1.搭建zabbix服务端,我使用的是192.168.200.152机器作为zabbix服务端,去官方下载地址下载对应的版本,下载地址:
www.zabbix.com/download
下载的是一个rpm包:
[root@localhost ~]$ cd /usr/local/src/
[root@localhost /usr/local/src]$ wget http://repo.zabbix.com/zabbix/3.2/rhel/7/x86_64/zabbix-release-3.2-1.el7.noarch.rpm
安装到yum源中:
rpm -ivh zabbix-release-3.2-1.el7.noarch.rpm
使用yum安装以下这些包:
yum install -y zabbix-agent zabbix-get zabbix-server-mysql zabbix-web zabbix-web-mysql
会连带安装httpd和php。
zabbix-agent:客户端软件
zabbix-get:这是服务端上的一个工具,可以通过命令行的形式获得客户端的某些监控项目的数据
zabbix-server-mysql :这个是需要安装一些与mysql相关的文件。
zabbix-web:这个是zabbix的web界面
zabbix-web-mysql:这个是web和mysql相关的东西
2.作为客户端的机器上不需要安装这么多的包,只需要安装zabbix-agent客户端软件即可。
yum install -y zabbix-agent
3.到mysql的master、slave1以及slave2上修改mysql的配置文件,在 [mysqld] 下增加一行参数:
character_set_server = utf8
4.修改完之后重启mysql:
service mysqld restart
5.到master上创建zabbix的库:
create database zabbix character set utf8;
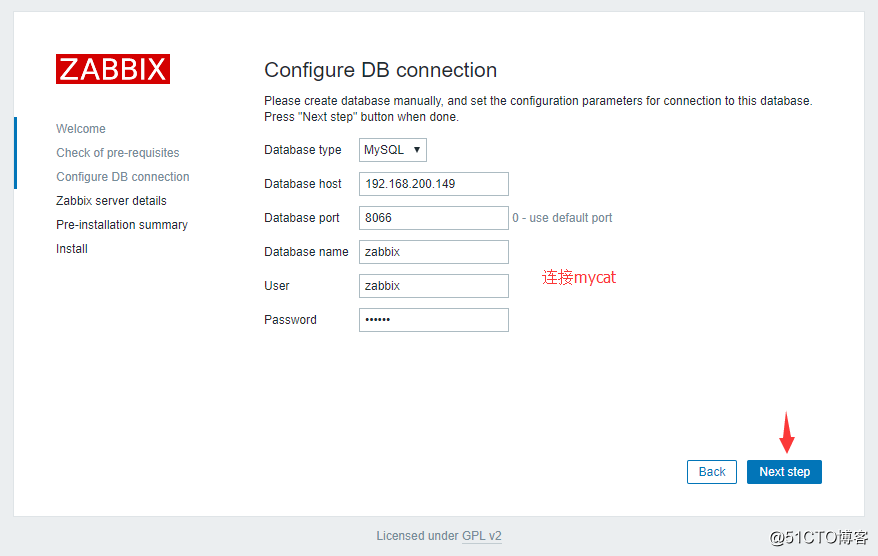
6.到mycat上,编辑配置文件增加一个用户:
[root@localhost ~]$ vim /usr/local/mycat/conf/server.xml
<user name="zabbix">
<property name="password">123456</property>
<property name="schemas">zabbix</property>
</user>
7.编辑schema.xml文件,增加数据节点:
[root@localhost ~]$ vim /usr/local/mycat/conf/schema.xml
<schema name="zabbix" checkSQLschema="false" sqlMaxLimit="1000" dataNode="dn4" />
<dataNode name="dn4" dataHost="localhost1" database="zabbix" />
8.重启mycat服务:
[root@localhost ~]$ /usr/local/mycat/bin/mycat restart
9.测试一下,看看能够使用此账户正常登陆和查看zabbix数据库。
10.完成以上操作后,退出mysql,回到zabbix服务端上,进入以下目录开始准备导入zabbix 的原始数据:
[root@localhost ~]$ cd /usr/share/doc/zabbix-server-mysql-3.2.10
[root@localhost /usr/share/doc/zabbix-server-mysql-3.2.10]$ ls
AUTHORS ChangeLog COPYING create.sql.gz NEWS README
[root@localhost /usr/share/doc/zabbix-server-mysql-3.2.10]$ gzip -d create.sql.gz
[root@localhost /usr/share/doc/zabbix-server-mysql-3.2.10]$ ls
AUTHORS ChangeLog COPYING create.sql NEWS README
[root@localhost /usr/share/doc/zabbix-server-mysql-3.2.10]$
11.将这个create.sql文件通过rsync传输到mysql_master机器上:
rsync -av /usr/share/doc/zabbix-server-mysql-3.2.10/create.sql root@192.168.200.146:/root/
12.到mysql_master机器上将这个sql文件导入到zabbix 库中:
[root@localhost ~]$ mysql -h'192.168.200.149' -uzabbix -p'123456' -P'8066' zabbix < /root/create.sql
13.登陆数据库,查看一下是否导入成功。
14.修改zabbix_server.conf配置文件:
vim /etc/zabbix/zabbix_server.conf
在DBHost中增加这一句:
DBHost=192.168.200.149:8066
然后在DBUser下面增加这一句:
DBPassword=123456
接着在DBPort下面增加这一句:
DBPort=8066
15.安装一下mysql,zabbix需要使用mysql的驱动去远程mycat
16.完成数据导入后,回到zabbix服务端上启动zabbix ,并设置为开机启动:
systemctl start zabbix-server.service
systemctl enable zabbix-server.service
如果没启动起来就查看一下zabbix的日志:
tail -n20 /var/log/zabbix/zabbix_server.log
17.检查端口和进程:
[root@localhost ~]$ netstat -lntp |grep 10051
tcp 0 0 0.0.0.0:10051 0.0.0.0:* LISTEN 17787/zabbix_server
tcp6 0 0 :::10051 :::* LISTEN 17787/zabbix_server
[root@localhost ~]$
18.修改httpd的默认监听端口为8888,还有域名:
[root@localhost ~]$ vim /etc/httpd/conf/httpd.conf
Listen 8888
ServerName www.zabbix.com:8888
19.启动httpd:
[root@localhost ~]$ systemctl start httpd.service
[root@localhost ~]$ netstat -lntp |grep 8888
tcp6 0 0 :::8888 :::* LISTEN 19217/httpd
[root@localhost ~]$ systemctl enable httpd.service
Created symlink from /etc/systemd/system/multi-user.target.wants/httpd.service to /usr/lib/systemd/system/httpd.service.
[root@localhost ~]$ ps aux |grep httpd
root 19217 0.2 1.3 457740 14068 ? Ss 22:01 0:00 /usr/sbin/httpd -DFOREGROUND
apache 19219 0.0 0.7 457876 7636 ? S 22:01 0:00 /usr/sbin/httpd -DFOREGROUND
apache 19220 0.0 0.7 457876 7636 ? S 22:01 0:00 /usr/sbin/httpd -DFOREGROUND
apache 19221 0.0 0.7 457876 7636 ? S 22:01 0:00 /usr/sbin/httpd -DFOREGROUND
apache 19222 0.0 0.7 457876 7636 ? S 22:01 0:00 /usr/sbin/httpd -DFOREGROUND
apache 19223 0.0 0.7 457876 7640 ? S 22:01 0:00 /usr/sbin/httpd -DFOREGROUND
20.增加nginx代理httpd的配置文件:
[root@localhost ~]$ vim /usr/local/nginx/conf/vhost/zabbix.com.conf
upstream zabbix_com
{
ip_hash;
server localhost:8888;
}
server
{
listen 80;
server_name www.zabbix.com;
location /zabbix/
{
proxy_pass http://zabbix_com/zabbix/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
location /
{
proxy_pass http://zabbix_com;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
[root@localhost ~]$ service nginx restart
21.在windows上在hosts中添加这一句:
192.168.200.152 www.zabbix.com
这是为了指向到真实ip上,如果指向到vip上可能在调度的时候会转发到其他机器上。
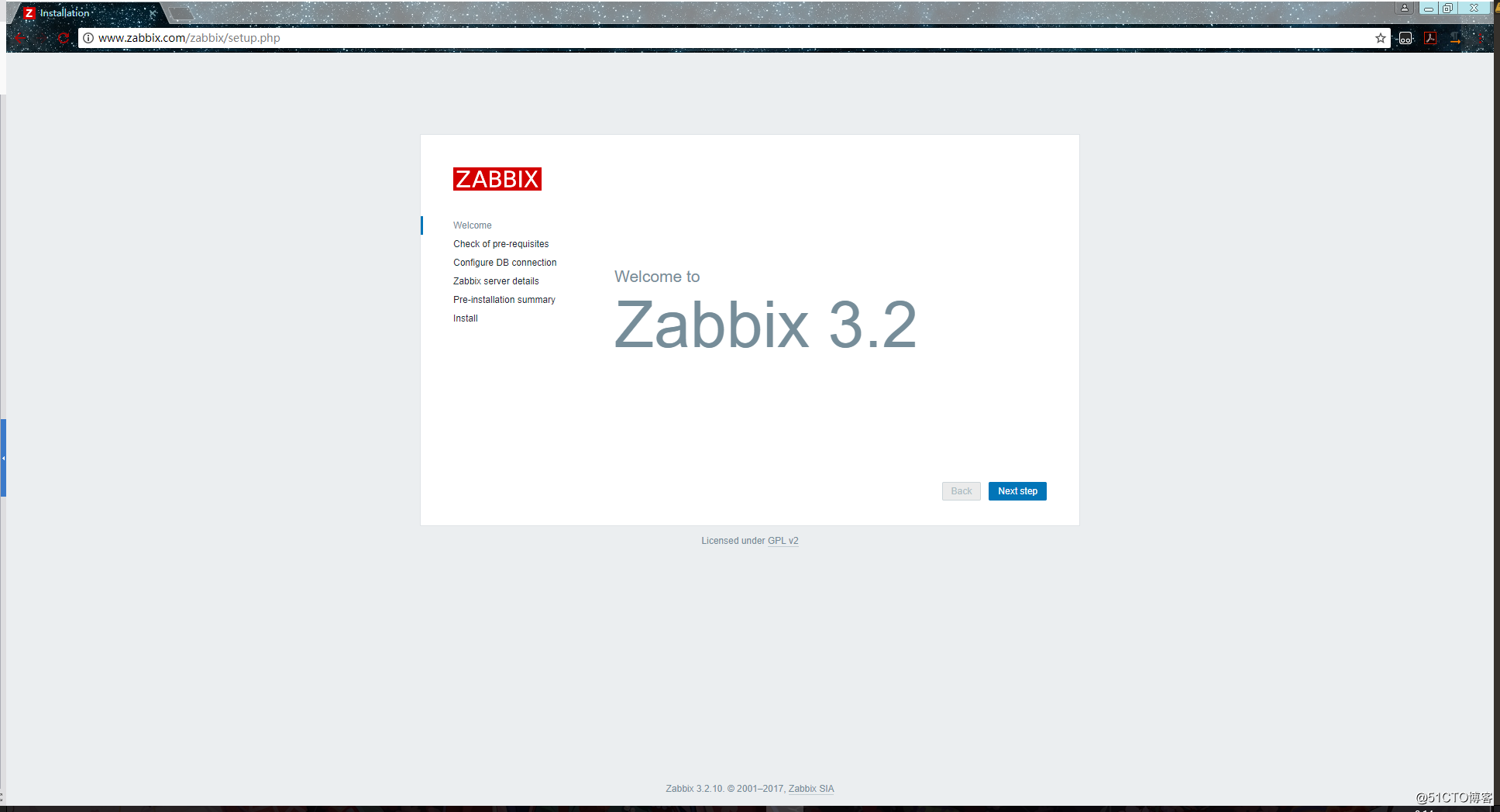
22.打开你windows的浏览器,访问:http://www.zabbix.com/zabbix/ ,进入你的zabbix安装页面:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
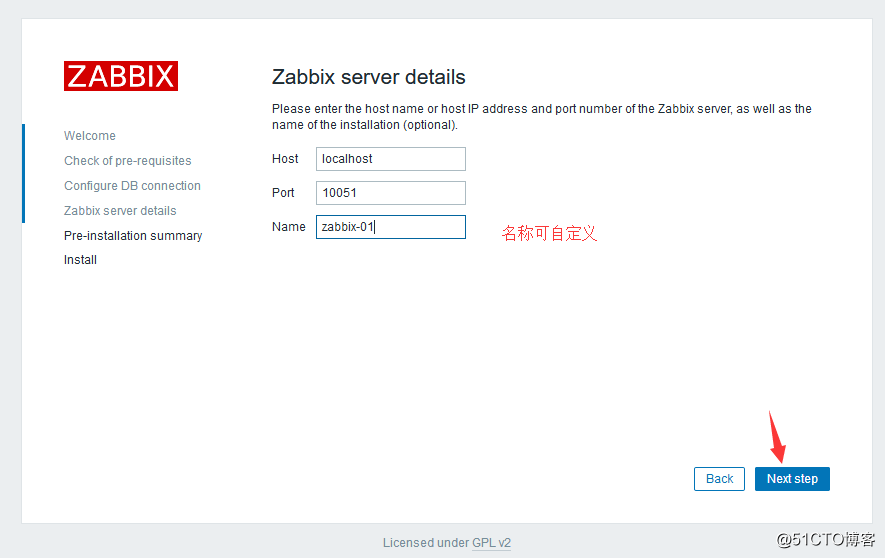
点击Next step开始配置:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
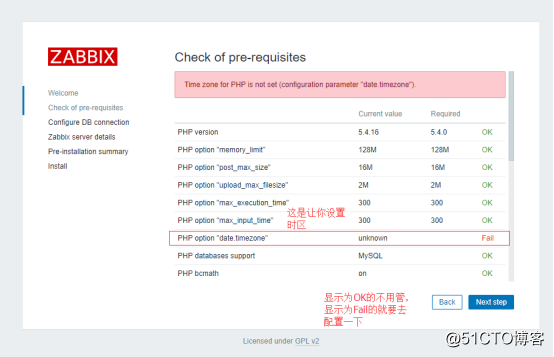
在php的配置文件里设置时区:
[root@localhost ~]$ vim /etc/php.ini
date.timezone = Asia/Shanghai
[root@localhost ~]$ systemctl restart httpd.service
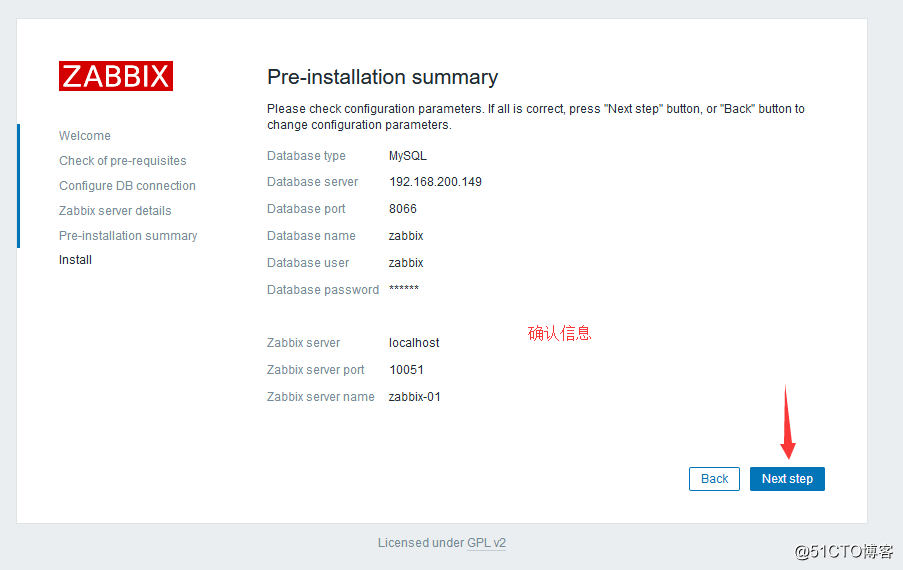
重启完之后刷新浏览器的页面:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
![搭建一个高可用负载均衡的集群架构(第二部分)]()
![搭建一个高可用负载均衡的集群架构(第二部分)]()
![搭建一个高可用负载均衡的集群架构(第二部分)]()
![搭建一个高可用负载均衡的集群架构(第二部分)]()
如果出现502错误的话重新刷新页面即可
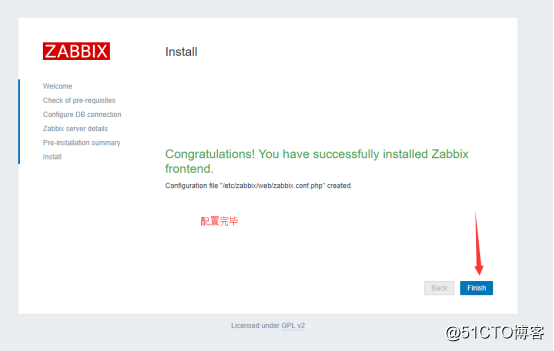
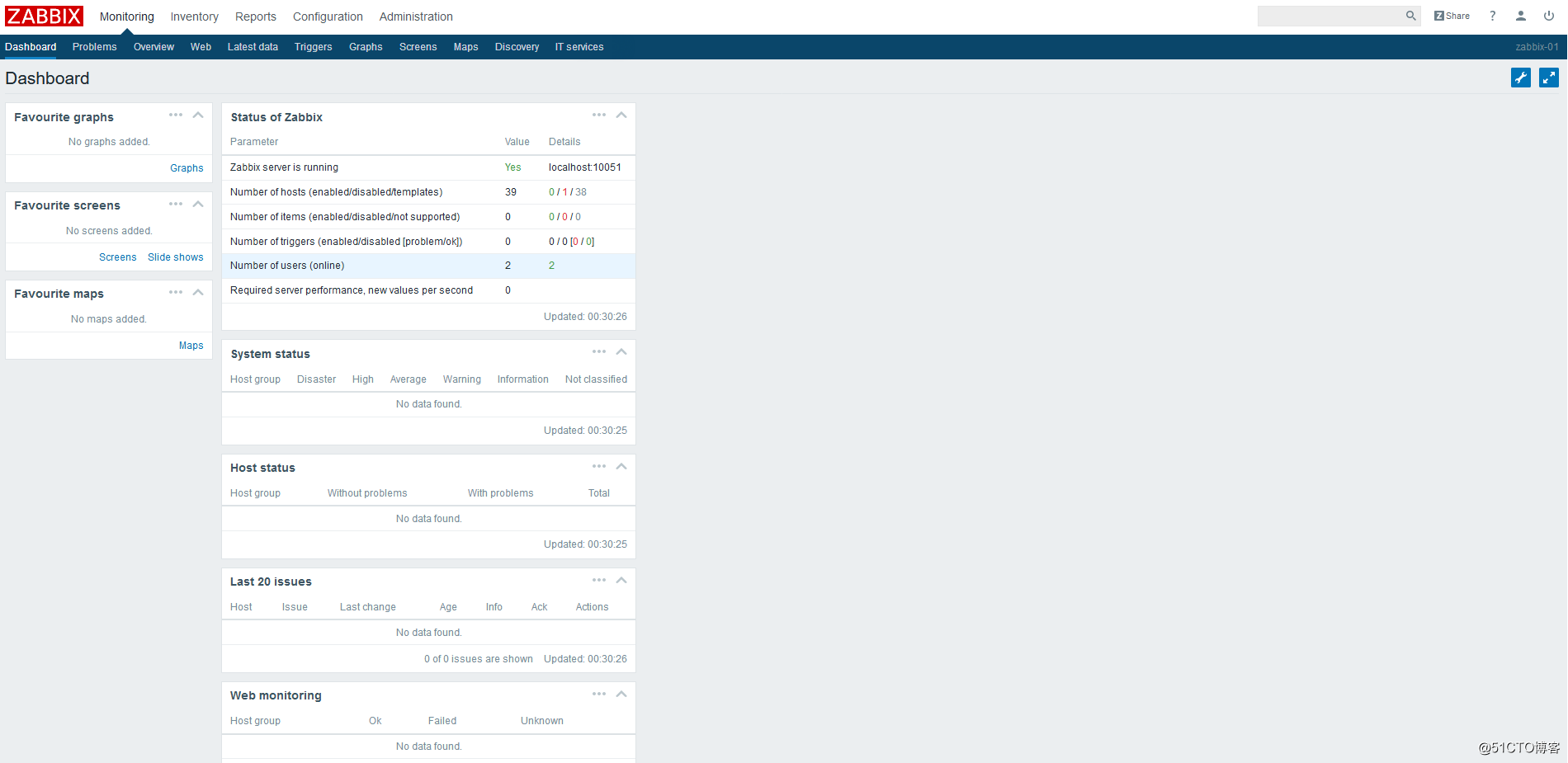
配置完之后就可以登录了,管理员账户是Admin,默认密码是zabbix:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
登录之后的界面:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
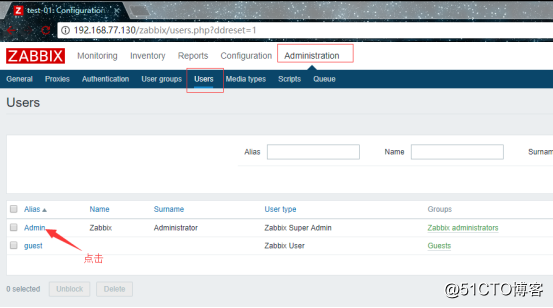
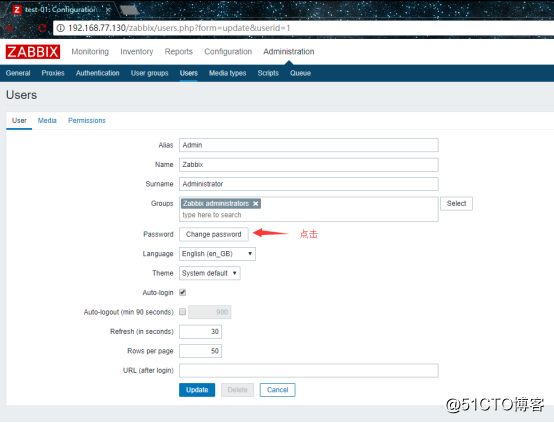
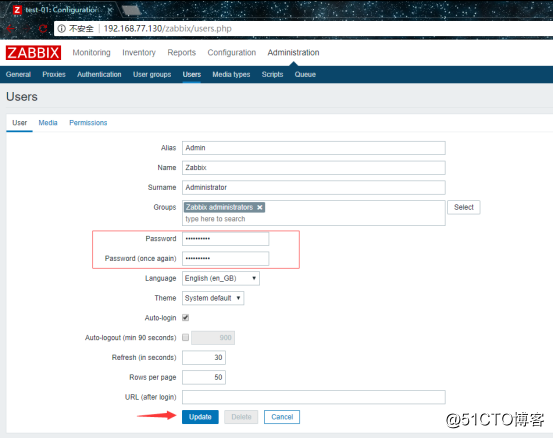
登录之后就是修改Admin的密码,因为这时候密码是一个默认密码:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
![搭建一个高可用负载均衡的集群架构(第二部分)]()
![搭建一个高可用负载均衡的集群架构(第二部分)]()
可以在Language选项框中把语言设置为中文。
ok,以上步骤就把服务端安装好了。
所以现在还需要安装客户端,因为在之前已经把客户端安装了,现在就是配置一下配置文件然后进行启动了:
1.编辑客户端的配置文件:
[root@localhost ~]$ vim /etc/zabbix/zabbix_agentd.conf
Server=192.168.200.152 //定义服务端的ip(被动模式)
ServerActive=192.168.200.152 //定义服务端的ip(主动模式)
Hostname=WebServer2 //这是自定义的主机名,一会还需要在web界面下设置同样的主机名
2.修改完之后保存退出后,启动客户端:
[root@localhost ~]$ systemctl start zabbix-agent
[root@localhost ~]$ systemctl enable zabbix-agent
Created symlink from /etc/systemd/system/multi-user.target.wants/zabbix-agent.service to /usr/lib/systemd/system/zabbix-agent.service.
