市场上对数据科学家的要求特别多:需要掌握机器学习、计算机科学、统计学、数学、数据可视化,深度学习等知识。要想全部掌握这些方面的知识,科学家需要学习数十种语言、框架和技术。那么,为此数据科学家应该如何合理地分配时间,该掌握哪些技能呢?
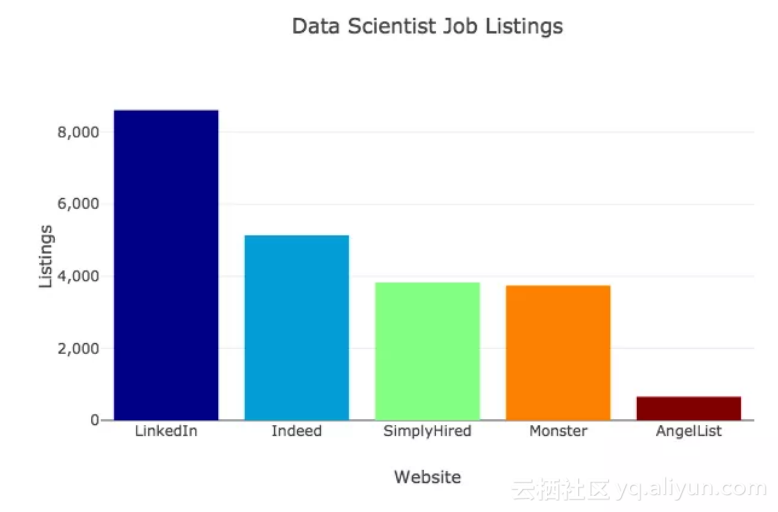
在本文中,我对求职网站进行搜索,找出对数据科学家的技能要求。我分别分析了通常的数据科学技能和特定语言以及工具。我具体搜索了2018年10月10日LinkedIn、Indeed、SimplyHired、Monster、以及AngelList这些求职网站。以下图表显示了在每个网站中发布了多少数据分析师工作。
![fdbfce6c0afb5cdd1598d806562f8e86921e27af]()
我分析了许多工作列表和调查,想列出当中最常见的技能要求。“管理”这类词没有包含在内,因为许多求职发布中都会包含这个词。
全部搜索都是针对美国地区,关键词中带有“数据科学家”的职位发布,并使用精确匹配搜索减少了结果数量。但是,这种方法确保结果与数据科学家职位相关,并且影响所有搜索项。
AngelList中提供的是招聘数据科学家的公司数量,而不是职位数量。我将AngelList排除在这两种分析之外,因为它的搜索算法是OR的逻辑搜索,而且无法将其修改为AND。如果你搜索"数据科学家""TensorFlow"这类关键词,AngelList表现还不错,但如果你搜索"数据科学家""react.js"也会返回不招聘数据科学家的公司。
Glassdoor也被我排除在外。网站上表示美国目前发布了26,263个"数据科学家"的职位,然而实际只显示了不到900个的职位。此外,Glassdoor发布的数据科学家职位也不可能比起其他主流平台的三倍要多。
最终分析采用了在LinkedIn上400多个职位信息分析通用技能,针对200多个职位信息分析特定技能。当中有一些重复,结果记录在Google Sheet中。
https://docs.google.com/spreadsheets/d/1df7QTgdAOItQJadLoMHlIZH3AsQ2j2_yoyvHOpsy9qU/edit?usp=sharing
我下载了.csv文件并将其导入JupyterLab。然后,我计算出每个百分比,并对招聘网站上的数量进行平均。
此外,我将结果与Glassdoor 在2017年上半年发布的数据科学家职位研究进行比较,并且结合KDNuggets的调查信息。从中可以发现,对于数据科学家而言,有些技能变得越来越重要,而其他技能则逐渐不再重要。之后我们将具体看到。
Glassdoor
https://www.glassdoor.com/research/data-scientist-personas/
KDNuggets
