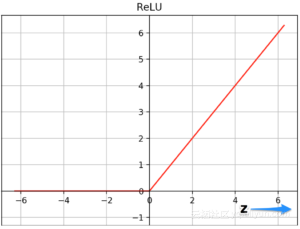
为什么用ReLUs训练得更快?ReLU函数为f(x)= max(0,x)。
![a8f1d26be4824db9b562ffaf8dffab8a2985aa65]()
上面是tanh和ReLU两个函数的图。tanh函数在z值很高或很低时饱和,且函数的斜率接近于0,有助于减缓梯度下降。另一方面,当z为较大的正值时ReLU函数的斜率不接近于零,有助于最优化收敛得更快。z为负值时斜率为零,但是神经网络中的大多数神经元最终都具有正值。sigmoid函数也因为同样的原因,稍逊于ReLU。
减少过度拟合
什么是过度拟合?
还记得你的中学同学吗?他在考试中表现得很好,但是当考试的问题需要有创造性的思考时,他却表现得很差。为什么他在遇到以前从未遇到过的问题时表现得如此糟糕?因为他记住了课堂上所涉及的问题的答案,而没有理解潜在的概念。
类似地,神经网络的大小就是它的学习能力。一不小心,它也会在不理解概念的情况下记住训练数据中的例子。虽然神经网络在训练数据上表现得格外的好,但是他们没有学习到真正的概念。在面对新的、未见过的测试数据时,它的表现就没有那么好了。这就是所谓的过度拟合。
AlexNet使用了几种不同的方法来减少过拟合。
数据增强
神经网络中涉及到同一图像的不同变化时有助于防止过度拟合。即强迫神经网络不去记忆!通常会从现有数据中生成额外的数据!以下是AlexNet团队使用的一些技巧。
通过镜像实现数据增强
如果训练集中有一只猫的图像,那么它的镜像也是一只猫。请参见下图中的示例。通过垂直轴简单地翻转图像,训练数据集可变为原来的两倍。
![ce727dcf30e04dfd538a006706612fb208c0f050]()
通过随机裁剪实现数据增强
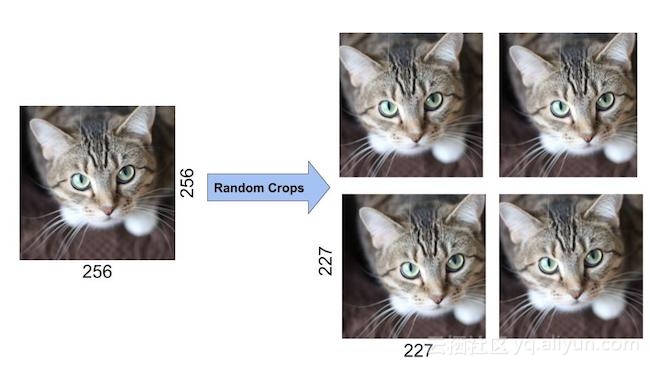
此外,随机裁剪原始图像也会导致额外的数据,即原始数据的移位版本。
AlexNet的作者从大小为256×256的图像中随机裁剪出大小为227×227的图像,并作为网络的输入。使用这种方法将数据的大小变为原来的2048倍。
![a1f5e8973551ada7934788577e9901490215892d]()
值得注意的是,这四个随机裁剪的图像看起来非常相似,但它们并不完全相同。对神经网络来说,虽然像素有微小的移动,但图像仍然是一只猫。如果没有数据增强,作者会因为严重的过度拟合而无法使用如此庞大的网络。
Dropout
在对大约60000000个参数的训练中,作者也尝试过用其他方法来减少过度拟合。其中采用了一种叫做dropout的技术,G.E. Hinton在2012年的另一篇论文中介绍了该技术。在丢弃过程中,一个神经元被从网络中丢弃的概率为0.5。当一个神经元被丢弃时,并不影响正向传播和反向传播。如下面的动画所示,每个输入都经过不同的网络架构。因此,所学习的权重参数更可靠且不易被装配。在测试过程中,全网络参与没有遗漏,但是由于神经元丢失输出变为原来的一半。丢弃技术使迭代次数收敛到2,如果没有使用丢弃技术,AlexNet的过拟合会更加严重。
![987f69f31e791db5b3f75c14282c4d2693846e54]()
参考文献:
1.利用深度卷积神经网络对图像进行分类.Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton, 2012;
2.Coursera课程的“卷积神经网络”,也是Andrew Ng深度学习专业课程的一部分。
数十款阿里云产品限时折扣中,赶紧点击领券开始云上实践吧!
本文由阿里云云栖社区组织翻译。
文章原标题《understanding-alexnet》
作者:snayak 译者:吴兆青,审校:袁虎。
文章为简译,更为详细的内容,请查看原文文章。