最近,在GitHub上有位id为imhuay的热心人带头建立了一个关于国内知名互联网企业笔试和面试经验的资源库,光从名称上就能看出其内容有多丰富:《2018/2019/校招/春招/秋招/算法/机器学习(MachineLearning)/深度学习(Deep Learning)/自然语言处理(NLP)/C/C++/Python/面试笔记》。
其中除了初步梳理和介绍的机器学习领域重要的基础知识和脉络结构之外,还总结了一些国内互联网名企网招、校招笔试面试时的内容和套路,非常值得立志进入这些企业的小伙伴们参考,而且是纯中文的哦!
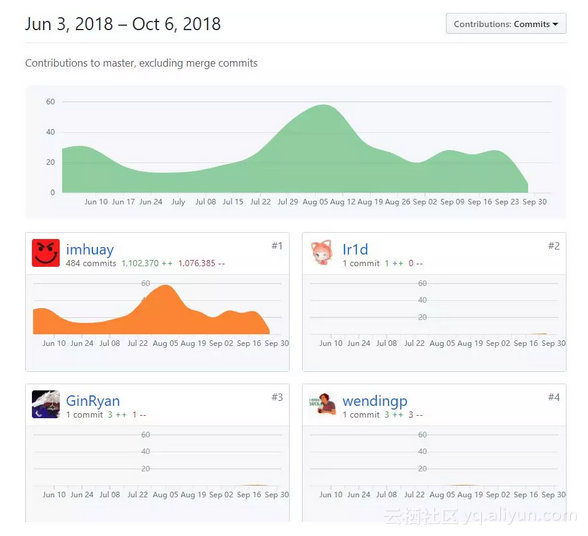
目前,该资源库在Github上已经获得5100+的星,可以说是很火热了。
Github资源库地址:
https://github.com/imhuay/Algorithm_Interview_Notes-Chinese
这个库目前有四个贡献者,多亏他们,才能集聚如此丰富的题库。在此,首先向这四位开发者致谢。
![97cc50e732a63f034a2ef9a0b2bde214f01d9ff7]()
下面我们一起来看看,这个资源库收集了哪些宝贵资源。
![163c350136b0e2f8ba24c2619a8ae6f17a84b6f2]()
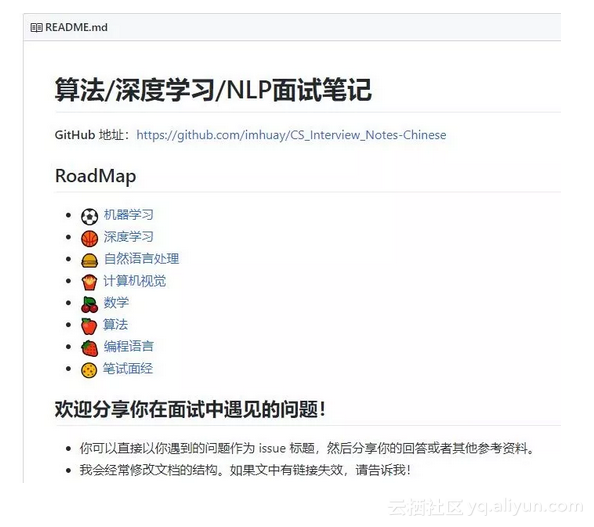
主页面很简洁,就是一份按内容划分的主目录。除了最后一项“笔试面经”之外,其他的目录标题都是和计算机相关的热门主题词。里面是相关主题词下的一些知识介绍和技术资料,同样值得参考。
计算机相关热门话题知识介绍和总结
比如“机器学习”这个条目,点击进去可以看到一些子目录,包括“机器学习基础”、“机器学习算法”、“机器学习实践”、“集成学习”。
![a76a7c51ed7f23144d5bc9859f0b948b9392f033]()
继续点击可以看到相关主题下的资料,比如下面就是“机器学习基础”子目录下关于“生成模型与判别模型”的介绍。
![b07c82b8fc034443483135ac3812aa0f8ff5f17e]()
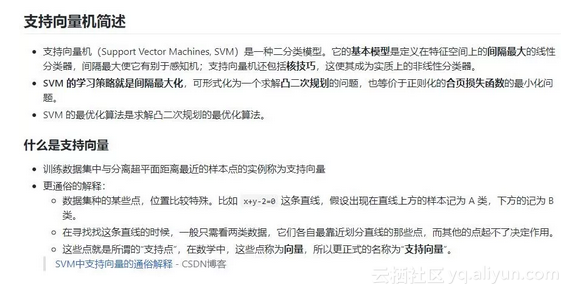
其他目录结构与此类似,比如下图是“机器学习算法”子目录下对支持向量机(SVM)的介绍。
再来看看同样热门的“自然语言处理”,子目录分别为:自然语言处理基础、词向量、句向量。
