五款中文分词工具的比较,尝试的有jieba,SnowNLP,thulac(清华大学自然语言处理与社会人文计算实验室),StanfordCoreNLP,pyltp(哈工大语言云),环境是Win10,anaconda3.7
1. 安装
Jieba:
pip install jieba
SnowNLP:
pip install snownlp
thulac:
pip install thulac
StanfordCoreNLP:
pip install stanfordcorenlp
下载
CoreNLP
并解压,将中文包下载并解压至
CoreNLP
文件夹
pyltp:
pip install pyltp,安装失败提示c++14 missing,手动编译失败,换成centos安装依然失败
2. 运行
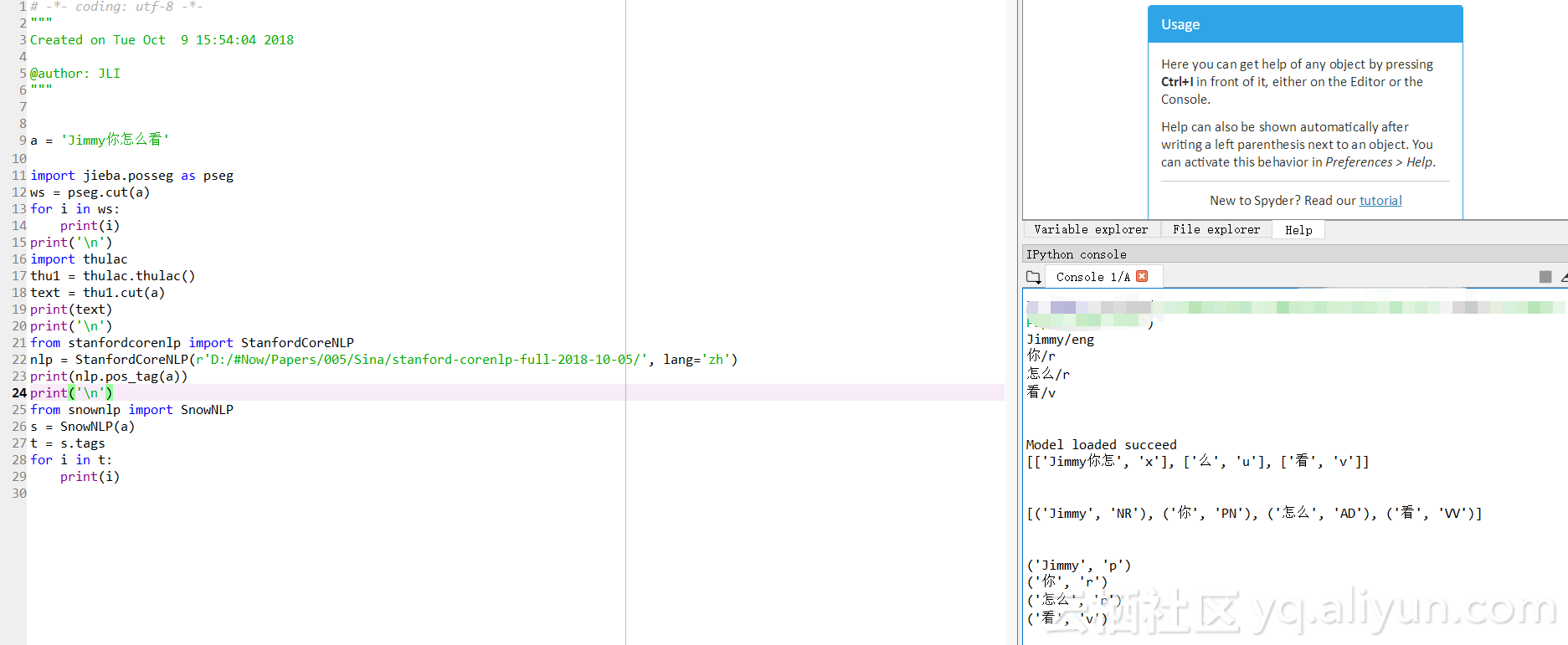
![d02ec91b0911cefbf220828d2600cd67f79c4885]()
a = 'Jimmy你怎么看'
import jieba.posseg as pseg
ws = pseg.cut(a)
for i in ws:
print(i)
import thulac
thu1 = thulac.thulac()
text = thu1.cut(a)
print(text)
from stanfordcorenlp import StanfordCoreNLP
nlp = StanfordCoreNLP(r'./stanford-corenlp-full-2018-10-05/', lang='zh')
print(nlp.pos_tag(a))
from snownlp import SnowNLP
s = SnowNLP(a)
t = s.tags
for i in t:
print(i)
3. 结果
只有Thulac的结果比较特别,StanfordCoreNLP的运行占用大量内存和CPU,尝试另一句话‘这本书很不错’,jieba无法分出‘本’,其他都可以完整分词,不过StanfordCoreNLP依然占用大量内存和CPU。
Jieba:
Jimmy/eng
你/r
怎么/r
看/v
Thulac:
Model loaded succeed
[['Jimmy你怎', 'x'], ['么', 'u'], ['看', 'v']]
SnowNLP:
[('Jimmy', 'NR'), ('你', 'PN'), ('怎么', 'AD'), ('看', 'VV')]
StanfordCoreNLP:
('Jimmy', 'p')
('你', 'r')
('怎么', 'r')
('看', 'v')