一、下载
https://www.elastic.co/cn/products/kibana
二、安装
tar -zxvf kibanaxxx.tar.gz
cd kibana_HOME
三、修改配置
vim config/kibana.yml
# 将默认配置改成如下:
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.url: "http://127.0.0.1:9201" //修改成自己集群的端口号
kibana.index: ".kibana"
四、运行 启动
bin/kibana
启动后打开浏览器访问 http://127.0.0.1:5601 浏览 kibana 界面:
五、演示
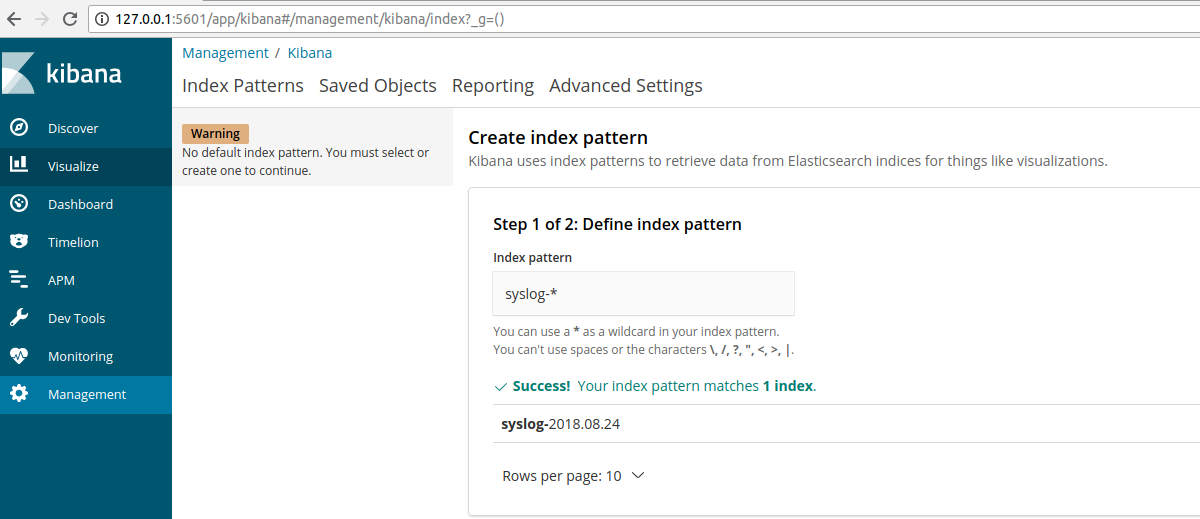