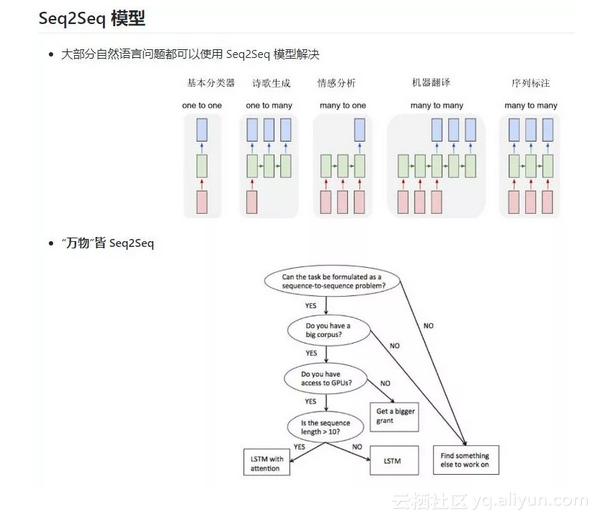
里面内容同样相当丰富,以“自然语言处理基础”为例,下图分别为Seq2Seq模型和语言模型的介绍。
![932ba47b319015cef607aec1fd8095b4f2127c17]()
除了知识总结与资料介绍,相信小伙伴们最关心的还是国内互联网名企的笔试面经了。
百度、腾讯、头条等名企笔试面经:一面二面三面
点击主目录下的“笔试面经”,百度、腾讯、360、字节跳动等互联网名企赫然在列,我们来看看这些大牛企业笔试面试都考点啥。
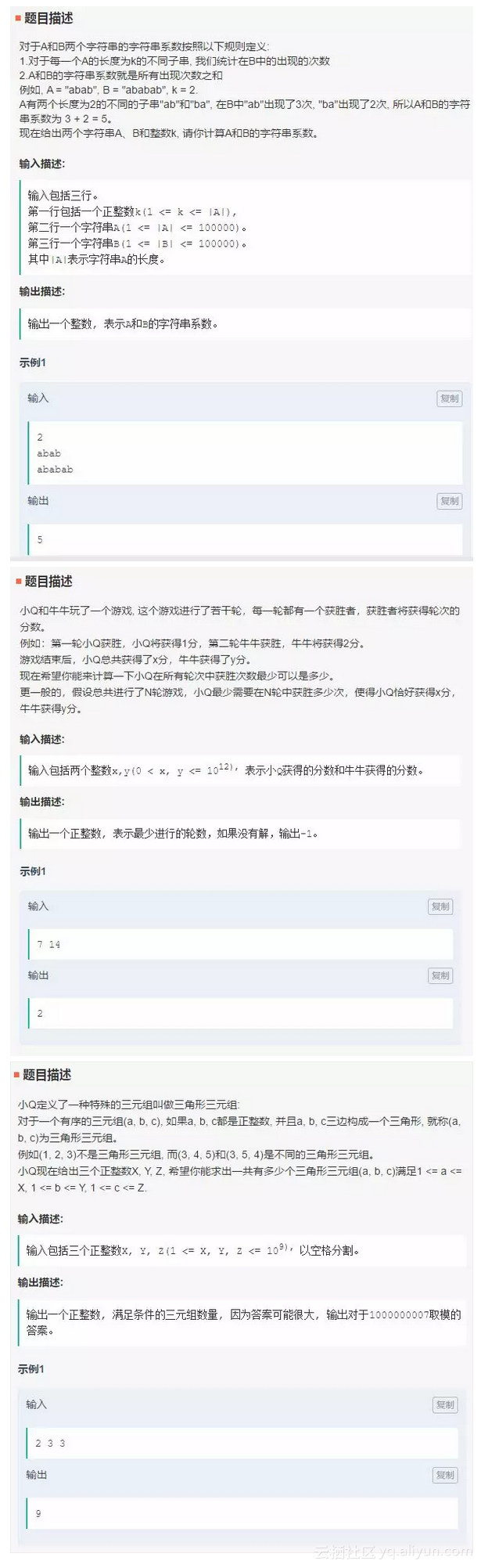
先看腾讯的笔试,更新时间为9月16日,主目录中给出了3道笔试题,分别是字符串系数、小Q与牛牛的游戏、三元组。
每道题的下方都给出了相应的代码和解法,涉及Python和C++语言。下图为第二题的解法代码。
![05d8822d3954ff37f09a27c6302c66b879567f52]()
再来看看百度的笔试,更新时间为9月14日。呈现形式基本一致,收录两道笔试题,字符串计数、寻寻觅觅。
![c714634746a7fa4a60f5b0a1c9f7e0ef7bd7033a]()
主目录下还有不少企业的笔试题收录,感兴趣的小伙伴可以自行食用。
https://github.com/imhuay/Algorithm_Interview_Notes-Chinese/tree/master/D-%E7%AC%94%E8%AF%95%E9%9D%A2%E7%BB%8F
互联网名企笔试面经:面试部分
接下来看面试,这里给出了一位小伙伴面试字节跳动深度学习/NLP方向职位的面试流程,一共四面,全程第一视角,生动形象,简直有身临其境之感!其中还不时穿插面试人自己的内心OS(“不会、瞎说的、尬聊”什么的,小编也是服气),可以说是很耿直了!
不过面试时这再正常不过了,不信你去试试,毕竟你跺你也麻!
来看看这位老兄的面试经历吧!不容易啊!
一面:
自我介绍,聊项目,深度学习基本问题
【算法】手写 K-Means。磕磕绊绊算是写出来一个框架,内部细节全是问题,面试官比较宽容,勉强算过了
二面:
自我介绍,聊项目,深度学习基本问题
【算法】找数组中前 k 大的数字。我说了两个思路:最小堆和快排中的 partition 方法;让我选一个实现,我选的堆方法,然后又让我实现调整堆的方法。
