过程分析
1.添加新词需要确定无缓存文件,否则无法使用成功,因为词典会优先加载缓存文件
2.再确认缓存文件不在时,打开本地词典按照格式添加自定义词汇。
3.调用分词函数重新生成缓存文件,这时会报一个找不到缓存文件的异常,不用管,因为加载词典进入内存是会优先加载缓存,缓存不在当然会报异常,然后加载词典生成缓存文件,最后处理字符进行分词就会发现新添加的词汇可以进行分词了。
操作过程图解:
1、有缓存文件的情况下:
1 System.out.println(HanLP.segment("张三丰在一起我也不知道你好一个心眼儿啊,一半天欢迎使用HanLP汉语处理包!" +"接下来请从其他Demo中体验HanLP丰富的功能~"))
2
3 //首次编译运行时,HanLP会自动构建词典缓存,请稍候……
4 //[张/q, 三丰/nz, 在/p, 一起/s, 我/rr, 也/d, 不/d, 知道/v, 你好/vl, 一个心眼儿/nz, 啊/y, ,/w, 一半天/nz, 欢迎/v, 使用/v, HanLP/nx, 汉语/gi, 处理/vn, 包/v, !/w, 接下来/vl, 请/v, 从/p, 其他/rzv, Demo/nx, 中/f, 体验/v, HanLP/nx, 丰富/a, 的/ude1, 功能/n, ~/nx]
5
6
1.Â
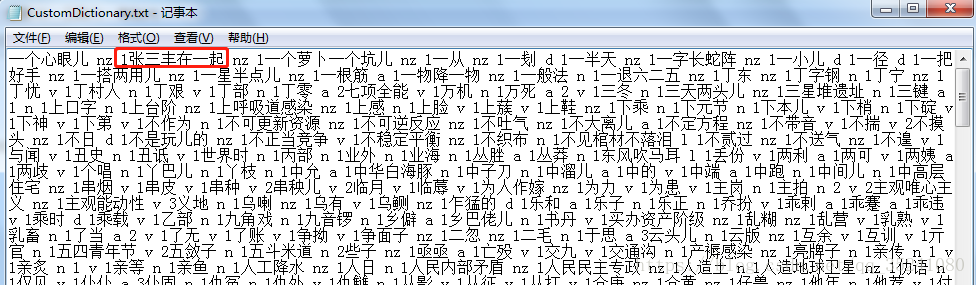
打开用户词典–添加 ‘张三丰在一起’ 为一个 nz词性的新词
![b2a8bc411f472fb3381c06fab3a187da70a4e960]()
2.2 原始缓存文件下运行–会发现不成功,没有把 ‘张三丰在一起’ 分词一个nz词汇
1 System.out.println(HanLP.segment("张三丰在一起我也不知道你好一个心眼儿啊,一半天欢迎使用HanLP汉语处理包!" +"接下来请从其他Demo中体验HanLP丰富的功能~"))
2
3 //首次编译运行时,HanLP会自动构建词典缓存,请稍候……
4 //[张/q, 三丰/nz, 在/p, 一起/s, 我/rr, 也/d, 不/d, 知道/v, 你好/vl, 一个心眼儿/nz, 啊/y, ,/w, 一半天/nz, 欢迎/v, 使用/v, HanLP/nx, 汉语/gi, 处理/vn, 包/v, !/w, 接下来/vl, 请/v, 从/p, 其他/rzv, Demo/nx, 中/f, 体验/v, HanLP/nx, 丰富/a, 的/ude1, 功能/n, ~/nx]
5
3.1 删除缓存文件 bin
![59059b975bc86de78672044193a82853c9abaa1a]()
3.2 再次运行程序,此时会报错—无法找到缓存文件
1 System.out.println(HanLP.segment("张三丰在一起我也不知道你好一个心眼儿啊,一半天欢迎使用HanLP汉语处理包!" +"接下来请从其他Demo中体验HanLP丰富的功能~"));
2
3 /**首次编译运行时,HanLP会自动构建词典缓存,请稍候……
4 十月 19, 2018 6:12:49 下午 com.hankcs.hanlp.corpus.io.IOUtil readBytes
5 WARNING: 读取D:/datacjy/hanlp/data/dictionary/custom/CustomDictionary.txt.bin时发生异常java.io.FileNotFoundException: D:\datacjy\hanlp\data\dictionary\custom\CustomDictionary.txt.bin (系统找不到指定的文件。) 找不到缓存文件
6
7
8 [张三丰在一起/nz, 我/rr, 也/d, 不/d, 知道/v, 你好/vl, 一个心眼儿/nz, 啊/y, ,/w, 一半天/nz, 欢迎/v, 使用/v, HanLP/nx, 汉语/gi, 处理/vn, 包/v, !/w, 接下来/vl, 请/v, 从/p, 其他/rzv, Demo/nx, 中/f, 体验/v, HanLP/nx, 丰富/a, 的/ude1, 功能/n, ~/nx]
9
10 */