https://www.kdnuggets.com/2018/05/poll-tools-analytics-data-science-machine-learning-results.html/2
可以在我的Kaggle Kernel 中看到交互式图表和分析。我使用Plotly进行可视化,在写本文时,使用Plotly和JupyterLab有一些难点,具体说明在 Kaggle Kernel 最后的Plotly文档中
Kaggle
https://www.kaggle.com/discdiver/the-most-in-demand-skills-for-data-scientists/
Plotly 文档
https://github.com/plotly/plotly.py
1. 通用技能
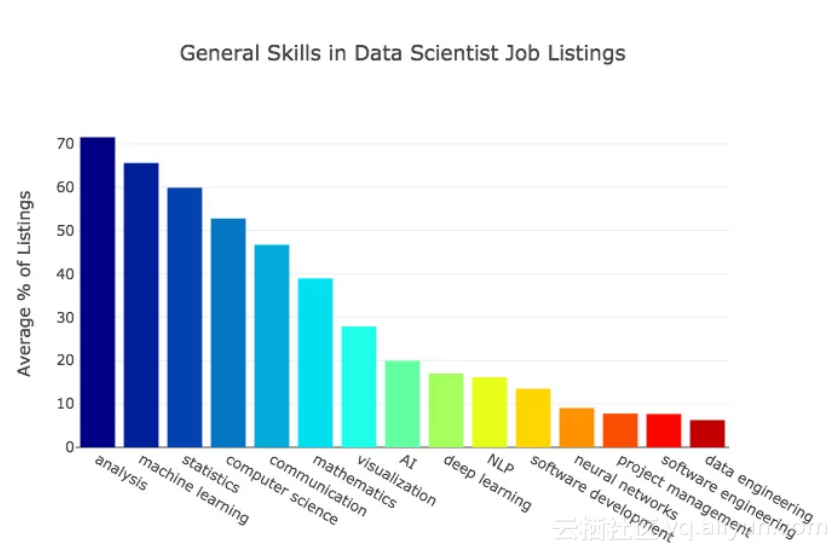
以下是雇主最希望数据科学家具备的通用技能。
![4558963c5918bf951fe0812a38262249401035ab]()
结果表明,通用技能中数据分析和机器学习是数据科学家工作的核心。从数据中收集分析见解是数据科学的主要功能。机器学习是关于开发创建预测性能的系统,这也是十分受欢迎的技能。
数据科学家需要统计学和计算机科学技能,这并不惊讶。统计学、计算机科学和数学也是大学专业,这也可能提高了这些技能出现的频率。
有趣的是,近一半的职位要求中都提到了沟通能力。数据科学家需要能够传达自己的见解,并与他人合作。
人工智能和深度学习并不像其他术语那样经常出现。它们是机器学习的子集,深度学习被用于越来越多的机器学习任务中,之前主要是使用其他算法。如今,大多数用于自然语言处理问题的最佳机器学习算法是深度学习算法。我预计将来在职位信息中,深度学习技能将被越来越明确,而且机器学习将与深度学习越来越类似。
那么雇主希望数据科学家使用哪些特定软件工具?接下来,让我们看到这个问题。
2. 技术技能
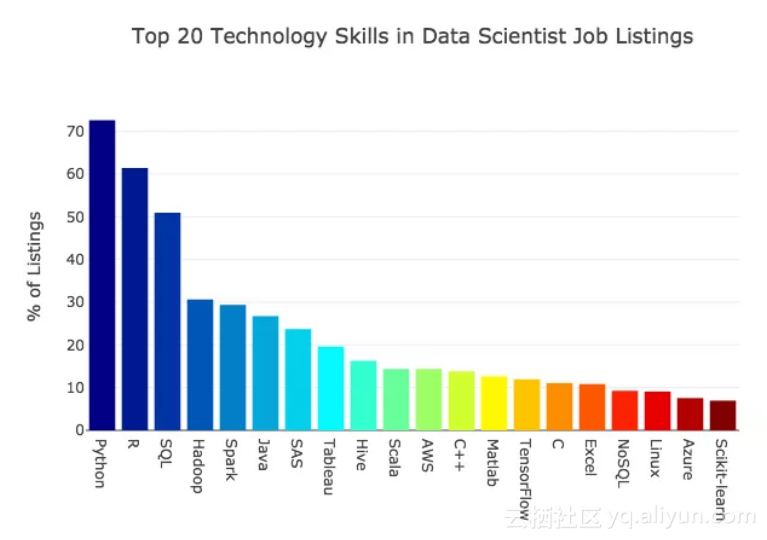
以下是雇主最希望数据科学家掌握的前20种特定语言,库和科技工具。
![b0bb140dad29a9344ad1946343280c694322c8d9]()
让我们简要介绍一下最常见的技术技能。
![24aca1c60bcbbbbb4d68bc462e60be3063b309b8]()
Python是最受欢迎的语言。这种开源语言已经非常普及。对初学者而言,这种语言很好上手,有许多支持的资源。绝大多数数据科学工具都与之兼容。Python是数据科学家主要的使用语言。
![0d9a02288143607e517760d672762ef8d5a5436d]()
R语言与Python相差不远。它曾经是数据科学的主要语言,R语言的需求仍然很大。这种开源语言的根源在于统计数据,它非常受统计学家的欢迎。