[root@localhost ~]$ ps aux |grep zabbix
[root@localhost ~]$ netstat -lntp |grep 10050
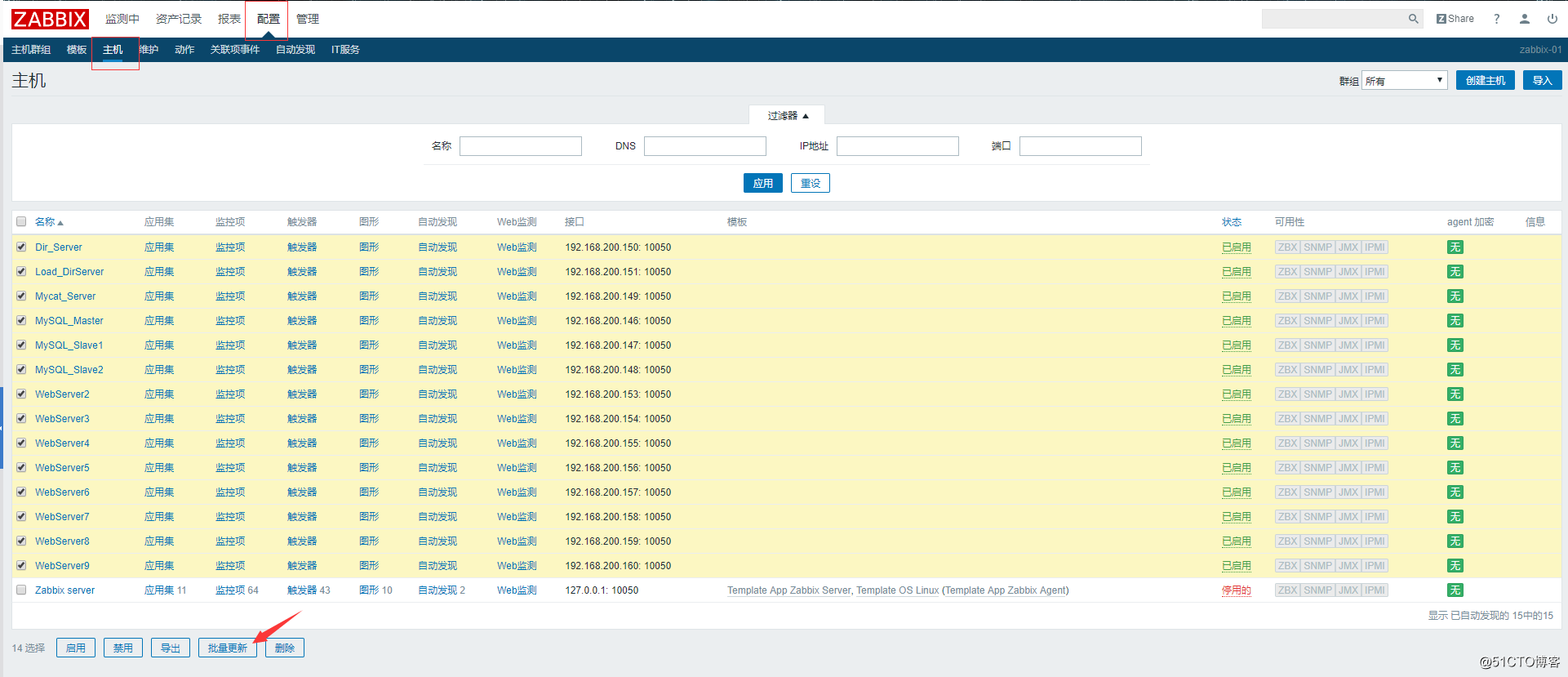
3.批量同步配置文件到其他机器上。
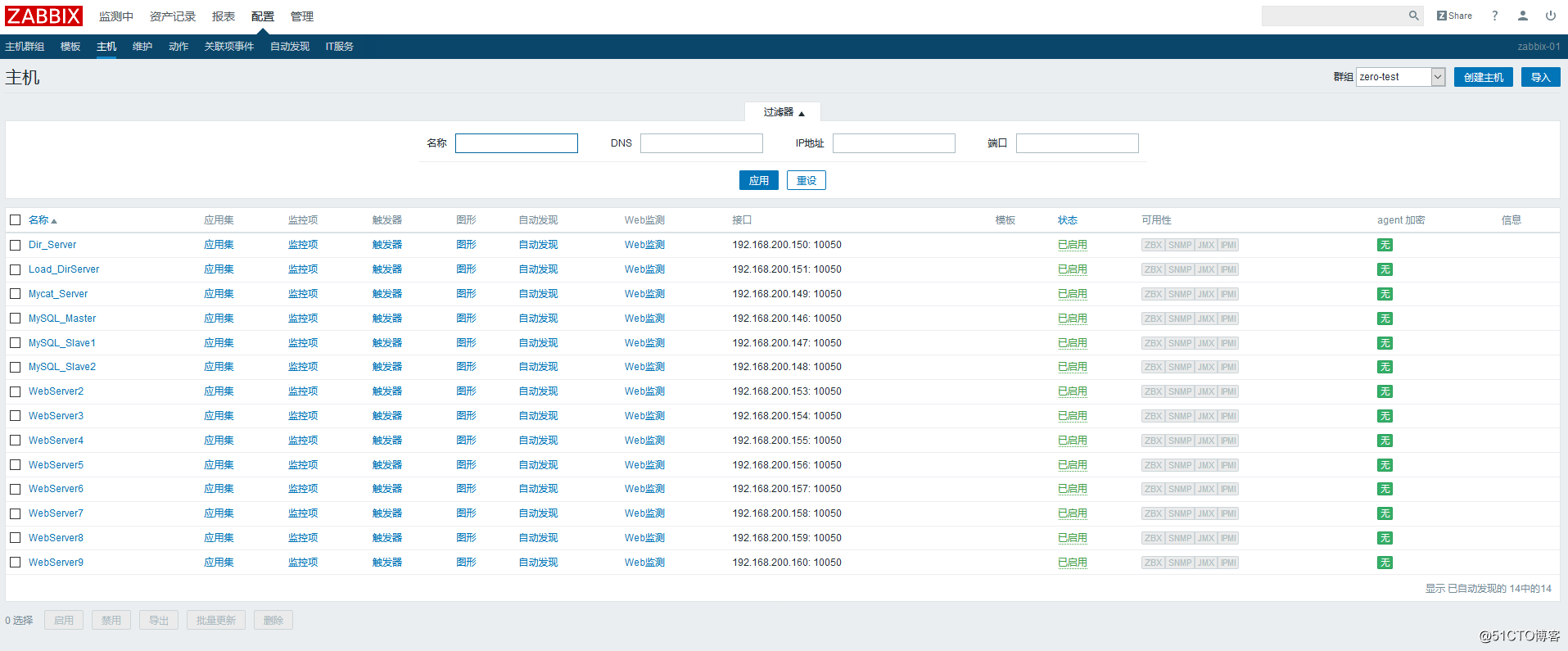
回到web页面上,开始添加监控主机,将这些客户端都添加进去
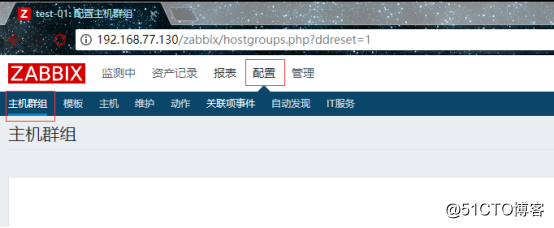
1.先添加主机群组:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
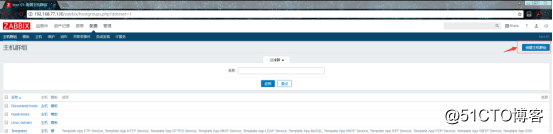
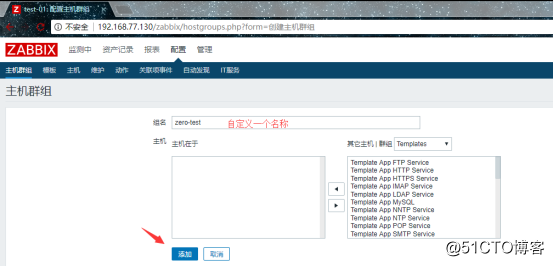
创建一个主机群组:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
![搭建一个高可用负载均衡的集群架构(第二部分)]()
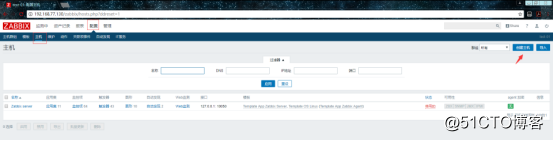
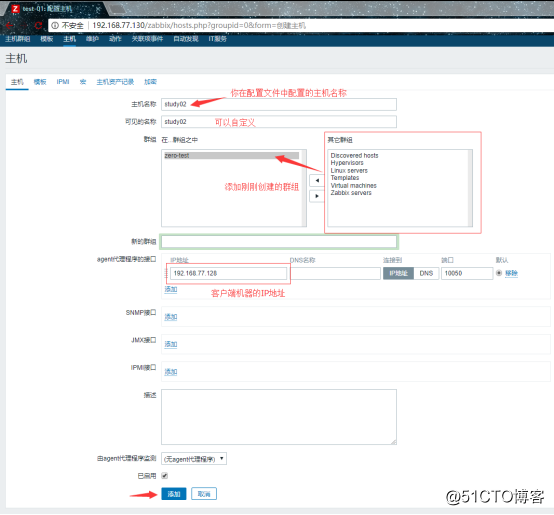
然后再点击主机进行创建主机:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
![搭建一个高可用负载均衡的集群架构(第二部分)]()
![搭建一个高可用负载均衡的集群架构(第二部分)]()
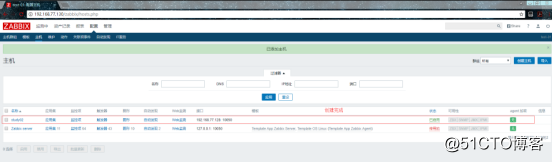
然后就是重复的逐个添加监控主机了。
添加完之后:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
添加完监控主机后,添加一个自定义模板,方便给新增的监控主机添加监控项目
1.创建一个模板:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
![搭建一个高可用负载均衡的集群架构(第二部分)]()
2.添加完之后从自带的模板中,找一些监控项,将这些监控项复制到自定义模板中,在 ”模板“ 页面中往下拉,找到emplate OS Linux,然后点击监控项:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
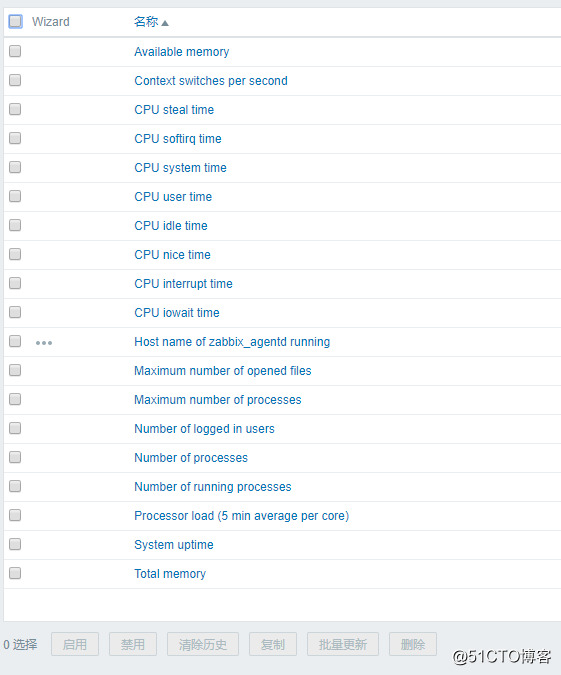
3.进入 “监控项” 页面后,往下拉,逐个勾选以下项目:
Available memory
Context switches per second
CPU user time
CPU nice time
CPU system time
CPU iowait time
CPU idle time
CPU interrupt time
CPU steal time
CPU softirq time
Template App Zabbix Agent: Host name of zabbix_agentd running
Maximum number of opened files
Maximum number of processes
Number of logged in users
Number of processes
Number of running processes
Processor load (5 min average per core)
System uptime
Total memory
勾选完之后点击下面的 “复制” ,复制到自定义的模板中:
复制到自定义的模板中
然后再去看你的自定义模板就会发现有了19项监控项:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
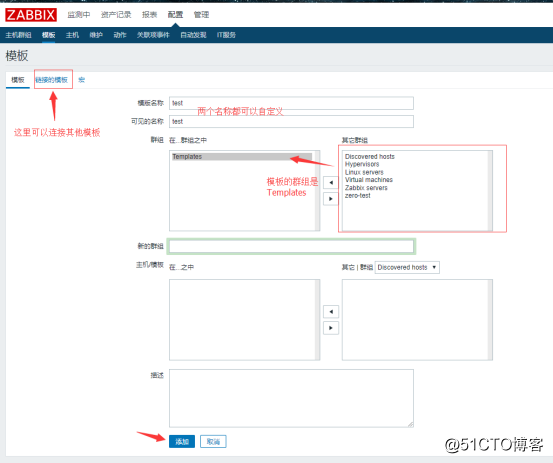
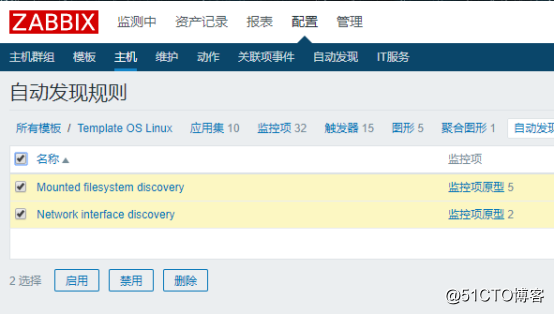
同样的,可以使用相同的方法,把触发器、图形、聚合图形、自动发现,给复制到自定义模板中。但是有一点要注意的是,自动发现里的规则不能直接复制,因为没有复制的按钮:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
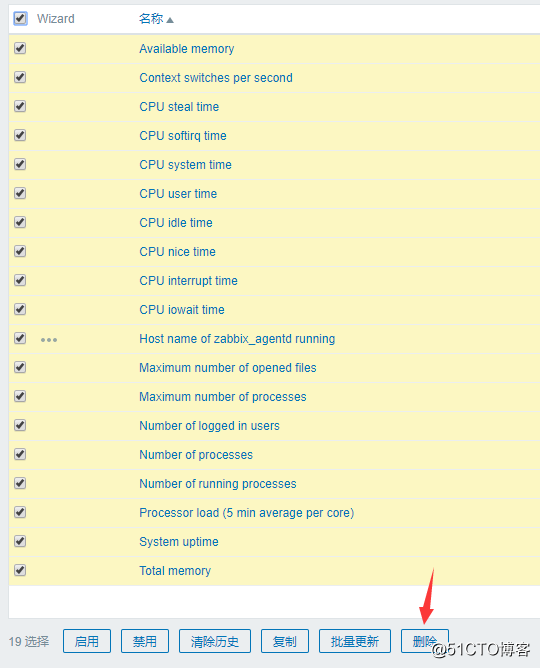
所以我们先把刚刚添加到自定义模板里的监控项给删掉:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
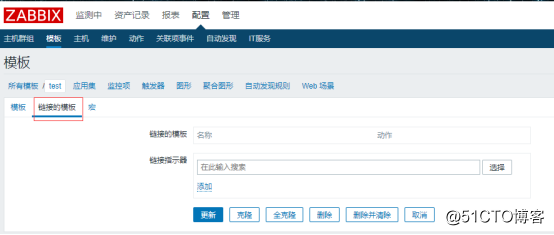
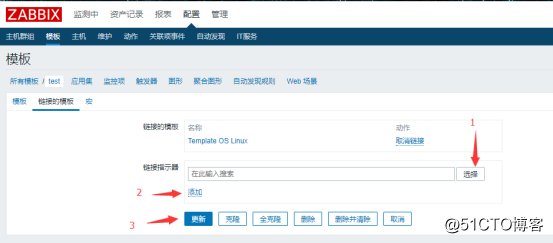
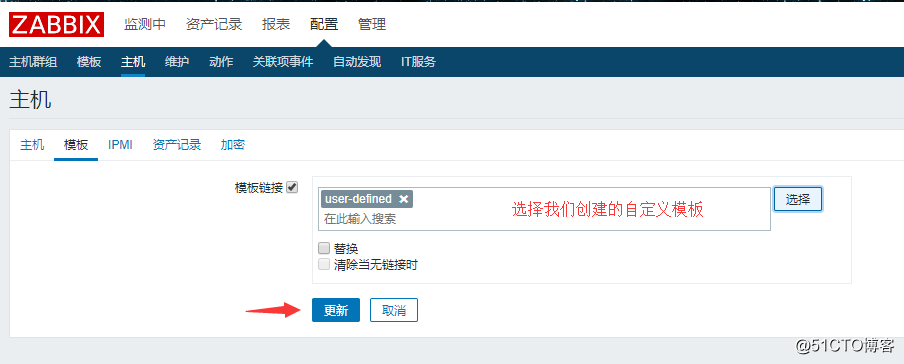
然后编辑这个模板,点击链接的模板:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
然后选择一个链接模板,并点击添加,接着点击更新:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
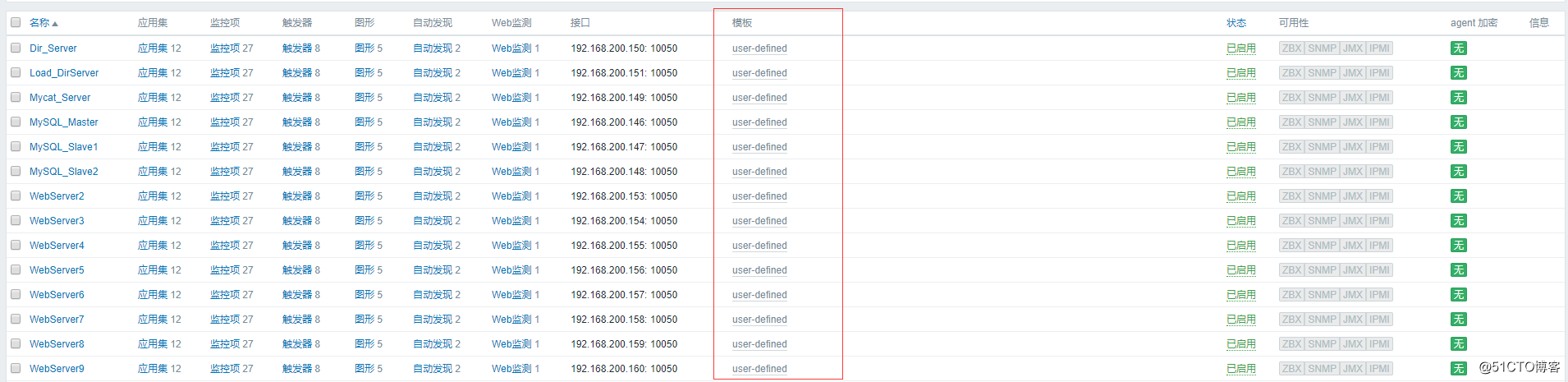
这时候就会发现自定义模板中所有项的数量都和Template OS Linux模板一样了,这是因为把Template OS Linux里的东西都完整的复制了过来:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
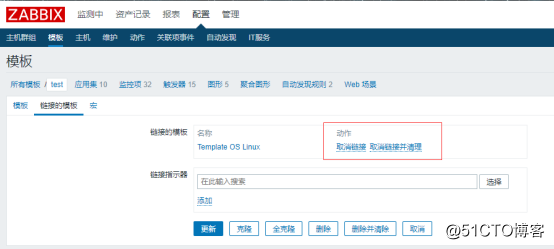
如果你的模板不需要这么多的项目,想要删除掉一些的话,是不能够直接删除的,删除的方法参照以下示例:
1.进入到连接的模板界面中,在动作那一栏有取消连接和取消连接并清理:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
其中取消链接只是单纯的把链接给取消掉,不会把你自定义模板中项目给清空,而取消连接并清理则是会把项目给清空。
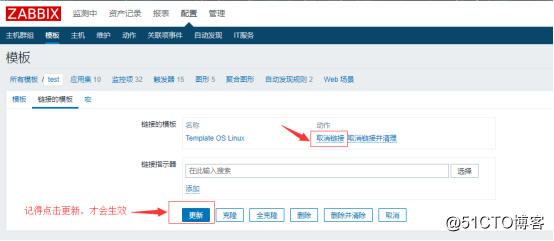
2.所以点击取消连接即可:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
3.这时候就可以直接去删除不需要的项目了:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
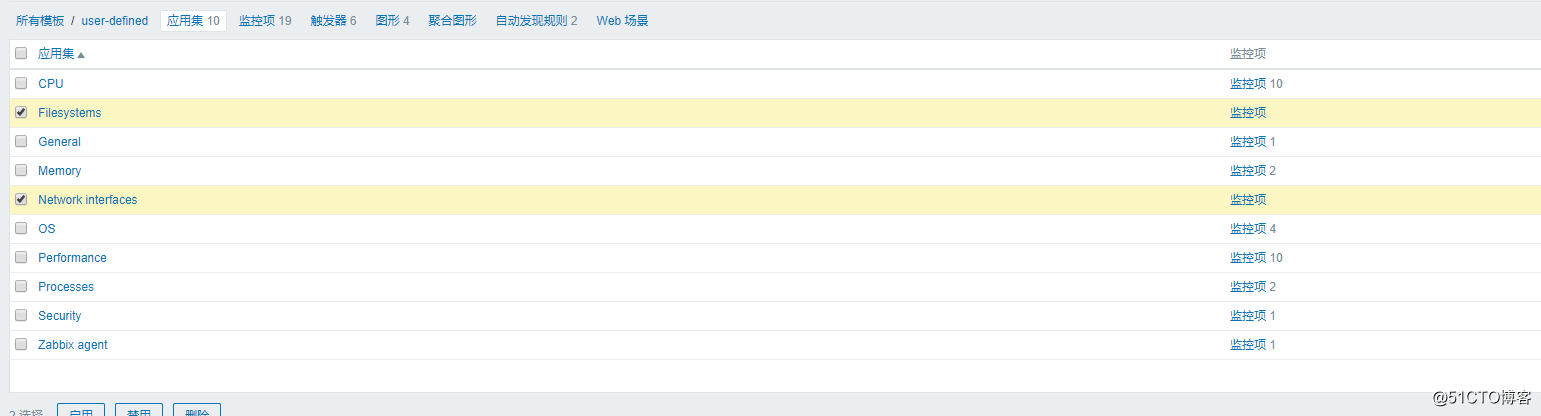
