基于 HanLP 的 Elasticsearch 中文分词插件,核心功能:
兼容 ES 5.x-7.x;
内置词典,无需额外配置即可使用;
支持用户自定义词典;
支持远程词典热更新(待开发);
内置多种分词模式,适合不同场景;
拼音过滤器(待开发);
简繁体转换过滤器(待开发)。
版本
插件版本和 ES 版本一致,直接下载对应版本的插件进行安装即可。
·插件开发完成时,最新版本已经为 6.5.2 了,所以个人只对典型的版本进行了测试;
·5.X 在 5.0.0、5.5.0 版本进行了测试;
·6.X 在 6.0.0、6.3.0、6.4.1、6.5.1 版本进行了测试;
·7.X 在 7.0.0 版本进行了测试。
安装使用
下载编译
git clone 对应版本的代码,打开 pom.xml 文件,修改 <elasticsearch.version>6.5.1</elasticsearch.version> 为需要的 ES 版本;然后使用 mvn package 生产打包文件,最终文件在 target/release 文件夹下。
打包完成后,使用离线方式安装即可。
使用默认词典
·在线安装:.\elasticsearch-plugin install https://github.com/AnyListen/elasticsearch-analysis-hanlp/releases/download/vA.B.C/elasticsearch-analysis-hanlp-A.B.C.zip
·离线安装:.\elasticsearch-plugin install file:///FILE_PATH/elasticsearch-analysis-hanlp-A.B.C.zip
离线安装请把 FILE_PATH 更改为 zip 文件路径;A、B、C 对应的是 ES 版本号。
使用自定义词典
默认词典是精简版的词典,能够满足基本需求,但是无法使用感知机和 CRF 等基于模型的分词器。
HanLP 提供了更加完整的词典,请按需下载。
词典下载后,解压到任意目录,然后修改插件安装目录下的 hanlp.properties 文件,只需修改第一行
root=D:/JavaProjects/HanLP/
为 data 的父目录即可,比如 data 目录是 /Users/hankcs/Documents/data,那么 root=/Users/hankcs/Documents/。
使用自定义配置文件
如果你在其他地方使用了 HanLP,希望能够复用 hanlp.properties 文件,你只需要修改插件安装目录下的 plugin.properties 文件,将 configPath 配置为已有的 hanlp.properties 文件地址即可。
内置分词器
分析器(Analysis)
·hanlp_index:细粒度切分
·hanlp_smart:常规切分
·hanlp_nlp:命名实体识别
·hanlp_per:感知机分词
·hanlp_crf:CRF分词
·hanlp:自定义
分词器(Tokenizer)
·hanlp_index:细粒度切分
·hanlp_smart:常规切分
·hanlp_nlp:命名实体识别
·hanlp_per:感知机分词
·hanlp_crf:CRF分词
·hanlp:自定义
自定义分词器
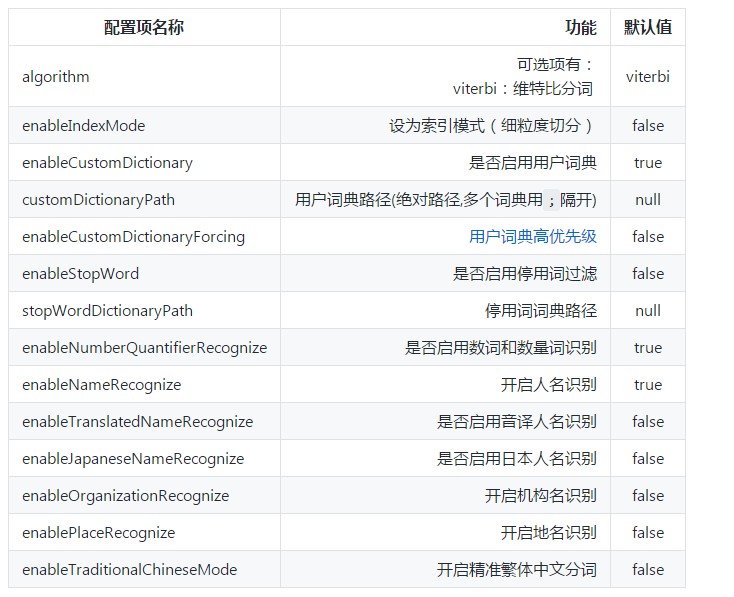
插件有较为丰富的选项允许用户自定义分词器,下面是可用的配置项:
![f4725f8f644136b4659f321ce607492772fe6cc7]()
案例展示:
# 创建自定义分词器
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "hanlp",
"algorithm": "viterbi",
"enableIndexMode": "true",
"enableCustomDictionary": "true",
"customDictionaryPath": "",
"enableCustomDictionaryForcing": "false",
"enableStopWord": "true",
"stopWordDictionaryPath": "",
"enableNumberQuantifierRecognize": "true",
"enableNameRecognize": "true",
"enableTranslatedNameRecognize": "true",
"enableJapaneseNameRecognize": "true",
"enableOrganizationRecognize": "true",
"enablePlaceRecognize": "true",
"enableTraditionalChineseMode": "false"
}
}
}
}
}
# 测试分词器
POST my_index/_analyze
{
"analyzer": "my_analyzer",
"text": "张惠妹在上海市举办演唱会啦"
}
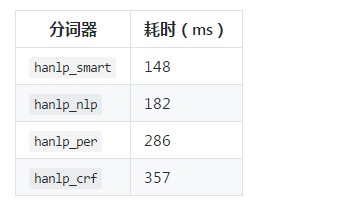
分词速度(仅供参考)
借助 _analyze API(1核1G单线程),通过改变分词器类型,对 2W 字的文本进行分词,以下为从请求到返回的耗时:
![46508cb37751adf46052310fa9c67d444a2baca8]()