Python或R语言是从事数据科学工作的必备条件。
![ae3ae90b90159cdee5c570b5454aa286f3e9beb8]()
SQL的需求也很高。SQL指的是Structured Query Language(结构化查询语言),是与数据库交互的主要方式。在数据科学领域,SQL有时会被忽视,但如果想找数据科学方面的工作,这项技能是很重要的。
接下来是Hadoop和Spark,它们都是Apache的大数据开源工具。
Apache Hadoop是一个开源软件平台,用于分布式存储和分布式处理大型数据集,这些数据集是由商用硬件构建的计算机集群。
Apache Spark是快速的内存数据处理引擎,具有强大且富有表现力的开发API,能够让数据工作者有效地执行流、机器学习或SQL,这些情况需要对数据集进行快速迭代访问。
与Python,R和SQL相比,很少有求职者具备这些技能。如果你会Hadoop和Spark的经验,那么你更有可能在求职中成功。
![7be58be3b1942e8dd8cf6d47b3082a83ef84e202]()
接下来是Java和SAS。我惊讶地发现在职位描述中,这两种语言出现的频率也很高。通常,Java和SAS在数据科学界的关注度都不高。
![7fd628dcf60f2bcb3a8dc65fc04a59ac71ca2e3a]()
接下来是Tableau。这个分析平台和可视化工具功能强大,易于使用且越来越受欢迎。它有一个免费的公共版本,但如果你想保持数据私密就需要花钱。如果你不熟悉Tableau,那么强烈推荐Udemy的 Tableau 10 A-Z 。
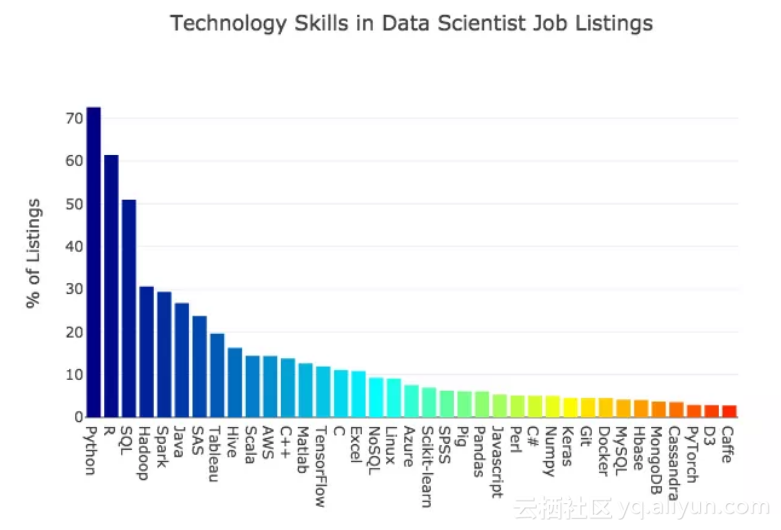
下图技能列表显示的语言、框架和其他数据科学软件工具更多。
![e2f818d4af11ca65c5b4ddfab6fb03e0d230f50f]()
3. 历史比较
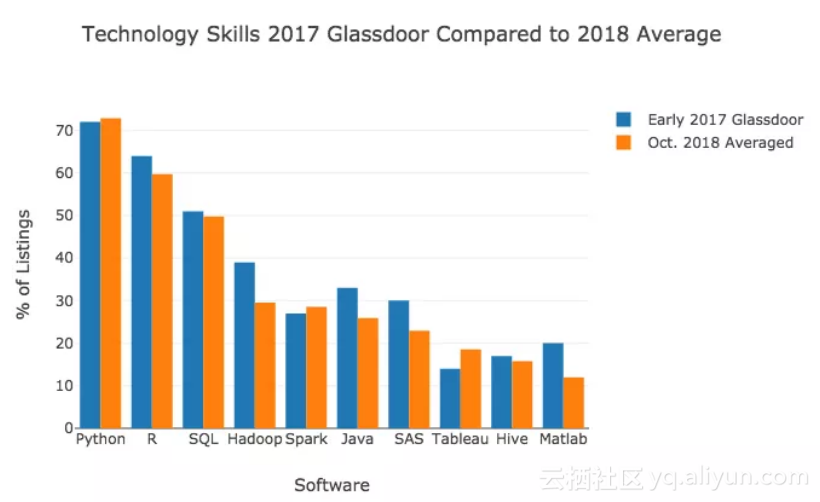
GlassDoor 曾在网站上发布了2017年1月至2017年7月期间,数据科学家的10种最常见的软件技能。这里将GlassDoor的数据与LinkedIn,Indeed,SimplyHired和Monster在2018年10月的平均值进行比较。
![71c09b0f7bf5f4e7700c9f9ccfdf8385708336a9]()
结果非常相似。根据我的分析和GlassDoor的调查,Python、R和SQL都是是最受欢迎的技能。而且前九个技能排名稍微有些不同。
结果表明,与2017年上半年相比,R语言、Hadoop、Java、SAS和MatLab的需求量减少,而Tableau的需求量增加。根据局KDnuggets开发人员调查等分析,这也并不意外。在这份调查中显示,R语言、Hadoop、Java和SAS在近年来使用量呈都下降趋势,Tableau呈明显的上升趋势。