关于删除应用集:想要删除某个应用集时,需要先把应用集里面的监控删掉后,才能删除应用集。
例如我刚刚删除了一些监控项,只留下了之前勾选的那些:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
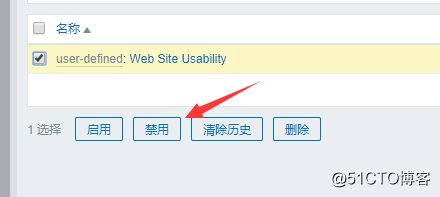
然后到应用集中,只要监控项为空的,就可以删除:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
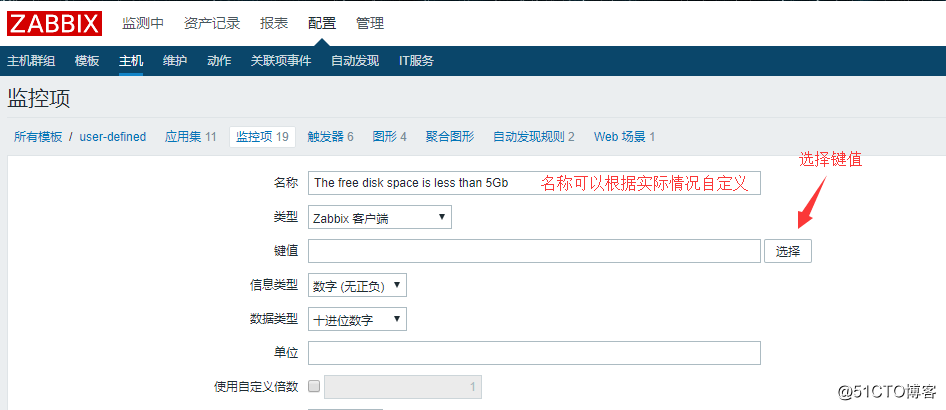
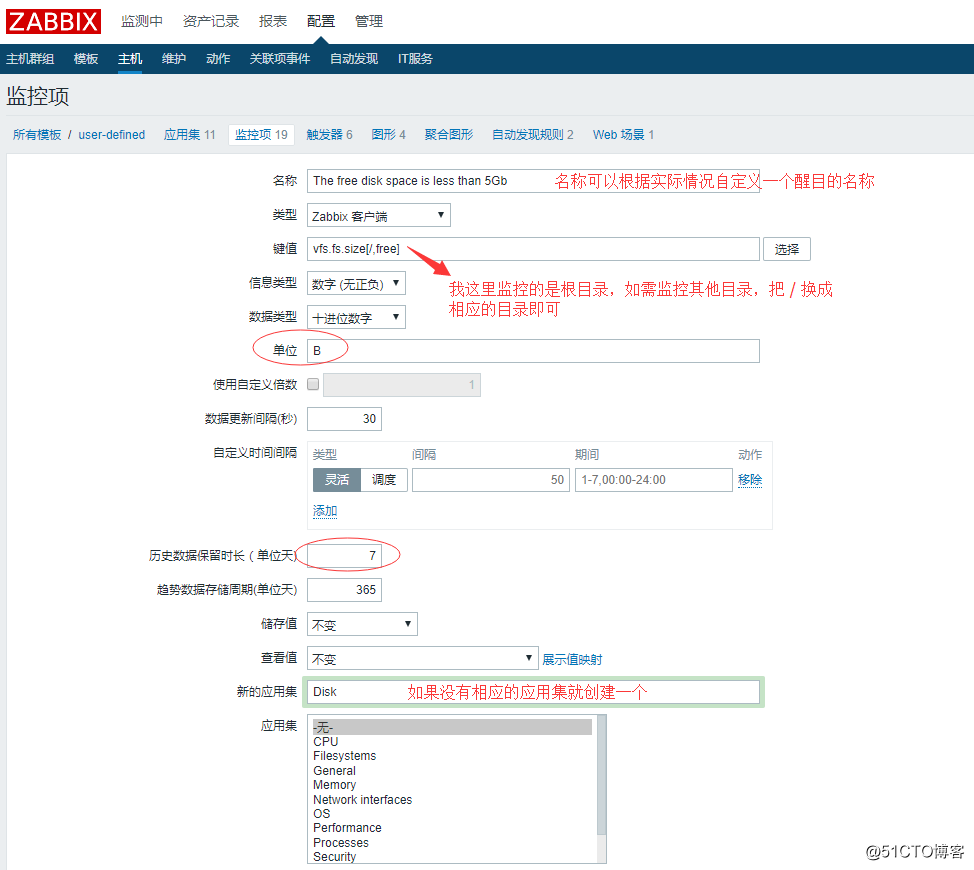
创建监控项监控磁盘剩余空间以及内存剩余空间
zabbix自带有一个监控指标可以监控磁盘剩余空间,所以我们现在要创建一个监控项来监控这个指标,点击创建监控项,进入到以下界面:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
![搭建一个高可用负载均衡的集群架构(第二部分)]()
![搭建一个高可用负载均衡的集群架构(第二部分)]()
最后点击添加即可。
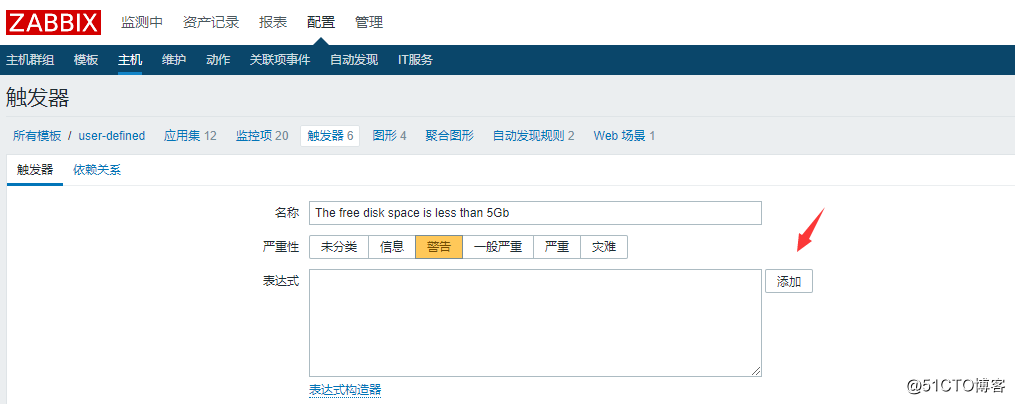
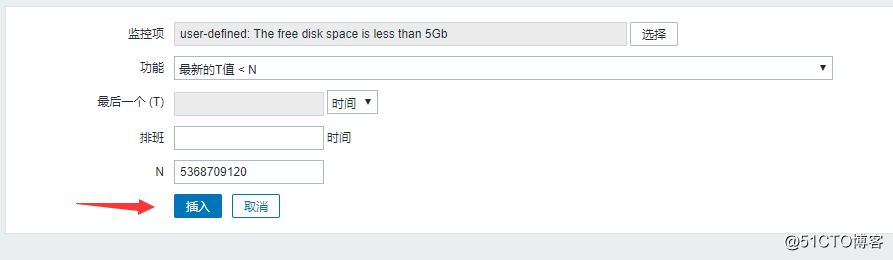
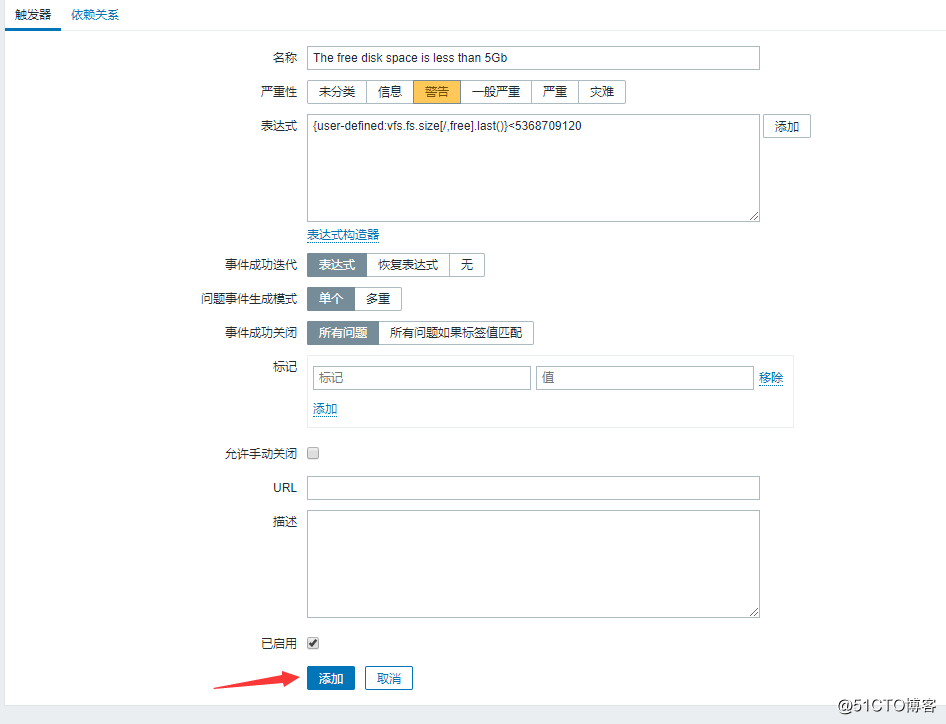
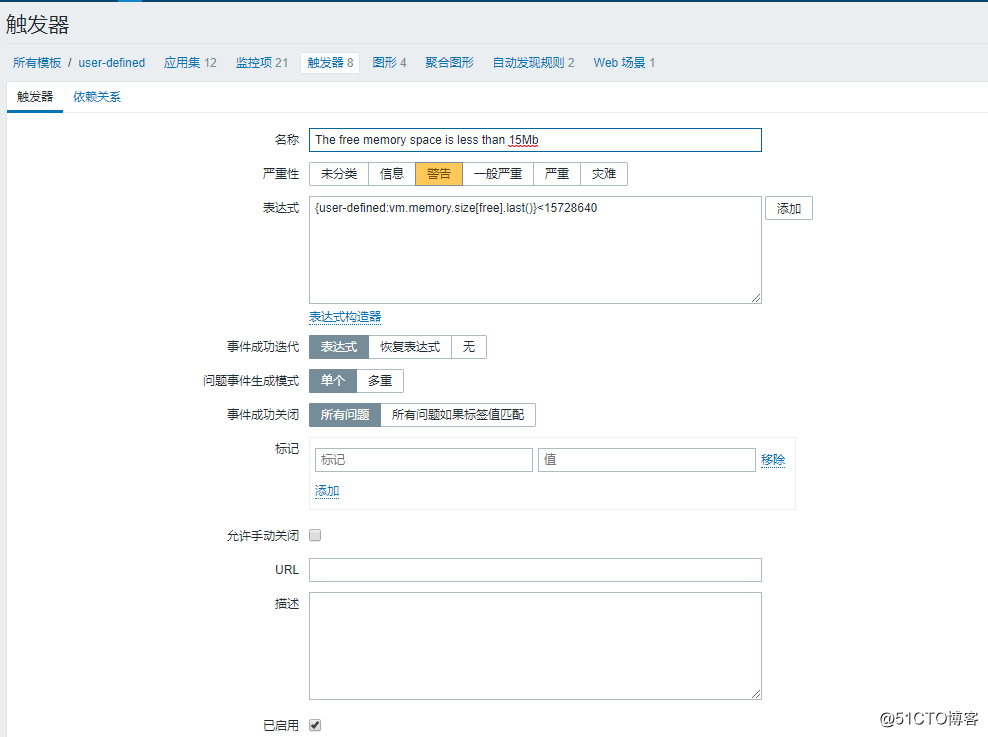
然后再创建一个触发器:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
![搭建一个高可用负载均衡的集群架构(第二部分)]()
![搭建一个高可用负载均衡的集群架构(第二部分)]()
![搭建一个高可用负载均衡的集群架构(第二部分)]()
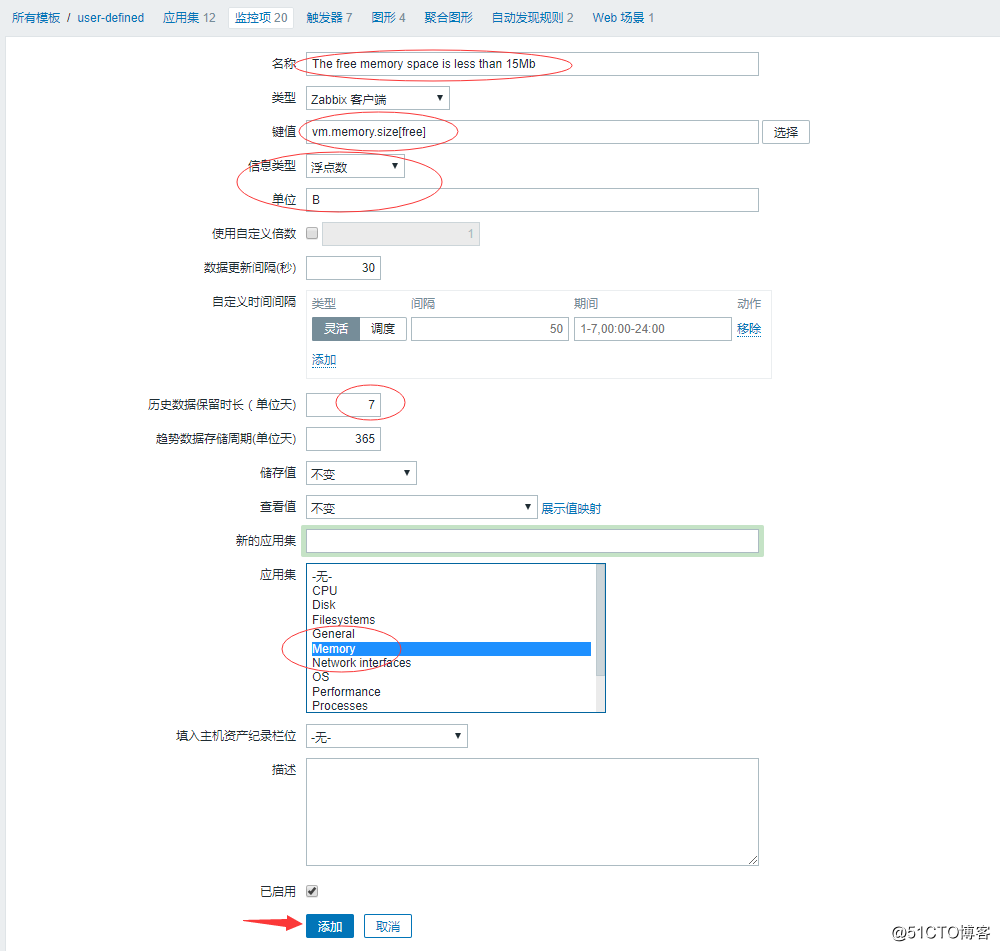
zabbix也自带有一个监控指标可以监控内存剩余空间,同样的创建过程和上面一样:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
![搭建一个高可用负载均衡的集群架构(第二部分)]()
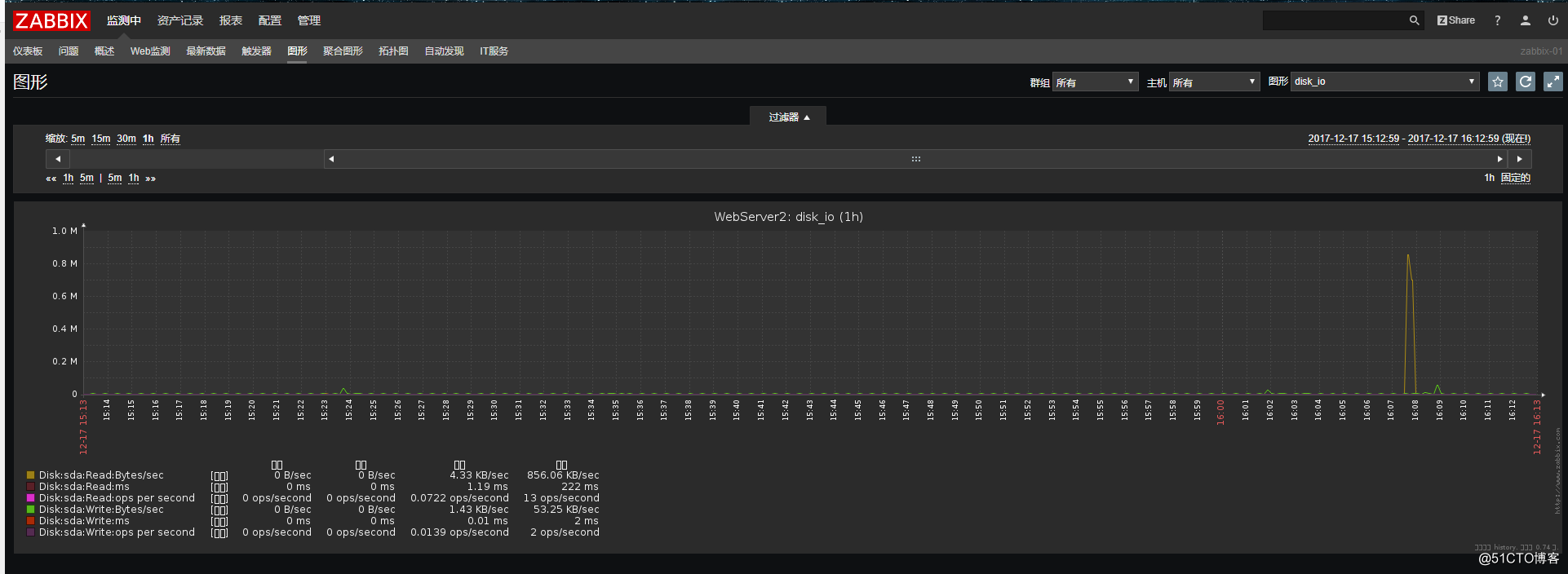
Zabbix自带的“Template OS Linux”模板,都是一些比较常用的监控项,现在我们如果想要监控我们磁盘的IO,这时候zabbix并没有给我们提供这么一个模板,所以我们还需要自己来创建自定义监控项来完成磁盘IO的监控。
1.在客户端机器的 /etc/zabbix/zabbix_agentd.d,目录下添加 userparameter_io.conf 配置文件, 文件内容如下:
[root@localhost ~]$ vim /etc/zabbix/zabbix_agentd.d/userparameter_io.conf
UserParameter=custom.vfs.dev.read.ops[*],cat /proc/diskstats | grep $1 | head -1 | awk '{print $$4}'
//磁盘读的次数
UserParameter=custom.vfs.dev.read.ms[*],cat /proc/diskstats | grep $1 | head -1 | awk '{print $$7}'
//磁盘读的毫秒数
UserParameter=custom.vfs.dev.write.ops[*],cat /proc/diskstats | grep $1 | head -1 | awk '{print $$8}'
//磁盘写的次数
UserParameter=custom.vfs.dev.write.ms[*],cat /proc/diskstats | grep $1 | head -1 | awk '{print $$11}'
//磁盘写的毫秒数
UserParameter=custom.vfs.dev.io.active[*],cat /proc/diskstats | grep $1 | head -1 | awk '{print $$12}'
//I/O的当前进度,只有这个域应该为0
UserParameter=custom.vfs.dev.io.ms[*],cat /proc/diskstats | grep $1 | head -1 | awk '{print $$13}'
//花费在IO操作上的毫秒数
UserParameter=custom.vfs.dev.read.sectors[*],cat /proc/diskstats | grep $1 | head -1 | awk '{print $$6}'
//读扇区的次数(一个扇区的等于512B)
UserParameter=custom.vfs.dev.write.sectors[*],cat /proc/diskstats | grep $1 | head -1 | awk '{print $$10}'
//写扇区的次数(一个扇区的等于512B)
2.完成之后重启zabbix-agent服务:
systemctl restart zabbix-agent
3.到zabbix服务端上使用以下命令测试能否获得数据:
zabbix_get -s 192.168.200.153 -p 10050 -k custom.vfs.dev.write.ops[sda]
ip是目标客户端机器的ip
4.测试正常后通过脚本将该配置文件同步到其他客户端机器上,同步之后也需要重启服务。
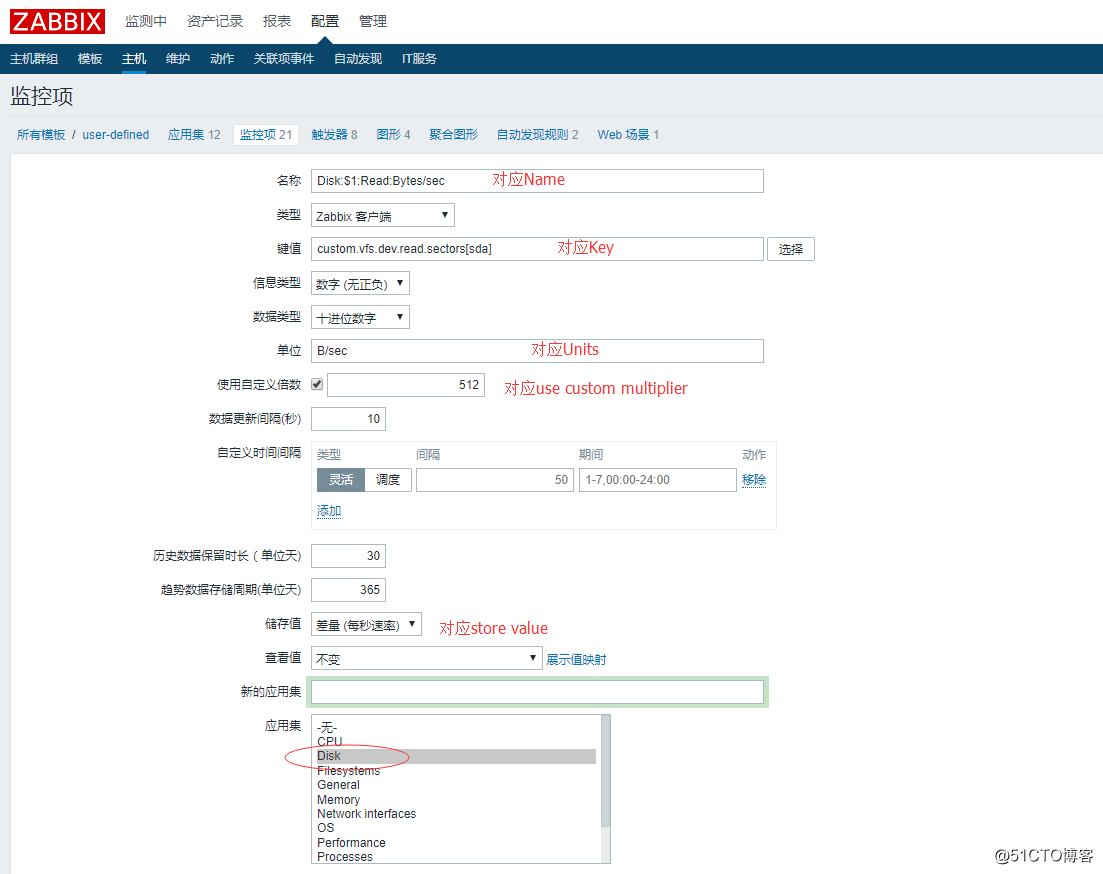
5.回到服务端的web页面上,配置监控项:
配置第一个监控项:
Name: Disk:$1:Read:Bytes/sec
Key: custom.vfs.dev.read.sectors[sda]
Units: B/sec
Store value: speed per second //会进行差值计算
Use custom multiplier 512 //会对值乘以512,因为这里是一个扇区,转换为字节为512B
![搭建一个高可用负载均衡的集群架构(第二部分)]()
第二监控项:和第一个一样的配置过程
Name:Disk:$1:Write:Bytes/sec
Key: custom.vfs.dev.write.sectors[sda]
Units: B/sec
Store value: speed per second
Use custom multiplier 512
第三个监控项配置参数:
Name:Disk:$1:Read:ops per second