三面:
自我介绍。为什么会出现梯度消失和梯度爆炸。
分别说了下前馈网络和 RNN 出现梯度消失的情况,有哪些解决方法。
因为提到了残差和门机制,所以又问,分别说下它们为什么能缓解梯度消失
因为说残差的时候提到了 ResNet,让我介绍下 ResNet(没用过,随便说了几句)
其他加速网络收敛的方法(除了残差和门机制)
我从优化方法的角度说了一点(SGB 的改进:动量方法、Adam)
提示我 BN,然后我就把 BN 的做法说了一下
然后问 BN 为什么能加速网络的收敛(从数据分布的角度随便说了几句)
传统的机器学习方法(简历上写用过 GBDT),简单介绍下 XGBoost
CART 树怎么选择切分点(基尼系数)
基尼系数的动机、原理(不会)
【算法】直方图蓄水问题,LeetCode 42. 接雨水;
当时太紧张没想出 O(N) 解法,面试一结束就想出来了,哎~
附 AC 代码
class Solution {
public:
int trap(vector<int>& H) {
int n = H.size();
vector<int> dp_fw(H);
vector<int> dp_bw(H);
for(int i=1; i<n; i++) // 记录每个位置左边的最高点
dp_fw[i] = max(dp_fw[i-1], dp_fw[i]);
for(int i=n-2; i>=0; i--) // 记录每个位置右边的最高点
dp_bw[i] = max(dp_bw[i+1], dp_bw[i]);
int ret = 0;
for (int i=1; i<n-1; i++) // 取两侧较矮的点
ret += min(dp_fw[i], dp_bw[i]) - H[i];
return ret;
}
};
四面(非加面)
因为流程出了问题,其实还是三面
【算法】和为 K 的连续子数组,返回首尾位置
LeetCode 560. 和为K的子数组
很熟悉的题,但就是没想出来;然后面试官降低了难度,数组改成有序且为正整数,用双指针勉强写了出来;但是边界判断有问题,被指了出来;然后又问无序的情况或者有负数的情况能不能也用双指针做,尬聊了几分钟,没说出个所以然。
如何无监督的学习句子表示
我说 Self-Attention,让我把公式写出来,因为写的不清楚,让我写原始的 Attention
然后问怎么训练,损失函数是什么(没说出来,除了词向量我基本没碰过无监督任务,而且我认为词向量也算不上无监督...)