4. 建议
根据这些分析的结果,以下是对数据科学家的一些建议。
● 证明自己的数据分析能力,并专注熟练掌握机器学习。
● 提高你的沟通技巧。推荐阅读《Made to Stick》这本书,帮助你提升自己观点的影响力。还可以试试Hemmingway Editor这款app,提高写作的逻辑性。
● 掌握深度学习框架。精通深度学习框架在机器学习方面越来越重要。
● 如果你在犹豫选择Python还是R语言之间做出选择,请选择Python。如果你数量掌握Python,那么可以也考虑学习R语言,这会让你在行业中更占优势。
当雇主在寻找具有Python技能的数据科学家时,他们也期望求职者掌握常见的Python数据科学库:numpy、pandas、scikit-learn和matplotlib。如果你在学习这些工具,建议你使用以下资源:
●
DataCamp,DataQuest
两者都是价格合理的在线SaaS数据科学教育产品,你可以在编程时学习,当中都教授了许多技术工具。
●
Data School
拥有各种资源,还包括一系列很赞的YouTube视频,解释各种数据科学概念。
●
McKinney,《Python for Data Analysis 》
本书注重pandas,还讨论了基础的numpy和scikit-learn等知识。
● Müller,Guido《Introduction to Machine Leaning with Python》
Müller是scikit-learn的主要维护者。这是一本关于用scikit-learn学习机器学习的好书。
如果你想学习深度学习,我建议先学习Keras或FastAI,然后在学习TensorFlow或PyTorch。Chollet的《Deep Learning with Python》这本书是学习Keras的绝佳资源。
除此之外,我建议你了解你感兴趣的内容,尽管这里需要考虑到时间分配等因素。
![23b7fc62589fa1f7e95b94d2d9843aa96619e0ae]()
如果你想通过招聘网站找数据科学家工作,我建议试试LinkedIn,这上面可找到的工作信息是最多的。
在招聘网站找公司时,关键词很重要。关键词方面“ 数据科学 ”得到的结果会是“ 数据科学家 ”的3倍。但是,如果你想准确地找数据科学家的工作,那么最好还是搜索“ 数据科学家 ”。
我建议你制作一个在线作品集,能够很好地展示你的数据科学技能。还建议在你的LinkedIn个人资料中注明自己的技能。
如果你想查看本文中交互式图表及当中使用的代码,请查看我的Kaggle Kernel。
https://www.kaggle.com/discdiver/the-most-in-demand-skills-for-data-scientists/
原文发布时间为:2018-10-25