Key: custom.vfs.dev.read.ops[sda]
Units: ops/second
Store value: speed per second
第四个监控项配置参数:
Name: Disk:$1:Write:ops per second
Key: custom.vfs.dev.write.ops[sda]
Units: ops/second
Store value: speed per second
第五个监控项配置参数:
Name: Disk:$1:Read:ms
Key: custom.vfs.dev.read.ms[sda]
Units: ms
Store value: speed per second
第六个监控项配置参数:
Name:Disk:$1:Write:ms
Key: custom.vfs.dev.write.ms[sda]
Units: ms
Store value: speed per second
添加完毕:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
上面我们就完成了对IO的监控,但是我们也想和zabbix自带的那样的模板一样,可以看到监控以后的图形,当然这也是可以做到的,下面就介绍图形的添加。
添加图形
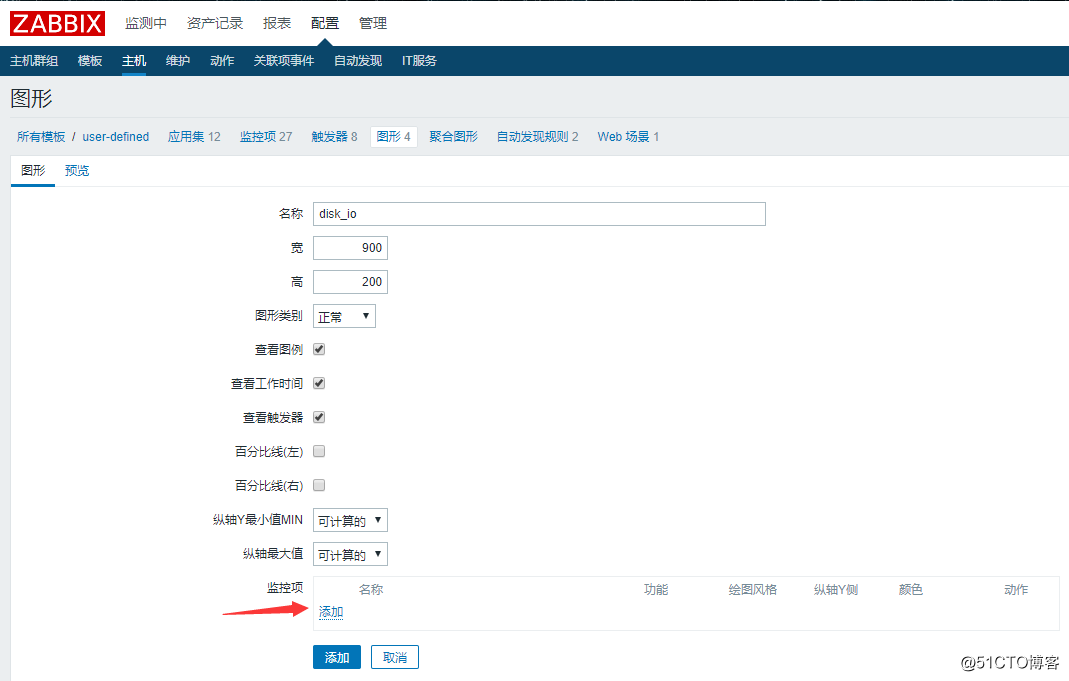
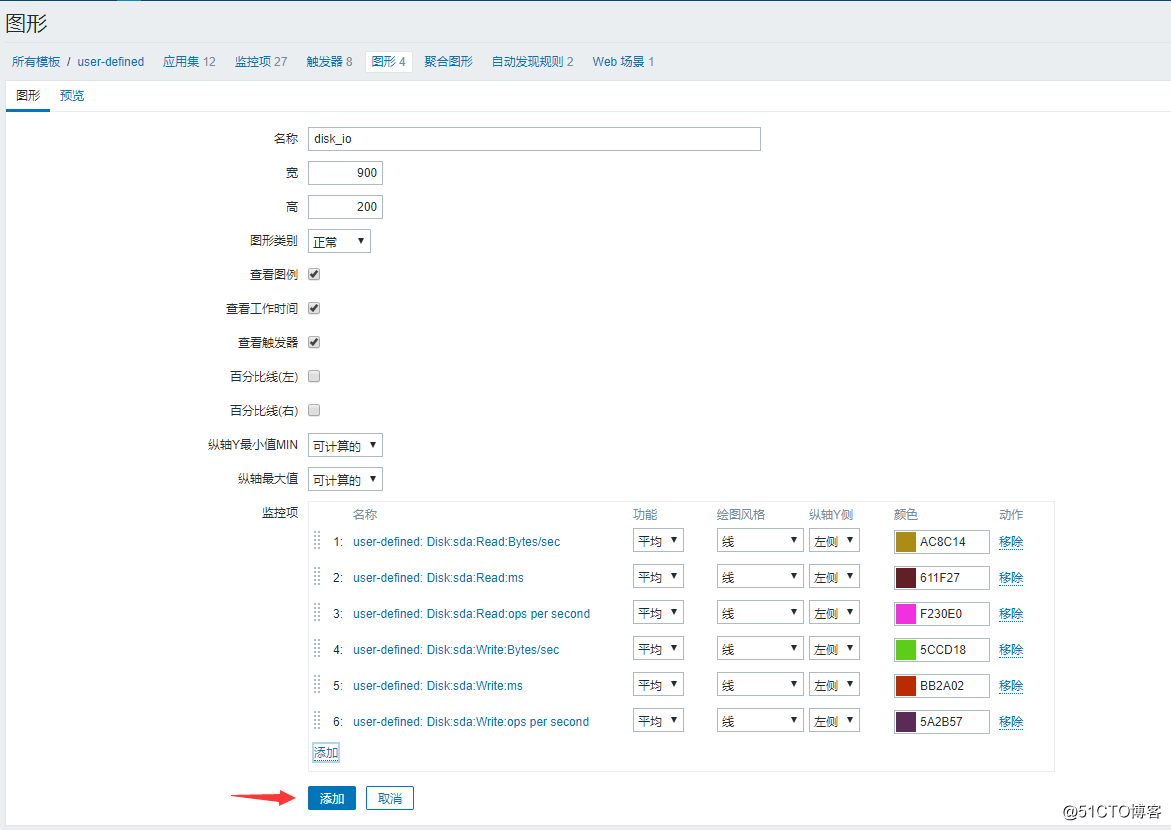
返回到模板的列表页面,找到我们创建的模板然后点击后面的图形—》创建图形:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
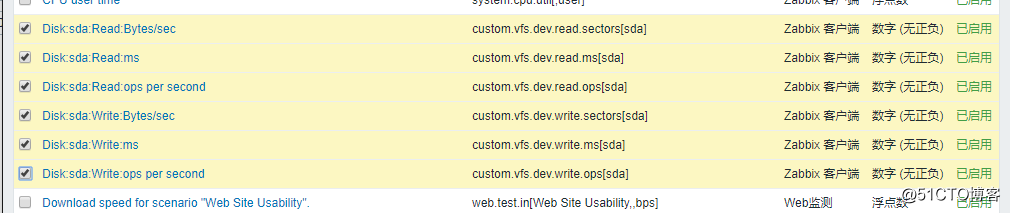
选择刚刚添加的六个监控项:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
![搭建一个高可用负载均衡的集群架构(第二部分)]()
以上添加完了基本的监控项目后,我们还需要监控web站点的可用性,所以需要添加web监测:
1.找到你的自定义模板点击web监测:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
2.点击右上角的创建web场景:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
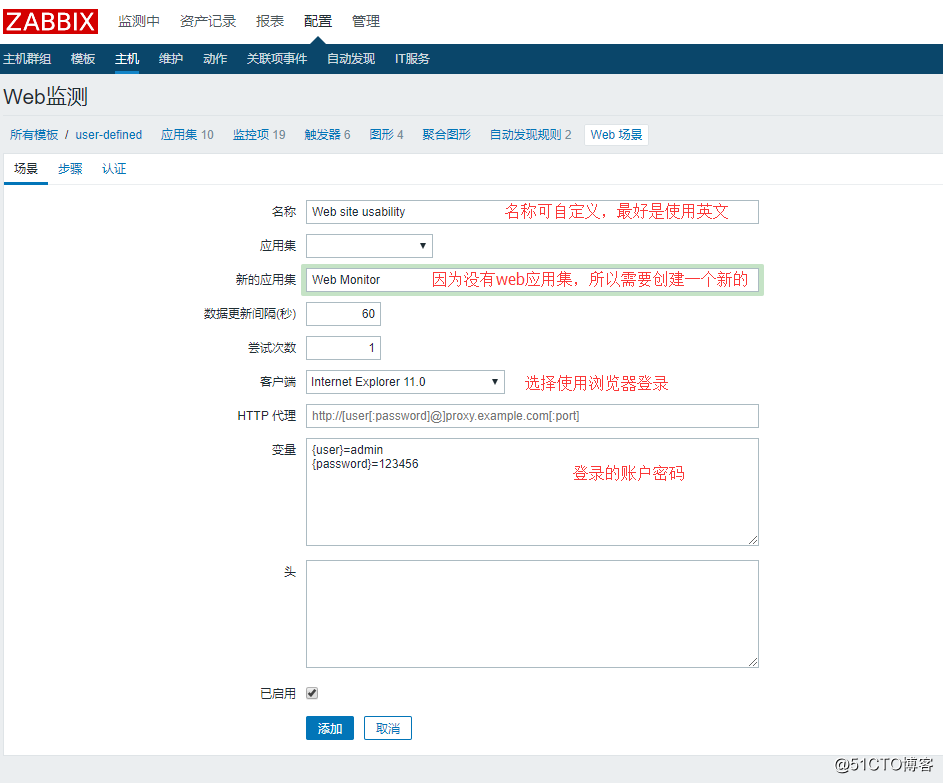
3.输入相应的信息
![搭建一个高可用负载均衡的集群架构(第二部分)]()
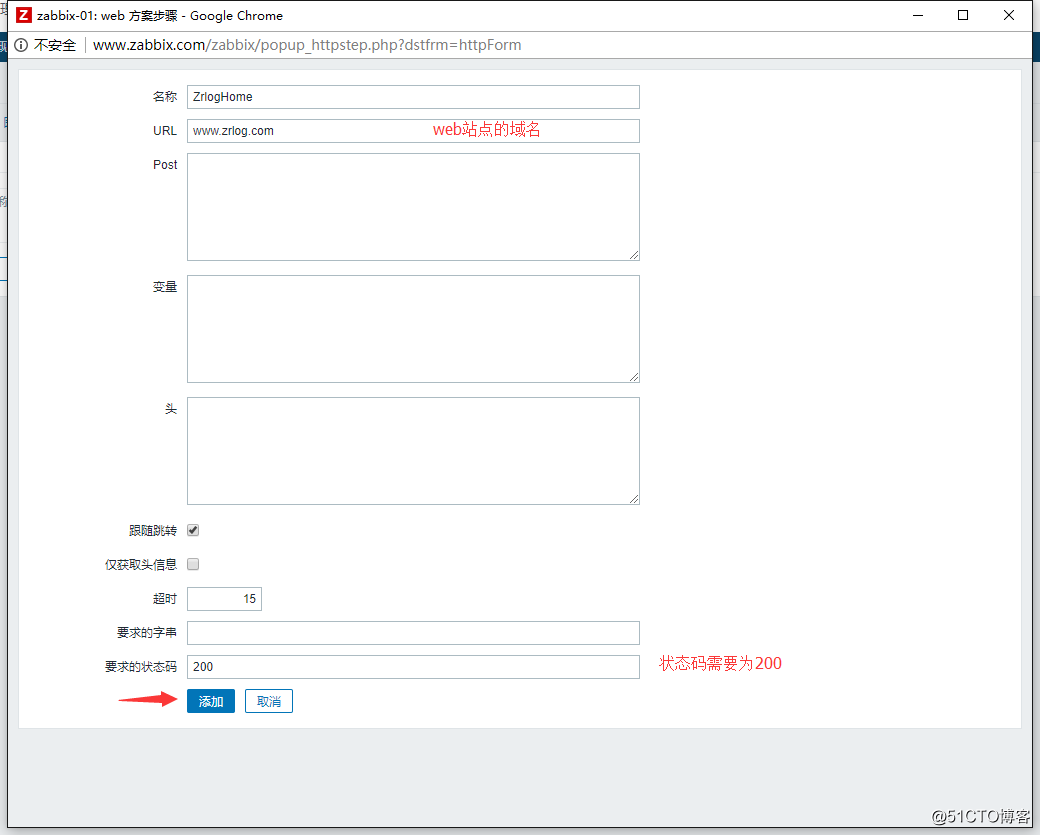
4.添加步骤,添加一个访问站点首页的监控:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
![搭建一个高可用负载均衡的集群架构(第二部分)]()
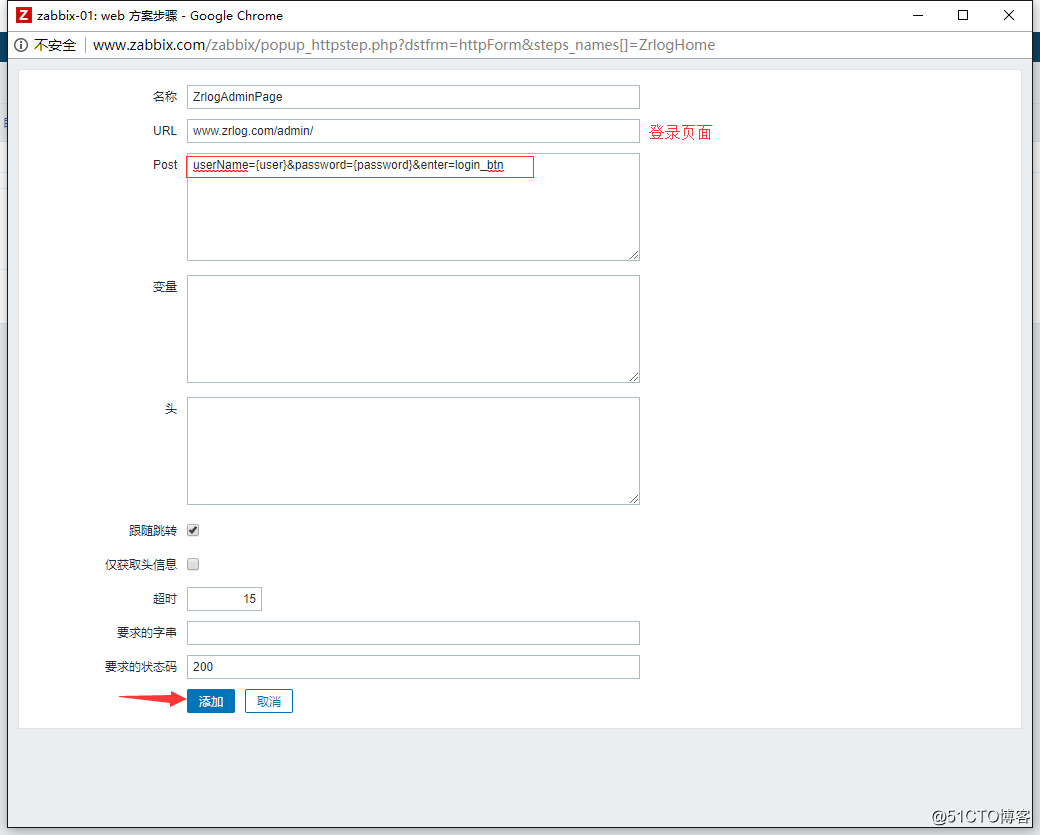
5.然后再设置模拟登陆,在设置模拟登陆之前,我们首先要查看一下待监控网站的源代码,以便获取Post账号密码信息的name和id值:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
根据获取的name和id值,设置如下:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
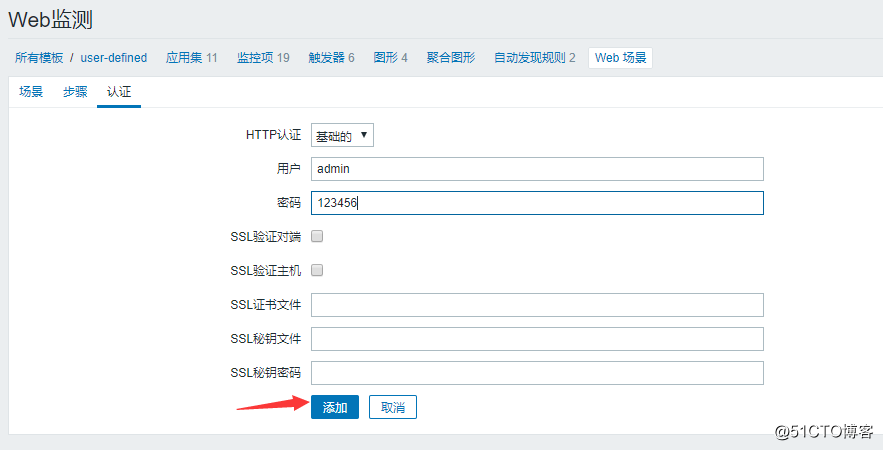
然后再点击认证,选择基础的http认证,最后点击添加:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
其他站点也是如上步骤进行添加,但是如果登录页面有验证码的话就无法使用这种方式模拟登录了,因为验证码是在服务端实时随机生成的。
添加完成,一个站点对应一个web监测:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
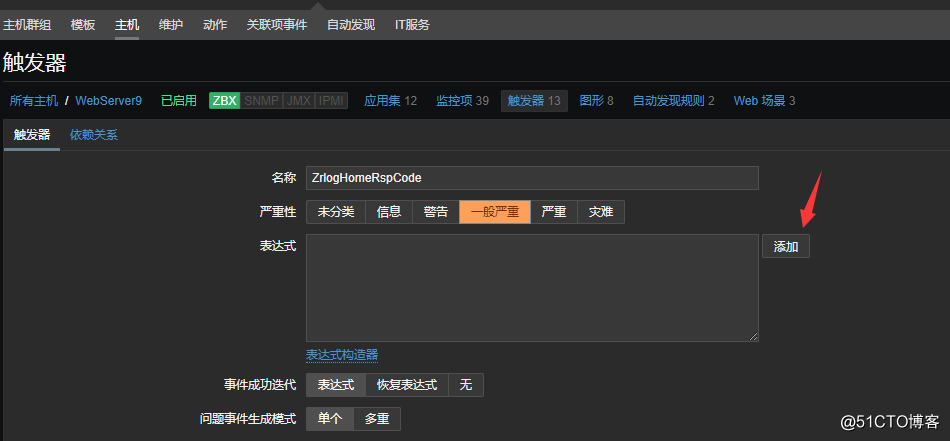
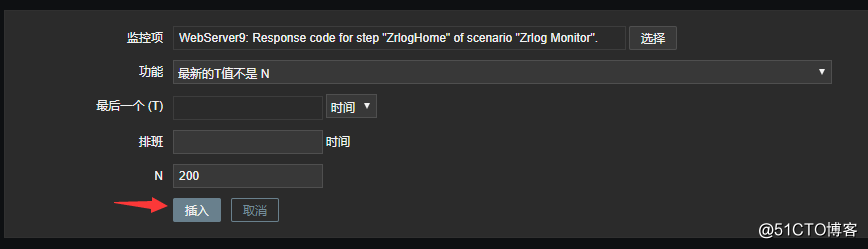
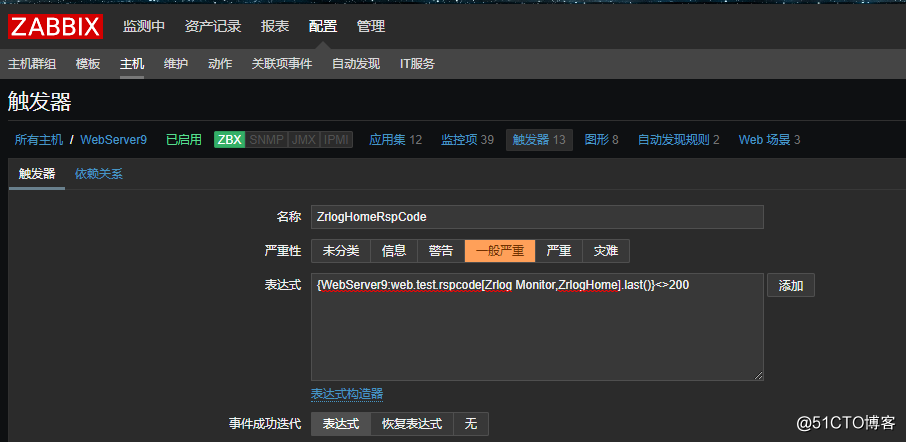
然后添加响应的触发器,例如我添加一个触发器,当zrlog站点返回的状态码不为200就触发:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
![搭建一个高可用负载均衡的集群架构(第二部分)]()
![搭建一个高可用负载均衡的集群架构(第二部分)]()
![搭建一个高可用负载均衡的集群架构(第二部分)]()
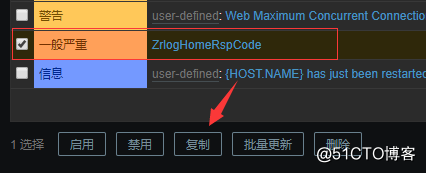
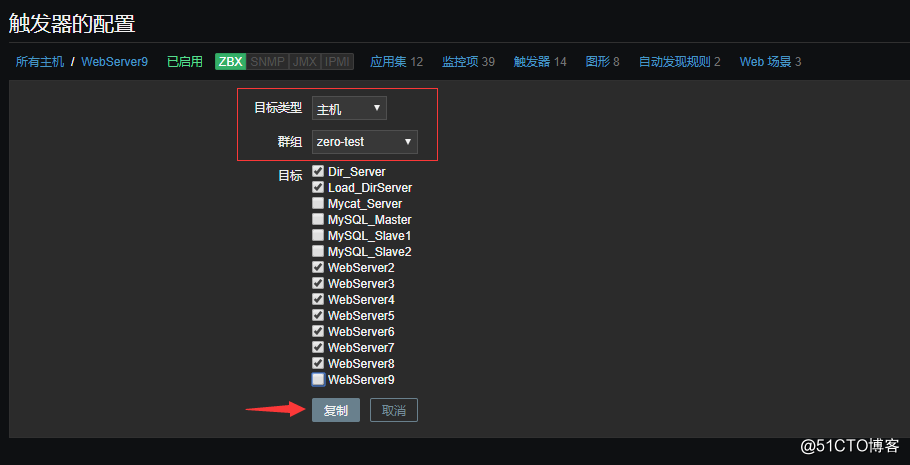
接着复制该触发器到其他主机上,sql服务器不需要复制:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
![搭建一个高可用负载均衡的集群架构(第二部分)]()
然后到zabbix服务端机器上修改/etc/hosts文件,添加一行配置,将这三个域名都指向192.168.200.179
192.168.200.179 www.zrlog.com www.discuz.com www.dedecms.com
接下来就是把一开始创建的主机和这个自定义模板连接起来:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
![搭建一个高可用负载均衡的集群架构(第二部分)]()
连接完毕:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
但是其中的非web机器需要还需要手动去把web监测给禁用。
![搭建一个高可用负载均衡的集群架构(第二部分)]()
现在就可以查看图形了:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
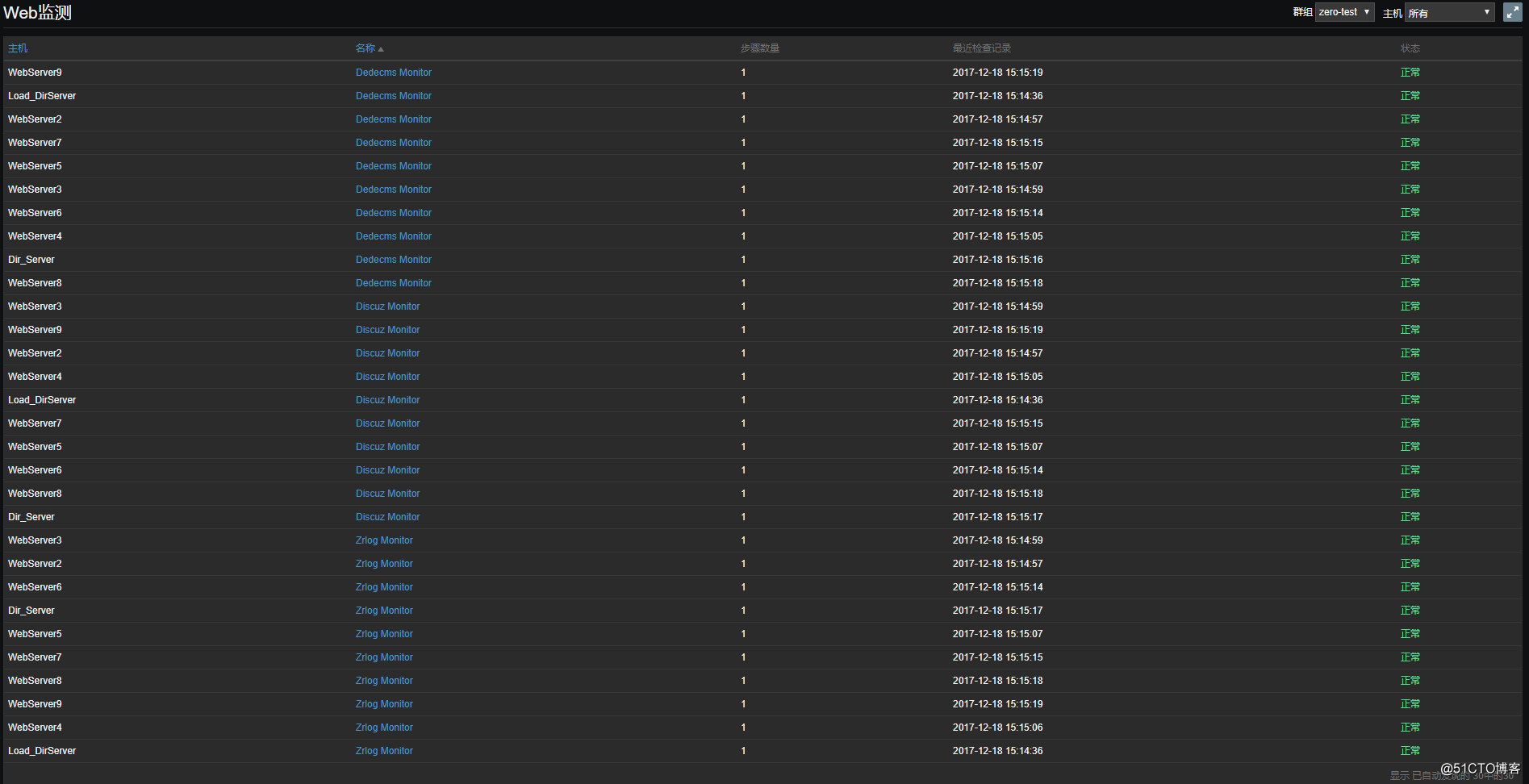
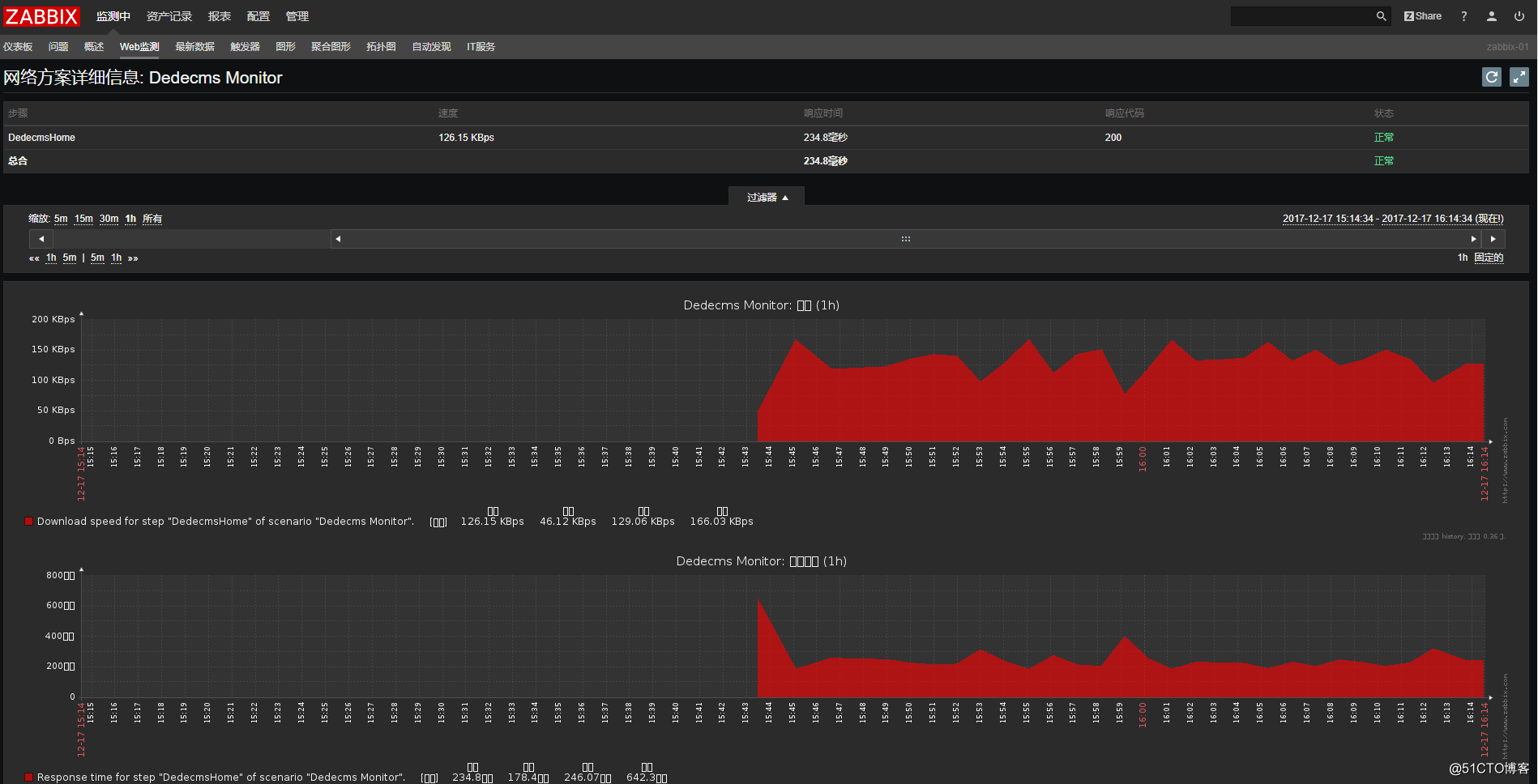
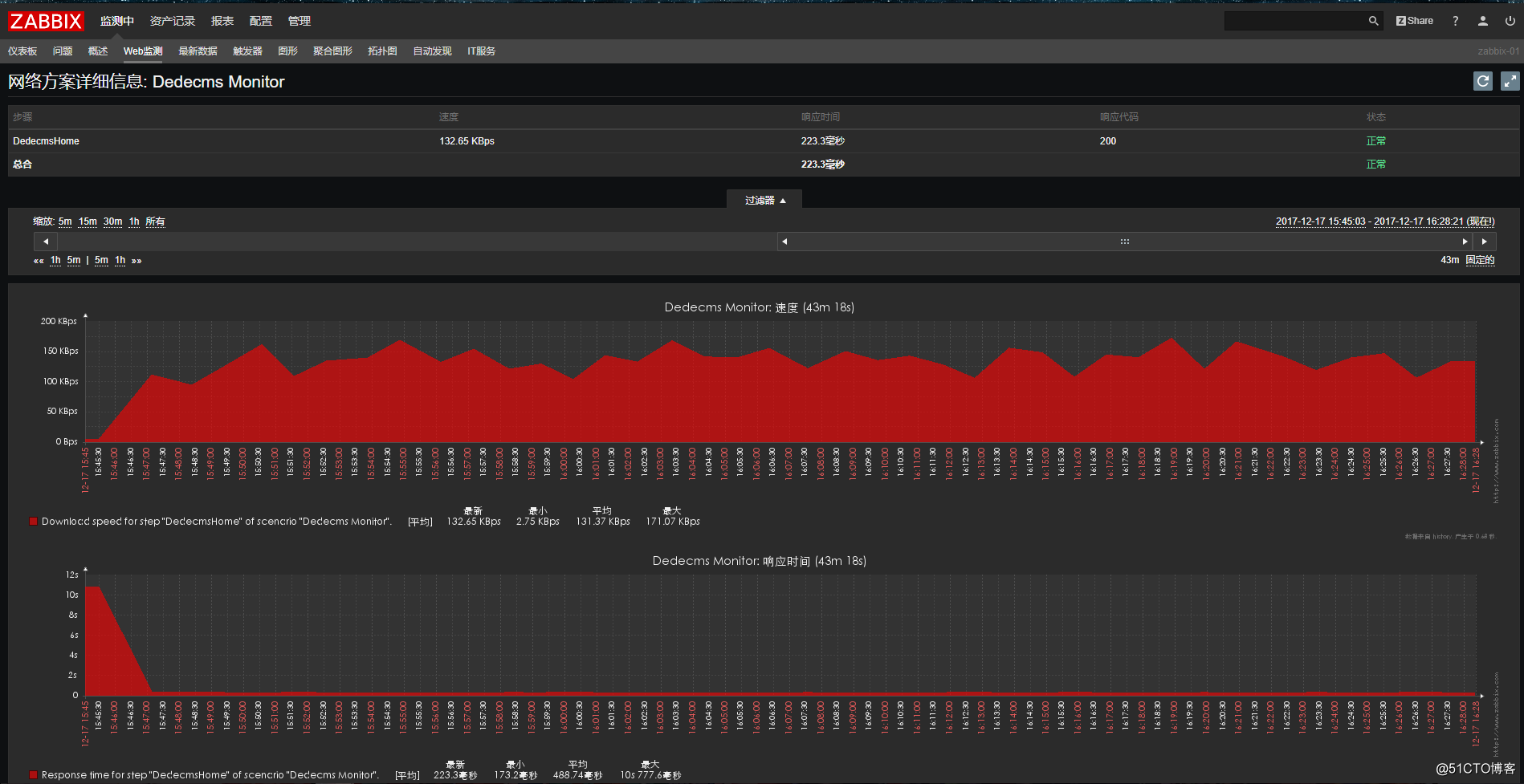
web图形在web监测中查看:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
![搭建一个高可用负载均衡的集群架构(第二部分)]()