如何无监督的学习一个短视频的特征表示
抽取关键帧,然后通过 ResNet 等模型对每一帧转化为特征表示,然后对各帧的特征向量做拼接或者直接保存为二维特征(瞎说的,别说视频,我连图像都没做过)
再来看一个今日头条算法工程实习生岗位的面试:
一面:
自我介绍;二分查找;
Algorithm_for_Interview/常用子函数/二分查找模板.hpp
判断链表是否有环;
Algorithm_for_Interview/链表/链表中环的入口结点.hpp
将数组元素划分成两部分,使两部分和的差最小,数组顺序可变;
Algorithm_for_Interview/查找与排序/暴力搜索_划分数组使和之差最小.hpp
智力题,在一个圆环上随机添加3个点,三个点组成一个锐角三角形的概率;
../数学问题/#1
推导逻辑斯蒂回归、线性支持向量机算法;
../机器学习/逻辑斯蒂回归推导
../机器学习/线性支持向量机推导
二面:
在一个圆环上随机添加3点,三个点组成一个锐角三角形的概率,用积分计算上述概率。用程序解决上述问题。
多次采样求概率,关键是如何判断采样的三个点能否构成锐角三角形,不同的抽象会带来不同的复杂度。
最直接的想法是,根据边长关系,此时需要采样三个 x 坐标值,相应的 y 坐标通过计算得出,然后计算三边长度,再判断,循环以上过程,计算形成锐角的比例。
更简单的,根据 ../数学/#1 中提到的简单思路,原问题可以等价于“抛两次硬币,求两次均为正面的概率”——此时,只需要采样两个(0, 1)之间的值,当两个值都小于 0.5 意味着能构成锐角三角形。
深度学习,推导反向传播算法,知道什么激活函数,不用激活函数会怎么样,ROC与precesion/recall评估模型的手段有何区别,什么情况下应该用哪一种?深度学习如何参数初始化?
介绍kaggle项目,titanic,用到了哪些框架,用到了哪些算法;
三面:
自我介绍。分层遍历二叉树,相邻层的遍历方向相反,如第一层从左到右遍历,下一层从右向左遍历;
介绍AdaBoost算法。介绍梯度下降,随机梯度下降。写出逻辑斯蒂回归的损失函数。C++,虚函数,虚析构函数。
先说到这里,Github库中还有更多资料,只待你去探索。当然,也欢迎你把自己的面试经验简单总结,留给后来的小伙伴们参考哦~
原文发布时间为:2018-09-7
本文作者: AI派
本文来自云栖社区合作伙伴“ ”,了解相关信息可以关注“ ”。