但是可以发现图形里的中文无法正常显示,这是因为在zabbix的字体库中没有中文字体,而不是字符集编码的问题,像这种中文文字会显示小方框的情况,是因为没有中文字体库,无法显示中文才用小方框代替。
解决方法:
从windows上借用一个过来即可,windows中的字体放在以下路径:
C:\Windows\Fonts
选择一个中文的字体,复制到桌面上,然后使用xftp上传到Linux中的root目录即可。
然后把这个字体文件放到/usr/share/zabbix/fonts目录下:
mv /root/simkai.ttf /usr/share/zabbix/fonts
接着把/usr/share/zabbix/fonts目录下原本的那个字体文件重命名一下:
cd /usr/share/zabbix/fonts
mv graphfont.ttf graphfont.ttf.bak
把中文字体文件做一个软链接即可:
ln -s simkai.ttf graphfont.ttf
完成以上操作,再刷新一下页面,就可以看到中文正常显示了:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
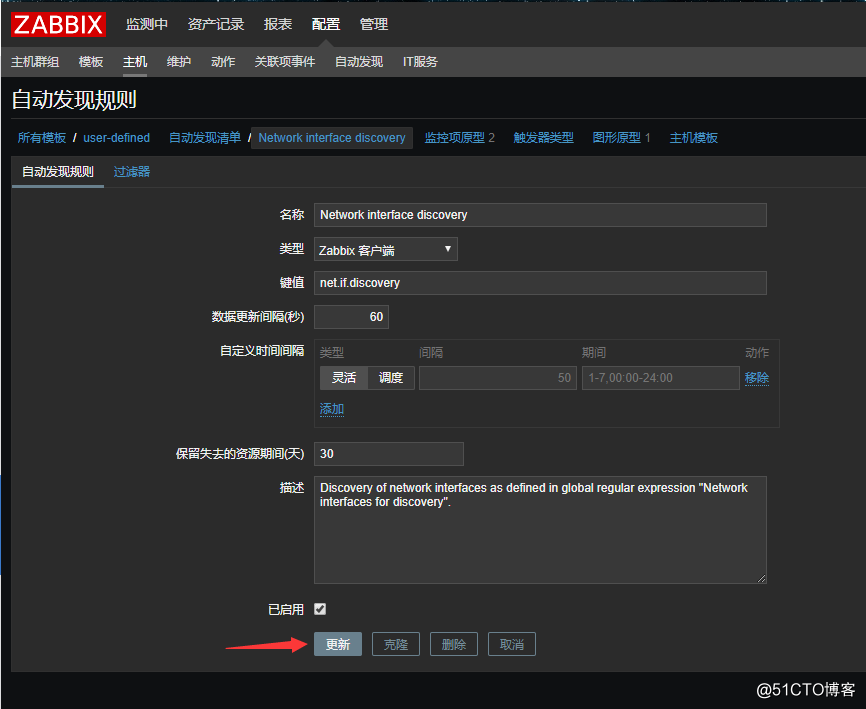
配置自动发现规则的图形,将网卡流量成图:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
然后重启一下客户端的zabbix-agent服务。
systemctl restart zabbix-agent.service
服务端也需要重启一下zabbix-server服务:
systemctl restart zabbix-server.service
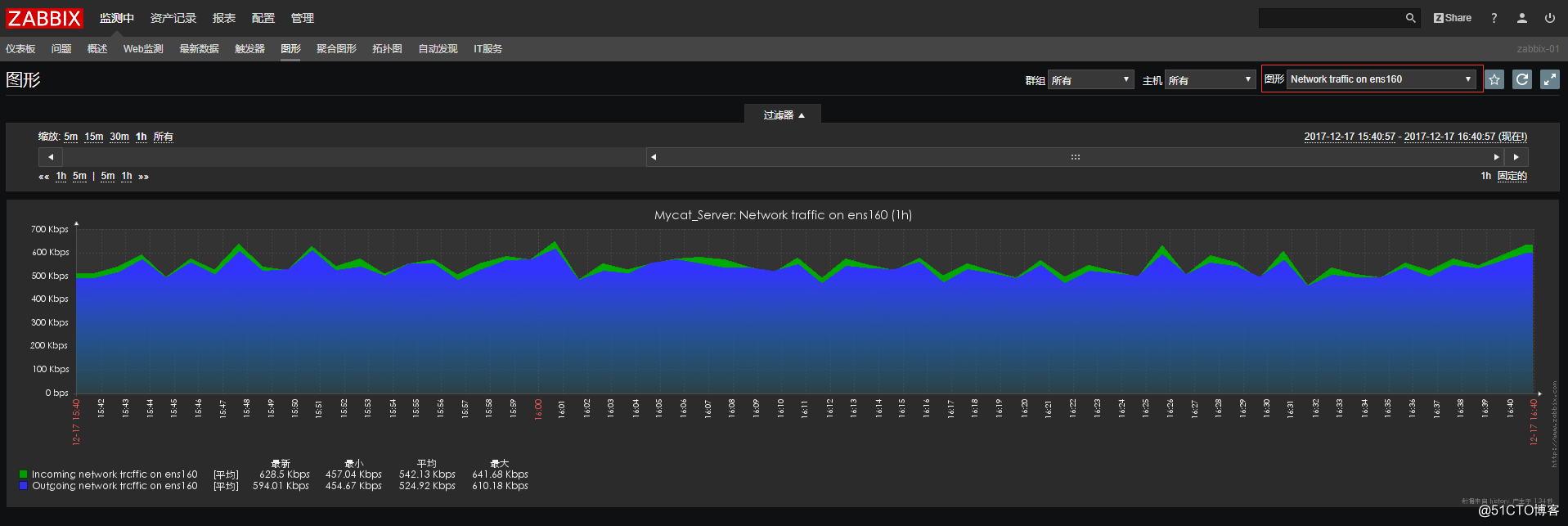
这时候就可以在图形中直接查看网卡的流量了:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
最后在zabbix服务端上启动客户端服务,监控服务端自身:
[root@localhost ~]$ systemctl start zabbix-agent
从客户端上同步相应的监控项配置文件,同步完之后重启客户端服务,然后到web页面上开启Zabbix server主机,然后链接上自定义模板和复制相应的监控项和触发器。
15 定制自定义监控脚本,监控web服务器的并发连接数,超过100告警
根据需求分析,首先我们第一步肯定得先通过脚本的方式获得这个连接数量,得到连接数量后还要去zabbix监控中心去创建监控项目,然后再针对这个自定义项目绘制一个图形出来。
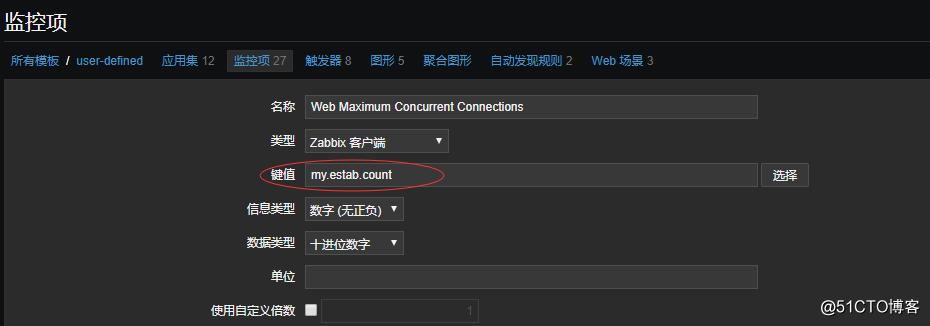
1.对于第一步,需要到客户端机器上定义脚本,同样的在客户端机器的 /etc/zabbix/zabbix_agentd.d,目录下添加 一个userparameter_estab.conf 配置文件, 文件内容如下:
[root@localhost ~]$ vim /etc/zabbix/zabbix_agentd.d/userparameter_estab.conf
UserParameter=my.estab.count[*],netstat -ant |grep ':80 ' |grep -c ESTABLISHED
2.完成之后重启zabbix-agent服务:
systemctl restart zabbix-agent
3.到zabbix服务端上使用以下命令测试能否获得数据,能得到数字证明没问题,就算是一个0也是,如果配置文件有问题的话,是不会得到数字的:
zabbix_get -s 192.168.200.153 -p 10050 -k 'my.estab.count'
ip是目标客户端机器的ip
4.测试正常后通过脚本将该配置文件同步到其他客户端机器上,同步之后也需要重启服务。
5.完成以上的操作后,回到服务端的web页面上,配置监控项:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
剩下的我都选择了默认,你可以根据自己的需求选择。
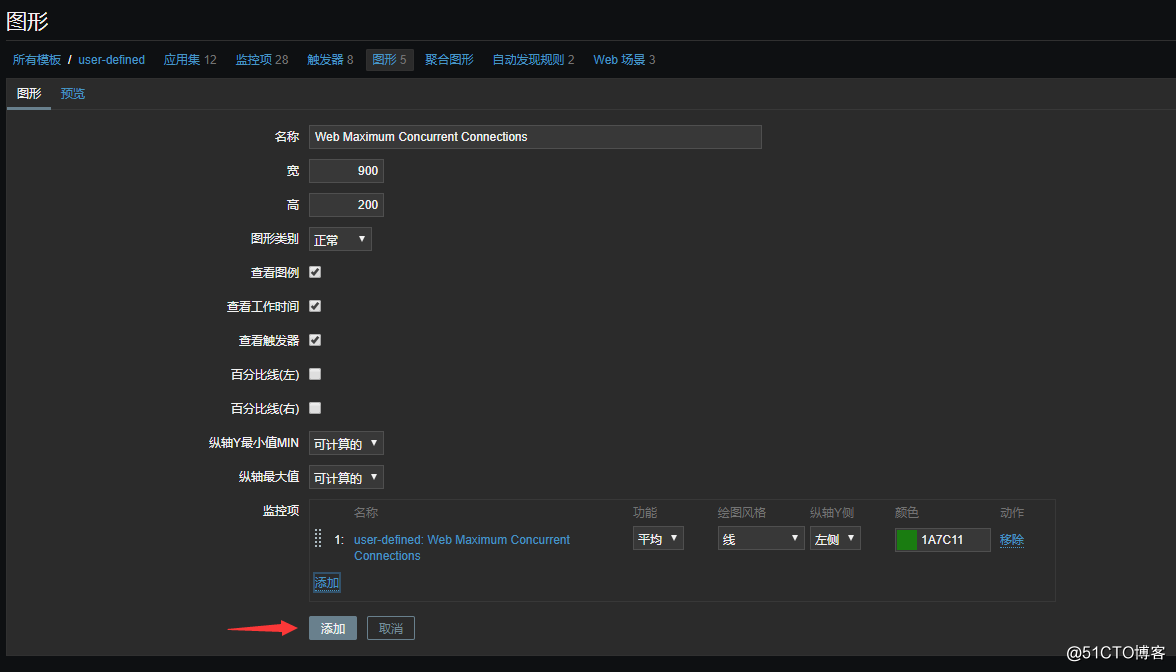
添加完监控项后,给这个监控项做一个图形:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
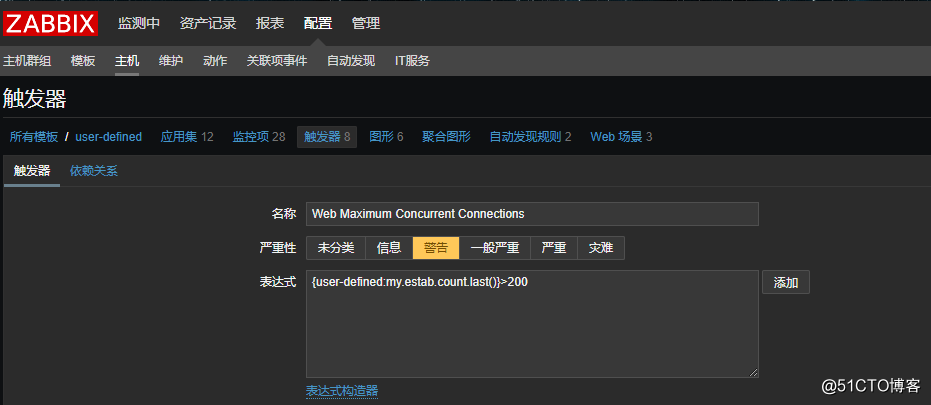
接着创建触发器,配置当并发数量大于100时就会触发:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
然后其他的默认即可。
16 定制自定义监控脚本,监控mysql的队列,队列超过300告警
所谓队列就是mysql的连接数量,或者说线程数量,使用show processlist;语句就可以显示哪些线程正在运行,mysql在登录的时候可以使用-e选项执行一条命令,所以使用以下命令,就可以得到线程数量:
[root@localhost ~]$ mysql -uroot -p'123456' -e "show processlist" |grep -v "Id" |wc -l
但是有一个问题就是mysql5.6以上版本使用-p指定密码会有警告信息,所以我们需要把警告信息重定向,留下结果信息,最后我们得到是这样的一个命令:
[root@localhost ~]$ mysql -uroot -p'123456' -h'192.168.200.146' -e "show processlist" 2>/dev/null |grep -v "Id" |wc -l
7
[root@localhost ~]$
然后把这个命令写进脚本里,制作成一个简便的命令:
[root@localhost ~]$ vim /usr/local/mysql/bin/processlist.sh
#!/bin/bash
count=`mysql -uroot -p'123456' -h'192.168.200.146' -e "show processlist" 2>/dev/null |grep -v "Id" |wc -l`
echo $count
[root@localhost ~]$ chmod a+x /usr/local/mysql/bin/processlist.sh
[root@localhost ~]$ ln -s /usr/local/mysql/bin/processlist.sh /usr/bin/processlist
得到命令后,和之前一样需要到客户端机器上定义脚本,但是这次只需要在mysql_master机器上的 /etc/zabbix/zabbix_agentd.d 目录下编辑配置文件(这个文件默认是存在的), 添加内容如下:
[root@localhost ~]$ vim /etc/zabbix/zabbix_agentd.d/userparameter_mysql.conf
UserParameter=mysql.processlist.count[*],processlist
2.完成之后重启zabbix-agent服务:
systemctl restart zabbix-agent
3.到zabbix服务端上使用以下命令测试能否获得数据,能得到数字证明没问题,就算是一个0也是,如果配置有问题的话,是不会得到数字的:
[root@localhost ~]$ zabbix_get -s 192.168.200.146 -p 10050 -k 'mysql.processlist.count'
8
[root@localhost ~]$
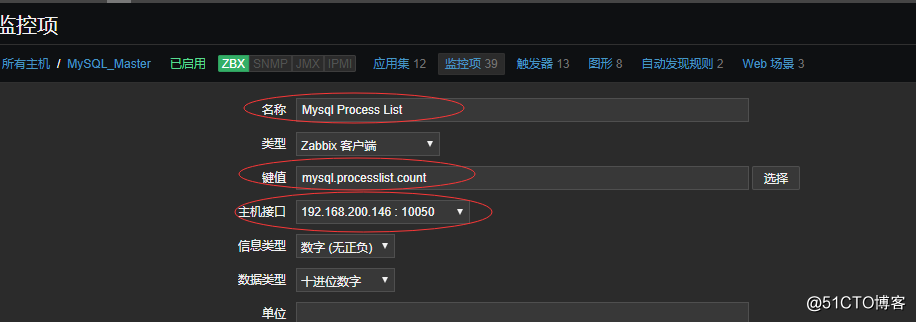
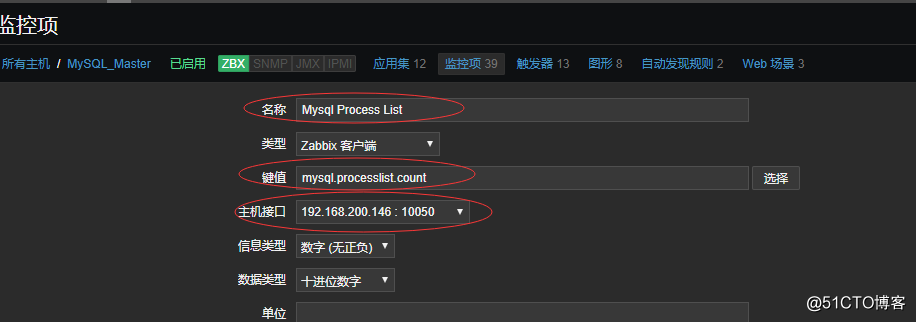
4.完成以上的操作后,回到服务端的web页面上,配置监控项,单独配置监控mysql_master主机,不需要在模板中配置:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
![搭建一个高可用负载均衡的集群架构(第二部分)]()
5.给这个监控项做一个图形:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
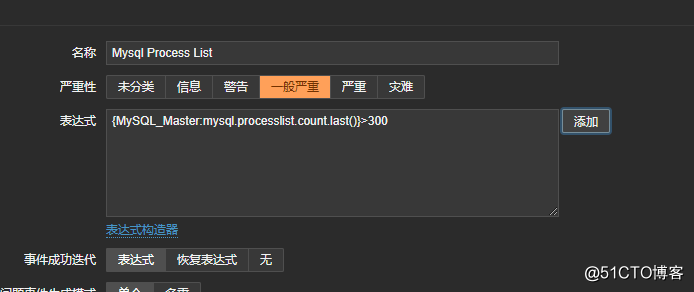
6.接着创建触发器,配置当并发数量大于300时就会触发:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
ok这个需求就完成了。
<br>
17 定制自定义监控脚本,监控mysql的慢查询日志,每分钟超过60条日志需要告警,需要仔细分析慢查询日志的规律,确定日志条数
1.先到两台slave机器上,开启慢查询日志:
mysql> set global slow_query_log=on; # 开启慢查询日志
Query OK, 0 rows affected (0.02 sec)
mysql> set global long_query_time=1; # 将阀值设置为1秒
Query OK, 0 rows affected (0.00 sec)
mysql> show global variables like '%long_query_time%'; # 查看阀值,未设置前默认为10秒
+
| Variable_name | Value |
+
| long_query_time | 1.000000 |
+
1 row in set (0.01 sec)
mysql> show variables like '%slow_query_log%'; # 查看慢查询日志状态,ON为开启状态,默认为OFF
+
| Variable_name | Value |
+
| slow_query_log | ON |
| slow_query_log_file | /data/mysql/localhost-slow.log | # 这是慢查询日志文件的路径
+
2 rows in set (0.00 sec)
mysql> use mysql;
mysql> select * from (select sleep(2))user; # 执行该语句产生慢查询,我这里执行了3次
2.查看慢查询日志文件内容:
[root@localhost ~]$ cat /data/mysql/localhost-slow.log
/usr/local/mysql/bin/mysqld, Version: 5.6.35 (MySQL Community Server (GPL)). started with:
Tcp port: 3306 Unix socket: /tmp/mysql.sock
Time Id Command Argument
SET timestamp=1513515526;
select * from (select sleep(2))user;
SET timestamp=1513515529;
select * from (select sleep(2))user;
SET timestamp=1513515532;
select * from (select sleep(2))user;
[root@localhost ~]$
如上,我执行了三次该语句,慢查询日志文件里记录了三次这个查询语句。
所以由此可知,只需要过滤出文件中的select关键字,即可得到慢查询日志的查询语句条数。但是因为sql语句会有大写的,记录到日志中也是大写的,所以在grep中需要加上-i来屏蔽大小写敏感,得出来的命令如下:
[root@localhost ~]$ cat /data/mysql/localhost-slow.log |grep -i "select"
select * from (select sleep(2))user;
select * from (select sleep(2))user;
select * from (select sleep(2))user;
SELECT * FROM (SELECT SLEEP (2))USER;
SELECT * FROM (SELECT SLEEP (2))USER;
SELECT * FROM (SELECT SLEEP (2))USER;
最后再使用wc命令得出行数,即是慢查询日志的查询语句条数,命令如下:
cat /data/mysql/localhost-slow.log |grep -i "select" |wc -l
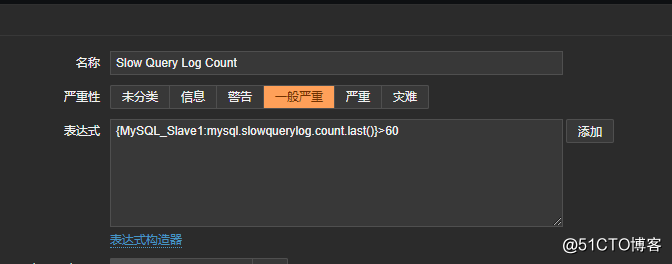
需求是要每分钟超过60条日志就触发告警,一分钟是60秒,这个可以在创建监控项时指定数据更新间隔为60秒即可。但是这也只是更新而已,日志文件中的内容会累加,所以我们还需要数据更新完之后就清空日志文件中的内容,脚本内容如下:
[root@localhost ~]$ vim /usr/local/mysql/bin/sqlc.sh
#!/bin/bash
filePath="/data/mysql/localhost-slow.log"
if [ -e $filePath ]
then
count=`cat $filePath |grep -i "select" |wc -l`
if [ $count -gt 0 ]
then
echo $count
echo "" > $filePath
exit 0
else
echo $count
exit 0
fi
else
echo "file not found!"
exit 1
fi
[root@localhost ~]$ sh /usr/local/mysql/bin/sqlc.sh
3
[root@localhost ~]$ cat /data/mysql/localhost-slow.log
[root@localhost ~]$ sh /usr/local/mysql/bin/sqlc.sh
0
[root@localhost ~]$
把脚本制作成命令:
[root@localhost ~]$ chmod a+x /usr/local/mysql/bin/sqlc.sh
[root@localhost ~]$ ln -s /usr/local/mysql/bin/sqlc.sh /usr/bin/sqlc
3.得到命令后,编辑配置文件,增加一行内容:
[root@localhost ~]$ vim /etc/zabbix/zabbix_agentd.d/userparameter_mysql.conf
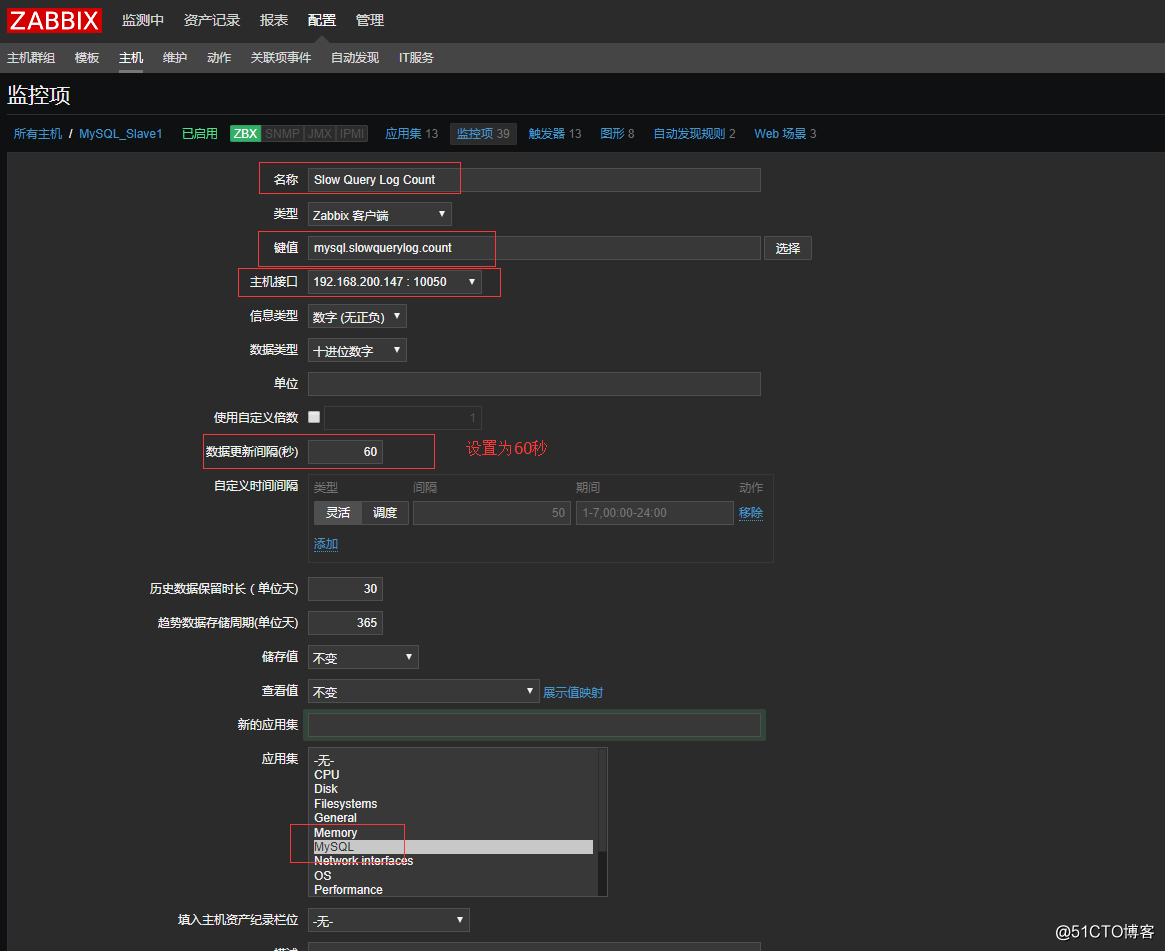
UserParameter=mysql.slowquerylog.count[*],sqlc
4.设置目录和文件的权限:
[root@localhost ~]$ chmod 755 /data/mysql
[root@localhost ~]$ chmod 777 /data/mysql/localhost-slow.log
5.完成之后重启zabbix-agent服务:
systemctl restart zabbix-agent
6.到zabbix服务端上使用以下命令测试能否获得数据,能得到数字证明没问题:
[root@localhost ~]$ zabbix_get -s 192.168.200.147 -p 10050 -k 'mysql.slowquerylog.count'
4
[root@localhost ~]$ zabbix_get -s 192.168.200.147 -p 10050 -k 'mysql.slowquerylog.count'
0
[root@localhost ~]$ zabbix_get -s 192.168.200.148 -p 10050 -k 'mysql.slowquerylog.count'
5
[root@localhost ~]$ zabbix_get -s 192.168.200.148 -p 10050 -k 'mysql.slowquerylog.count'
0
[root@localhost ~]
另一台slave机器重复以上步骤就可以了。
7.给这两台slave机器添加监控项:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
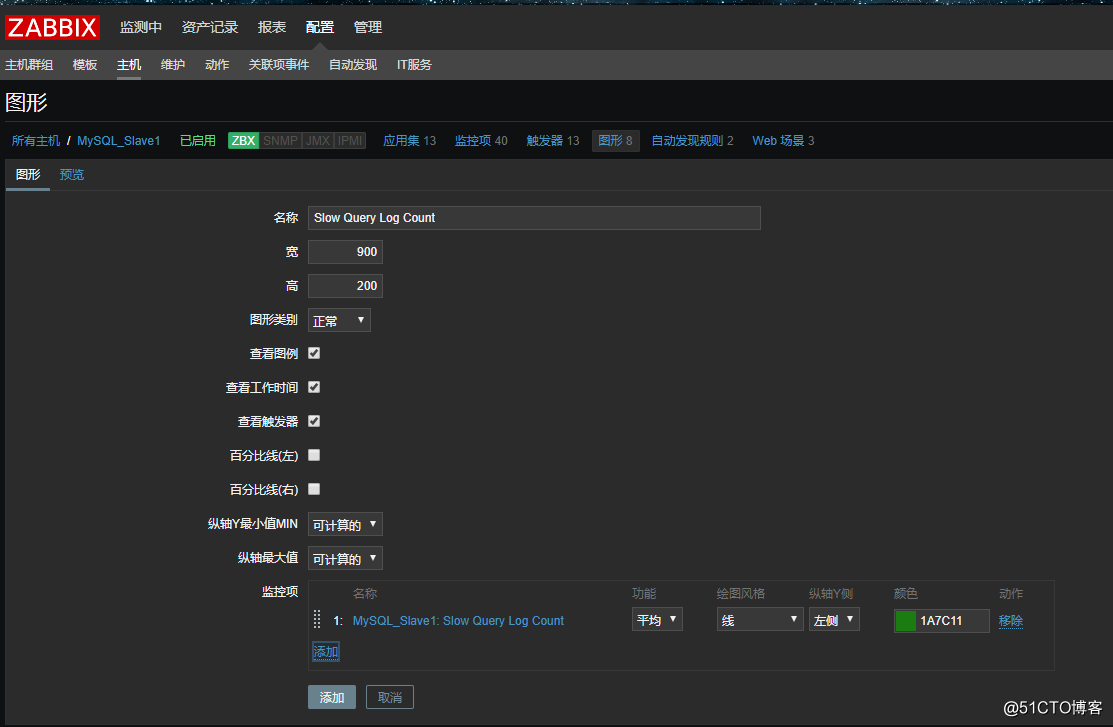
8.创建图形:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
9.创建触发器:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
![搭建一个高可用负载均衡的集群架构(第二部分)]()
配置邮件告警
在Zabbix服务端中可以设置邮件告警,当被监控的主机宕机了或者达到触发器预设值时,就会自动发送报警邮件到指定的一个第三方邮箱,这个邮箱可以使用163或者QQ邮箱(因为我只尝试过这两个邮箱),我这里使用163邮箱作为演示。
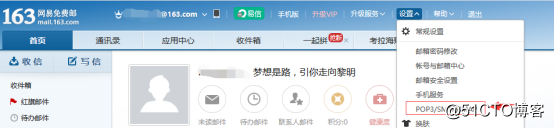
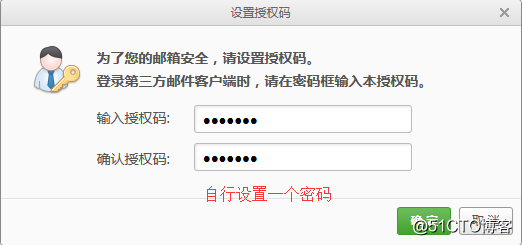
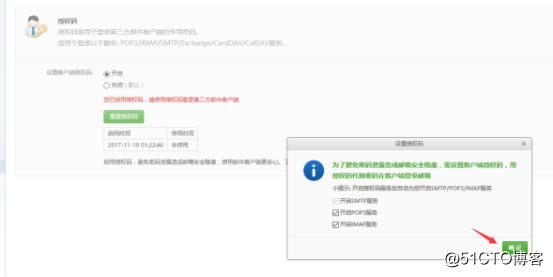
1.登录邮箱,设置开启POP3、IMAP、SMTP服务,因为要在服务器上调用第三方的邮箱,需要这个邮箱开启这些服务,登录后点击设置可以看到这些服务的选项:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
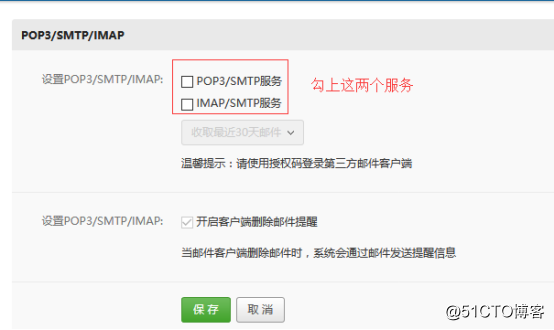
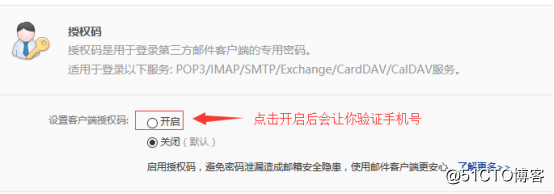
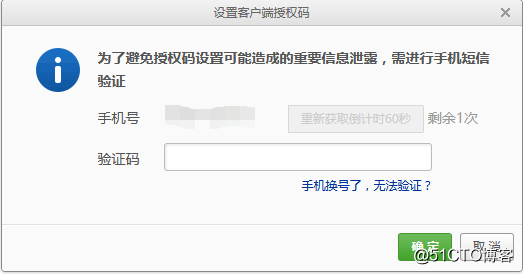
2.设置服务,第一次设置的话,会需要短信验证,然后还会要求你设置一个密码:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
![搭建一个高可用负载均衡的集群架构(第二部分)]()
进行短信验证:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
设置密码:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
完成:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
这个设置的密码也就是授权码要记住,发送邮箱的时候需要这个密码。
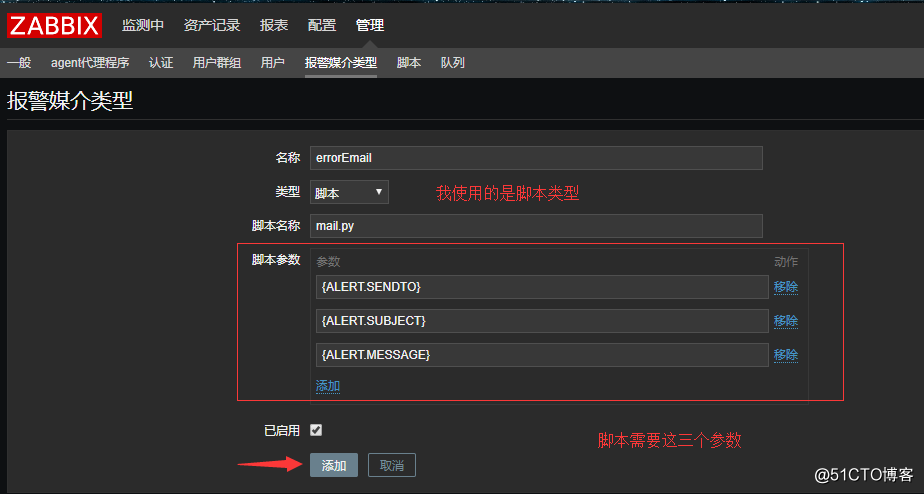
3.到监控中心,创建一个报警媒介类型:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
{ALERT.SENDTO} 参数定义第三方的邮件地址
{ALERT.SUBJECT} 参数定义主题
{ALERT.MESSAGE} 参数定义邮件内容
4.在服务端上查看zabbix配置文件,看看定义的脚本文件存放的路径是什么:
vim /etc/zabbix/zabbix_server.conf
在文件中搜索AlertScriptsPath:
AlertScriptsPath=/usr/lib/zabbix/alertscripts
5.得知脚本文件的存放路径后,在该路径下创建报警脚本mail.py:
vim /usr/lib/zabbix/alertscripts/mail.py
脚本内容如下:
import os,sys
reload(sys)
sys.setdefaultencoding('utf8')
import getopt
import smtplib
from email.MIMEText import MIMEText
from email.MIMEMultipart import MIMEMultipart
from subprocess import *
def sendqqmail(username,password,mailfrom,mailto,subject,content):
gserver = 'smtp.163.com'
gport = 25
try:
msg = MIMEText(unicode(content).encode('utf-8'))
msg['from'] = mailfrom
msg['to'] = mailto
msg['Reply-To'] = mailfrom
msg['Subject'] = subject
smtp = smtplib.SMTP(gserver, gport)
smtp.set_debuglevel(0)
smtp.ehlo()
smtp.login(username,password)
smtp.sendmail(mailfrom, mailto, msg.as_string())
smtp.close()
except Exception,err:
print "Send mail failed. Error: %s" % err
def main():
to=sys.argv[1]
subject=sys.argv[2]
content=sys.argv[3]
sendqqmail('email@example.com','password','email@example.com',to,subject,content)
if __name__ == "__main__":
main()
6.更改脚本文件的权限:
chmod 755 /usr/lib/zabbix/alertscripts/mail.py
7.测试一下这个脚本:
[root@localhost ~]$ cd /usr/lib/zabbix/alertscripts
[root@localhost /usr/lib/zabbix/alertscripts]$ python mail.py binary0_1@163.com "TestEmail" "This is test email"
[root@localhost /usr/lib/zabbix/alertscripts]$
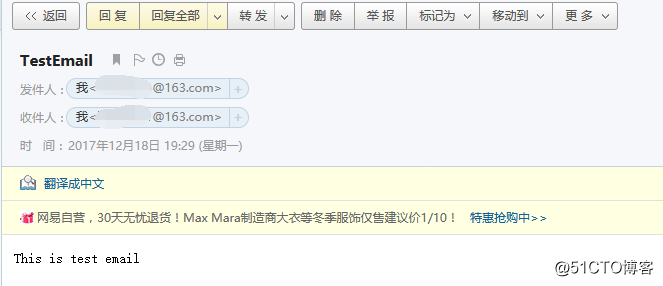
然后到你的邮箱里看看是否有收到这个邮件,能正常收到就没问题:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
如果没有收到邮件的话,就得检查检查你的脚本是否有问题。
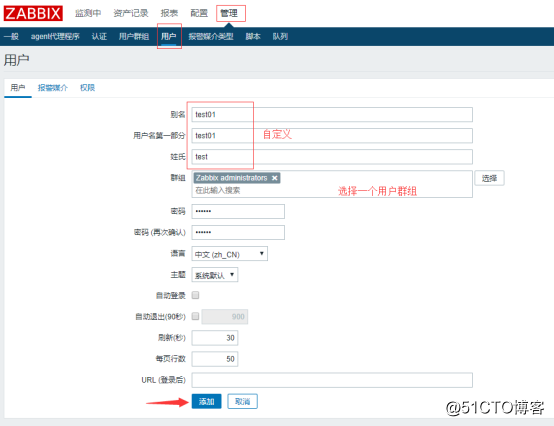
8.以上操作完成后,需要到监控中心创建一个用户用来发送邮件:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
9.然后再添加报警媒介:
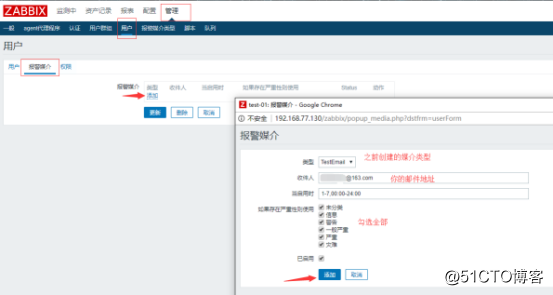
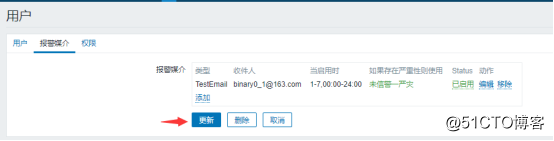
![搭建一个高可用负载均衡的集群架构(第二部分)]()
![搭建一个高可用负载均衡的集群架构(第二部分)]()
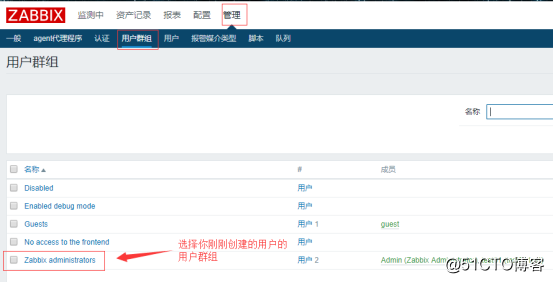
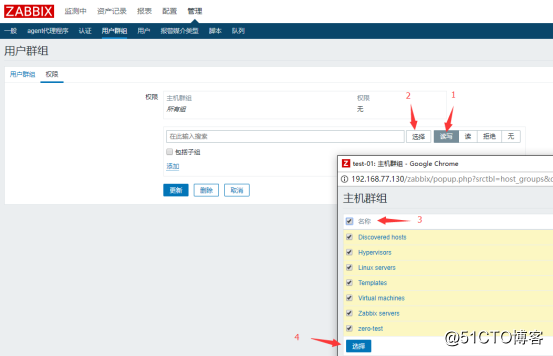
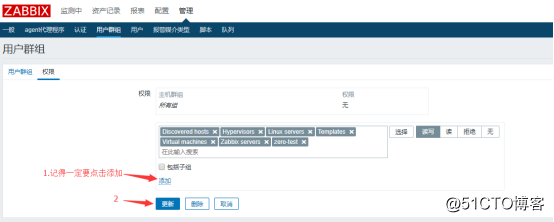
接着就是到用户群组中修改权限:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
![搭建一个高可用负载均衡的集群架构(第二部分)]()
![搭建一个高可用负载均衡的集群架构(第二部分)]()
如果你这一步权限没有修改对的话,你是收不到告警邮件的。
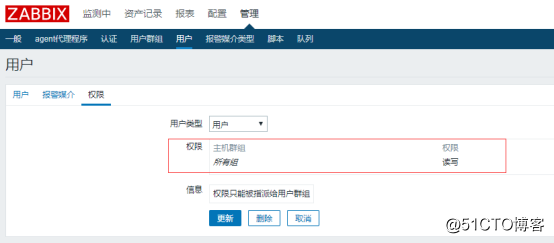
修改完群组权限后,到你创建的用户的权限界面里,看看是否已经拥有所有组的读写权限:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
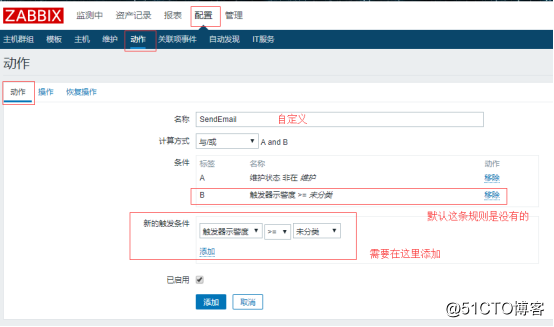
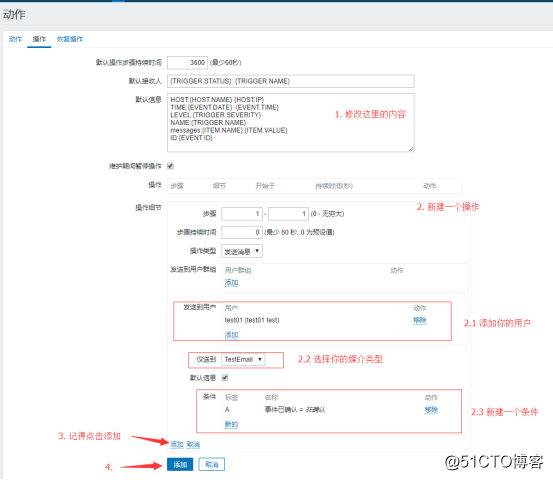
用户配置完后,需要去创建一个动作,动作就是触发器触发后会发生的行为动作,这个动作就是发邮件的动作:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
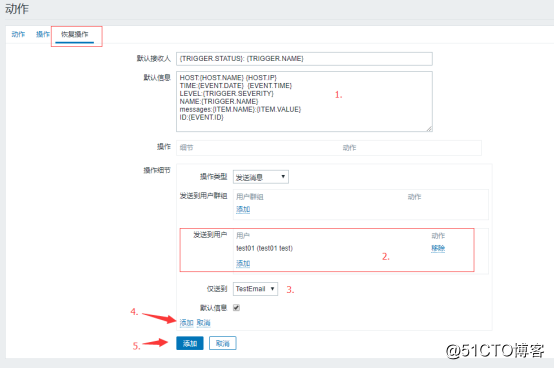
然后操作界面里还需要配置一下默认信息和操作:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
默认信息的内容如下:
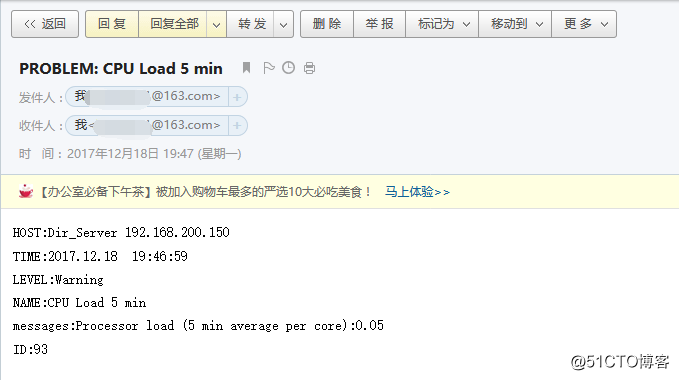
HOST:{HOST.NAME} {HOST.IP}
TIME:{EVENT.DATE} {EVENT.TIME}
LEVEL:{TRIGGER.SEVERITY}
NAME:{TRIGGER.NAME}
messages:{ITEM.NAME}:{ITEM.VALUE}
ID:{EVENT.ID}
恢复操作界面里的默认信息也需要重新配置,配置内容如下:
HOST:{HOST.NAME} {HOST.IP}
TIME:{EVENT.DATE} {EVENT.TIME}
LEVEL:{TRIGGER.SEVERITY}
NAME:{TRIGGER.NAME}
messages:{ITEM.NAME}:{ITEM.VALUE}
ID:{EVENT.ID}
![搭建一个高可用负载均衡的集群架构(第二部分)]()
完成:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
测试告警
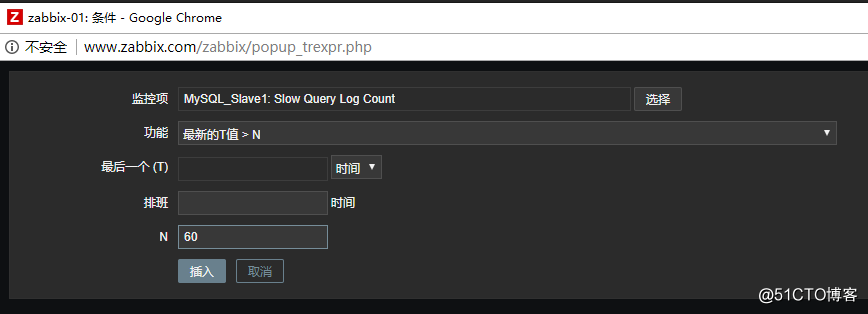
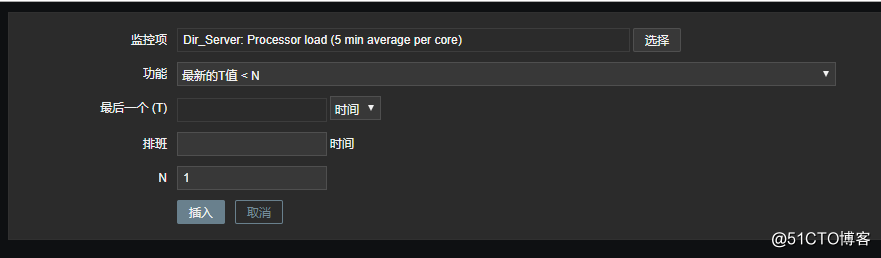
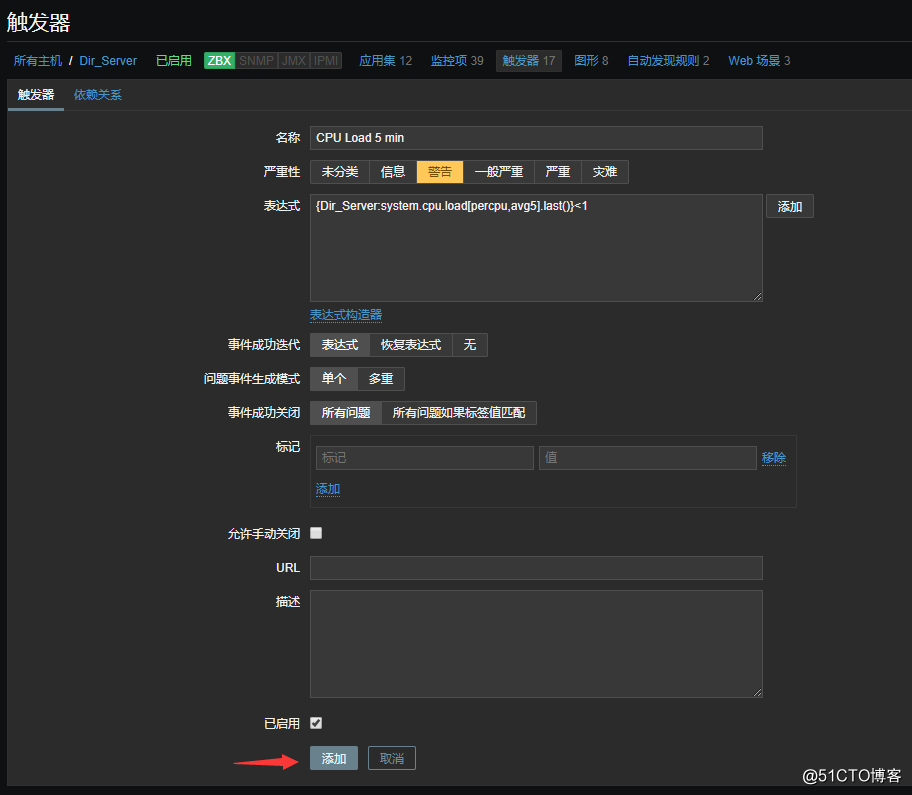
到目前为止,邮件告警就配置好了,接下来就是测试一下这个告警是否正常,首先选择一台主机,然后给这个主机创建一个自定义的触发器:
条件:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
![搭建一个高可用负载均衡的集群架构(第二部分)]()
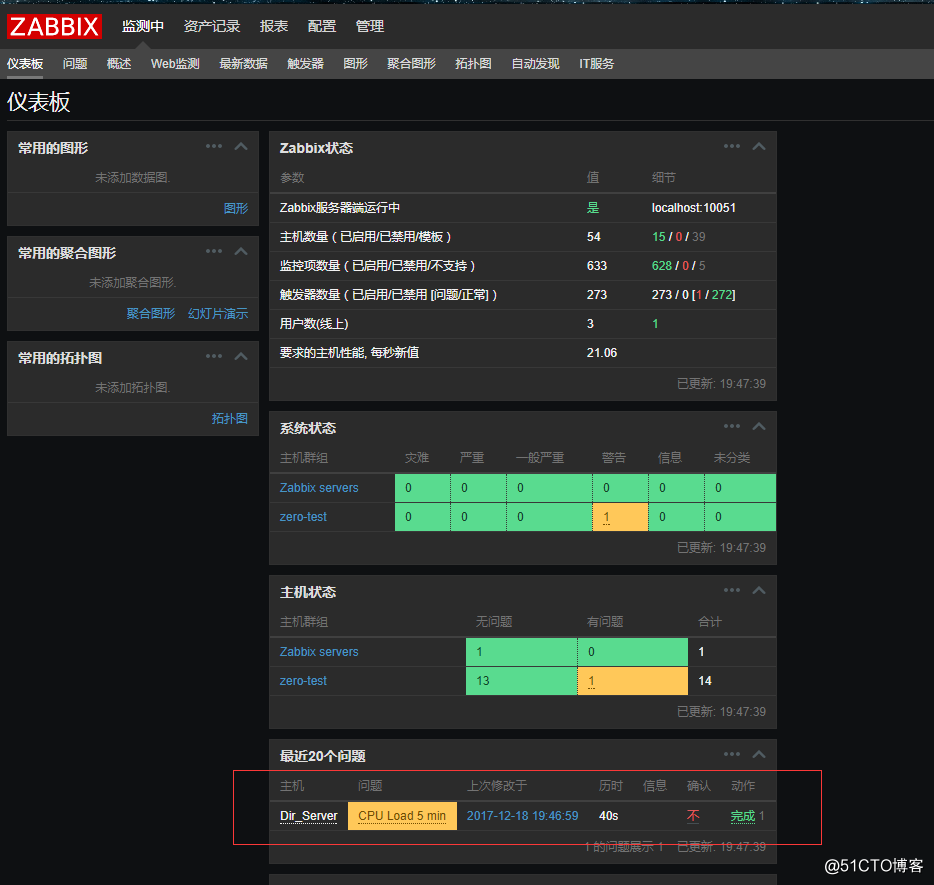
然后到监控中心的仪表板中,等一会就会发现出现警告信息:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
如图,这是我们刚刚创建的触发器告的警,并且动作显示的是完成,代表邮件已经发送了,如果显示的是失败的话,那就是邮件发送失败了,发送失败的情况一般有以下几个原因:
1.媒介类型
2.动作的默认信息
3.操作和恢复操作的默认信息
4.脚本文件不够权限
5.没有给用户添加媒介
6.邮箱里的服务没有打开
7.触发器
8.网络问题
一般动作显示失败的话都会有一个具体的提示,根据提示排查错误快一些。
我这里是发送成功的,那么到邮箱里看看邮件内容:
![搭建一个高可用负载均衡的集群架构(第二部分)]()
ok监控就做完了,后期再需要什么监控像以上步骤一样添加就可以了。
8 给所有服务器做一个简单的命令审计功能
有时候我们需要对线上用户操作记录进行历史记录待出现问题追究责任人,但Linux系统自带的history命令用户有自行删除权限,那怎么设置可以让用户的操作记录实时记录,并保证普通用户无权删除呢?所以就需要给服务器做一个命令审计功能(这里只是演示一个简单的)。
1.创建一个目录,并授予相应的权限:
mkdir -p /usr/local/domob/records/
chmod 777 /usr/local/domob/records/
chmod +t /usr/local/domob/records/
2.vim /etc/profile 在最后添加下面的代码:
if [ ! -d /usr/local/domob/records/${LOGNAME} ]
then
mkdir -p /usr/local/domob/records/${LOGNAME}
chmod 300 /usr/local/domob/records/${LOGNAME}
fi
export HISTORY_FILE="/usr/local/domob/records/${LOGNAME}/bash_history"
export PROMPT_COMMAND='{ date "+%Y-%m-%d %T ##### $(who am i |awk "{print \$1\" \"\$2\" \"\$5}") #### $(history 1 | { read x cmd; echo "$cmd"; })"; } >>$HISTORY_FILE'
3.添加完后加载profile文件:
source /etc/profile
4.然后会生成一个/usr/local/domob/records/root/bash_history文件,查看文件内容可以见到记录了以下内容:
[root@localhost ~]$ cat /usr/local/domob/records/root/bash_history
2017-12-18 01:07:05
2017-12-18 01:07:36
2017-12-18 01:07:39
2017-12-18 01:07:46
2017-12-18 01:07:55
2017-12-18 01:08:01
[root@localhost ~]$
执行命令的用户、日期以及用户的ip都被记录了下来了,这样就实现了一个简单的命令审计功能。
5.把 /usr/local/domob/records/ 目录以及 /etc/profile 文件同步到其他服务上即可,记得同步完后批量执行source /etc/profile命令。
9 php-fpm服务要求设置慢执行日志,超时时间为2s,并做日志切割,日志保留一月
1.编辑php-fpm的配置文件,并如下添加内容:
[root@localhost ~]$ vim /usr/local/php-fpm/etc/php-fpm.conf
request_slowlog_timeout = 2
slowlog = /usr/local/php-fpm/var/log/www-slow.log
2.修改完成够,测试一下配置文件的语法,并重新加载配置文件:
[root@localhost ~]$ /usr/local/php-fpm/sbin/php-fpm -t
[18-Dec-2017 01:31:44] NOTICE: configuration file /usr/local/php-fpm/etc/php-fpm.conf test is successful
[root@localhost ~]$ /etc/init.d/php-fpm reload
Reload service php-fpm done
[root@localhost ~]$
3.接下来我们需要模拟一个慢执行的php,需要写一个php脚本,以便验证能够记录慢执行日志:
[root@localhost ~]$ vim /data/wwwroot/default/sleep.php
<?php
echo "test slow log";
sleep(3);
echo "done";
?>
4.使用curl对这个脚本进行访问:
[root@localhost ~]$ curl -x127.0.0.1:80 localhost/sleep.php
test slow log
done
[root@localhost ~]$
5.访问完之后查看慢执行日志,这个日志告诉了我们以下信息:
[root@localhost ~]$ cat /usr/local/php-fpm/var/log/www-slow.log
[18-Dec-2017 01:36:32] [pool www] pid 2653
script_filename = /data/wwwroot/default/sleep.php
[0x00007f8fc62ca270] sleep() /data/wwwroot/default/sleep.php:3
[root@localhost ~]$
6.测试完可以生成日志后,开始做日志切割,Nginx不像Apache那样有自带的日志切割工具,所以只能借助系统的切割工具或者自己写一个简单的切割脚本,在这里则介绍一下如何写一个日志切割的脚本,如下:
[root@localhost ~]$ vim /usr/local/sbin/nginx_log_rotate.sh
#! /bin/bash
d=`date -d "-1 day" +%Y%m%d`
logdir="/usr/local/php-fpm/var/log/"
nginx_pid="/usr/local/nginx/logs/nginx.pid"
cd $logdir
for log in `ls *.log`
do
mv $log $log-$d
done
/bin/kill -HUP `cat $nginx_pid`
7.保存退出后,我们可以使用sh -x 命令来查看这个脚本的执行过程:
[root@localhost ~]$ sh -x /usr/local/sbin/nginx_log_rotate.sh
++ date -d '-1 day' +%Y%m%d
+ d=20171217
+ logdir=/usr/local/php-fpm/var/log/
+ nginx_pid=/usr/local/nginx/logs/nginx.pid
+ cd /usr/local/php-fpm/var/log/
++ ls php-fpm.log www-slow.log
+ for log in '`ls *.log`'
+ mv php-fpm.log php-fpm.log-20171217
+ for log in '`ls *.log`'
+ mv www-slow.log www-slow.log-20171217
++ cat /usr/local/nginx/logs/nginx.pid
+ /bin/kill -HUP 23727
[root@localhost ~]$
8.写完脚本后,需要定期的自动执行日志切割,所以我们要设置一个任务计划:
[root@localhost ~]$ crontab -e
0 0 * * * /bin/bash /usr/local/sbin/nginx_log_rotate.sh
9.日志只保留一个月,还需要往crontab里添加以下这一行,每个月的1号就删除一次旧的日志文件:
* * 1 * * /usr/bin/find /usr/local/php-fpm/var/log/ -name *.log.* -type f -mtime +30 |xargs rm
10.同步以下文件到其他web服务器上:
/usr/local/php-fpm/etc/php-fpm.conf
/usr/local/sbin/nginx_log_rotate.sh
/var/spool/cron/root
同步完php-fpm配置文件后记得reload。
10 所有站点都需要配置访问日志,并做日志切割,要求静态文件日志不做记录,日志保留一月
在nginx里,日志的格式可以在主配置文件里定义,编辑主配置文件:
vim /usr/local/nginx/conf/nginx.conf
搜索log_format,这一段就是用来定义日志格式的:
log_format combined_realip '$remote_addr $http_x_forwarded_for [$time_local]'
' $host "$request_uri" $status'
' "$http_referer" "$http_user_agent"';
其中的combined_realip是日志的名称,这个名称可以自定义,但是你定义了什么名称,后面你操作日志的时候也要使用这个名称。就像你给一个人起名叫李四,你就得用李四这个名字去叫他干活。
获取到日志名称后编辑站点的虚拟主机配置文件:
vim /usr/local/nginx/conf/vhost/discuz.com.conf
增加以下内容:
access_log /data/wwwroot/discuz.com/data/log/discuz.com.log combined_realip;
这里的combined_realip就是在nginx.conf中定义的日志格式名字。
然后重新加载配置文件:
[root@localhost ~]$ /usr/local/nginx/sbin/nginx -t
nginx: the configuration file /usr/local/nginx/conf/nginx.conf syntax is ok
nginx: configuration file /usr/local/nginx/conf/nginx.conf test is successful
[root@localhost ~]$ /usr/local/nginx/sbin/nginx -s reload
接着使用curl进行访问,测试一下是否有生成日志文件:
[root@localhost ~]$ curl -x127.0.0.1:80 www.discuz.com/forum.php -I
[root@localhost ~]$ cat /data/wwwroot/discuz.com/data/log/discuz.com.log
127.0.0.1 - [18/Dec/2017:09:51:52 +0800] www.discuz.com "/" 301 "-" "curl/7.29.0"
127.0.0.1 - [18/Dec/2017:09:52:04 +0800] www.discuz.com "/forum.php" 200 "-" "curl/7.29.0"
[root@localhost ~]$
生成访问日志成功,并且记录了日志。
静态文件不记录日志的配置如下:
[root@localhost ~]$ vim /usr/local/nginx/conf/vhost/discuz.com.conf
location ~ .*\.(gif|jpg|jpeg|png|bmp|swf)$
{
expires 7d;
access_log off;
}
location ~ .*\.(js|css)$
{
expires 12h;
access_log off;
}
配置完后重新加载配置文件:
[root@localhost ~]$ /usr/local/nginx/sbin/nginx -t
nginx: the configuration file /usr/local/nginx/conf/nginx.conf syntax is ok
nginx: configuration file /usr/local/nginx/conf/nginx.conf test is successful
[root@localhost ~]$ /usr/local/nginx/sbin/nginx -s reload
[root@localhost ~]$
下面就进行测试一下是否成功:
[root@localhost ~]$ curl -x127.0.0.1:80 www.discuz.com/static/space/t5/preview.jpg -I
HTTP/1.1 200 OK
Server: nginx/1.12.1
Date: Mon, 18 Dec 2017 01:59:54 GMT
Content-Type: image/jpeg
Content-Length: 4389
Last-Modified: Fri, 15 Dec 2017 04:09:01 GMT
Connection: keep-alive
ETag: "5a334add-1125"
Expires: Mon, 25 Dec 2017 01:59:54 GMT
Cache-Control: max-age=604800
Accept-Ranges: bytes
[root@localhost ~]$ !cat
cat /data/wwwroot/discuz.com/data/log/discuz.com.log
127.0.0.1 - [18/Dec/2017:09:51:52 +0800] www.discuz.com "/" 301 "-" "curl/7.29.0"
127.0.0.1 - [18/Dec/2017:09:52:04 +0800] www.discuz.com "/forum.php" 200 "-" "curl/7.29.0"
[root@localhost ~]$
至于日志切割其实就修改一下之前那个脚本文件即可,把logdir变量定义的路径换成参数的形式,然后在定时任务计划里传递相应的路径即可:
[root@localhost ~]$ vim /usr/local/sbin/nginx_log_rotate.sh
#! /bin/bash
d=`date -d "-1 day" +%Y%m%d`
logdir="$1"
nginx_pid="/usr/local/nginx/logs/nginx.pid"
cd $logdir
for log in `ls *.log`
do
mv $log $log-$d
done
/bin/kill -HUP `cat $nginx_pid`
测试一下脚本:
[root@localhost ~]$ sh -x /usr/local/sbin/nginx_log_rotate.sh "/data/wwwroot/discuz.com/data/log/"
++ date -d '-1 day' +%Y%m%d
+ d=20171217
+ logdir=/data/wwwroot/discuz.com/data/log/
+ nginx_pid=/usr/local/nginx/logs/nginx.pid
+ cd /data/wwwroot/discuz.com/data/log/
++ ls discuz.com.log
+ for log in '`ls *.log`'
+ mv discuz.com.log discuz.com.log-20171217
++ cat /usr/local/nginx/logs/nginx.pid
+ /bin/kill -HUP 23727
[root@localhost ~]$
没问题之后修改任务计划内容如下:
[root@localhost ~]$ crontab -e
0 0 * * * /bin/bash /usr/local/sbin/nginx_log_rotate.sh "/usr/local/php-fpm/var/log/"
0 0 * * * /bin/bash /usr/local/sbin/nginx_log_rotate.sh "/data/wwwroot/discuz.com/data/log/"
* * 1 * * /usr/bin/find /usr/local/php-fpm/var/log/ -name *.log.* -type f -mtime +30 |xargs rm
* * 1 * * /usr/bin/find /data/wwwroot/discuz.com/data/log/ -name *.log.* -type f -mtime +30 |xargs rm
剩下的站点都是和以上步骤一样照葫芦画瓢即可,最后将文件都同步到其他web服务器上就可以了。zrlog由于是代理配置文件所以配置内容不太一样,以下是zrlog的整体配置内容:
[root@localhost ~]$ cat /usr/local/nginx/conf/vhost/zrlog.com.conf
upstream zrlog_com
{
ip_hash;
server localhost:8080;
}
server
{
listen 80;
server_name www.zrlog.com;
location /admin/
{
auth_basic "Auth";
auth_basic_user_file /usr/local/nginx/conf/htpasswd;
proxy_pass http://zrlog_com/admin/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
location ~ .*\.(gif|jpg|jpeg|png|bmp|swf)$
{
expires 7d;
access_log off;
proxy_pass http://zrlog_com;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
location ~ .*\.(js|css)$
{
expires 12h;
access_log off;
proxy_pass http://zrlog_com;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
location /
{
proxy_pass http://zrlog_com;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
access_log /data/wwwroot/zrlog.com/logs/zrlog.com.log combined_realip;
}
除了配置内容不一样外,其他都是一致的。
全部站点都配置完成后,同步以下文件到其他web服务器上:
/usr/local/nginx/conf/vhost/dedecms.com.conf
/usr/local/nginx/conf/vhost/discuz.com.conf
/usr/local/nginx/conf/vhost/zrlog.com.conf
/usr/local/sbin/nginx_log_rotate.sh
/var/spool/cron/root