上图中,提示不能获取映射,即 Elasticsearch 中的索引。我们需要手动配置。在 Index Pattern 下边的输入框中输入 syslog-*,它是 Elasticsearch 中的一个索引名称开头。(syslog是我已经创建好的index)
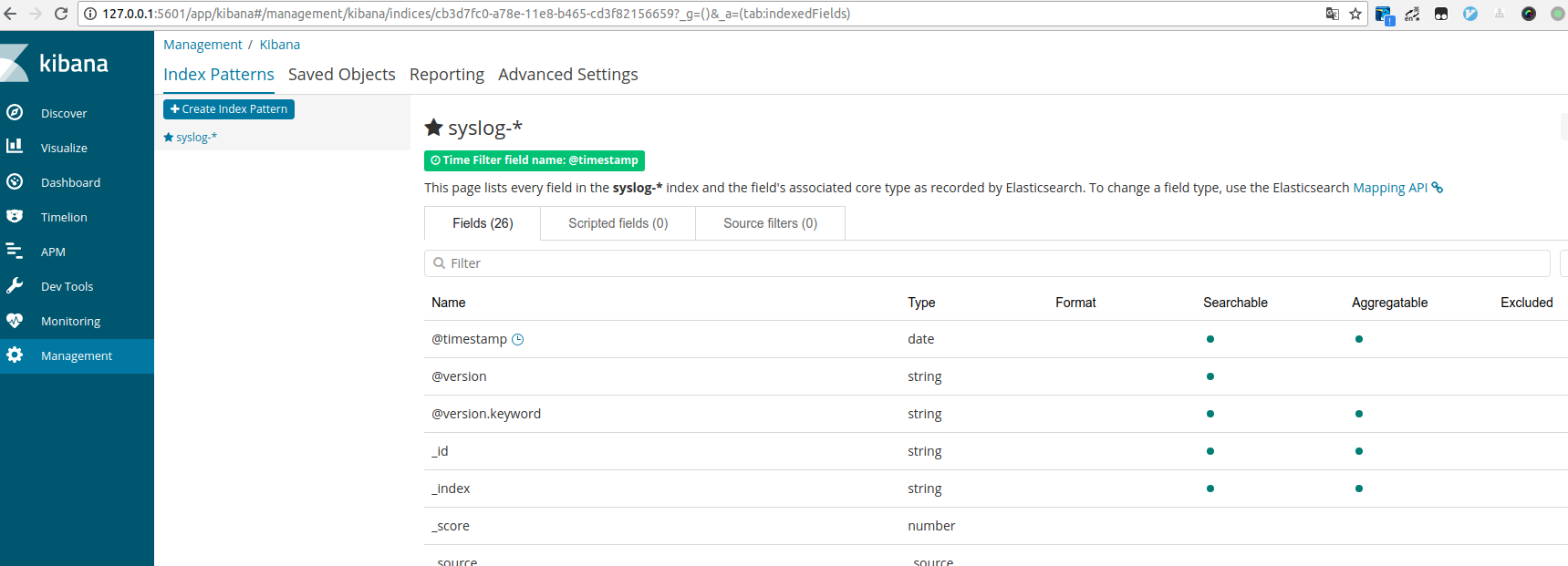
Kibana 会自动检测在 Elasticsearch 中是否存在该索引名称,如果有,则下边出现 “Create” 按钮,我们点击进行创建并来到如下界面:
-
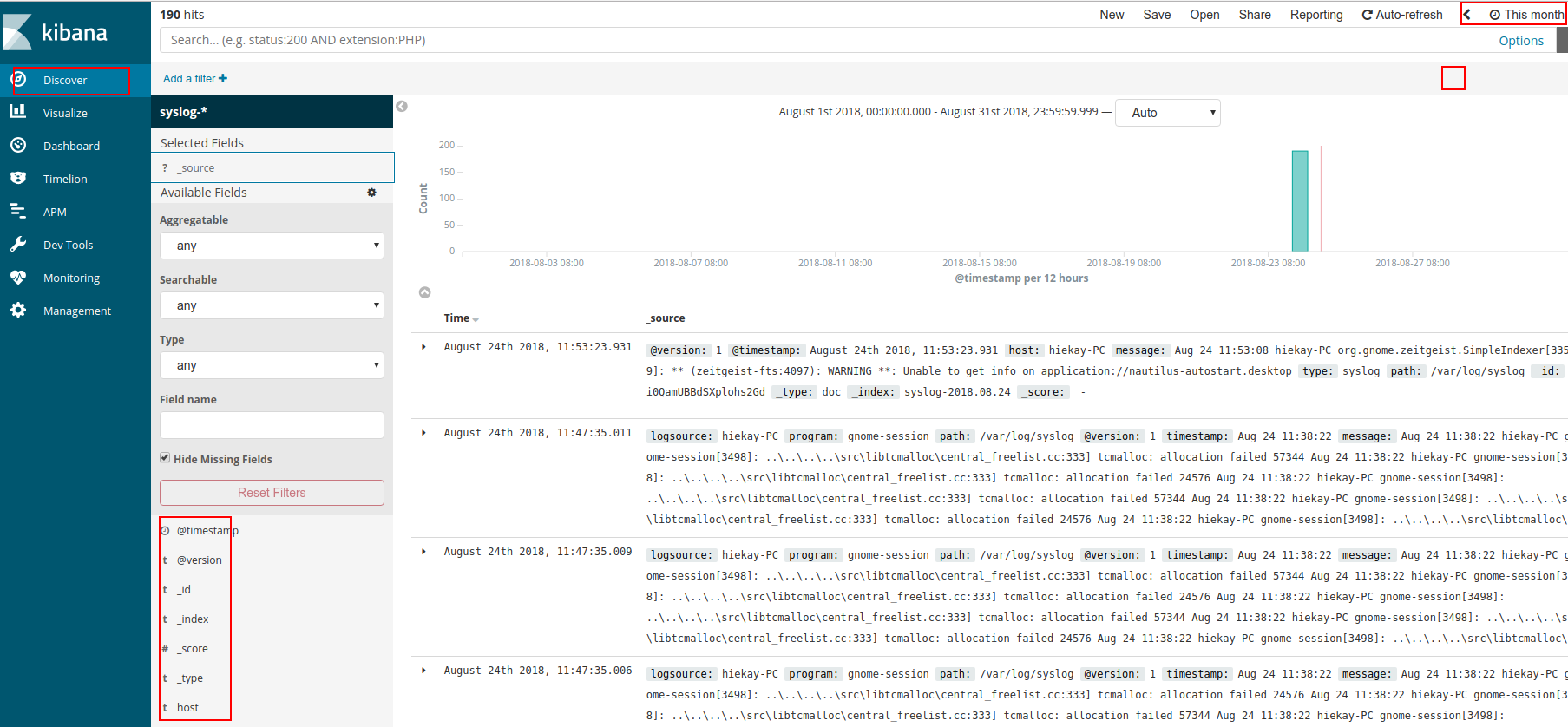
1、Discovery
“Discovery” 菜单界面主要用于通过搜索请求,过滤结果,查看文档数据。可以查询搜索请求的文档总数,获取字段值的统计情况并通过柱状图进行展示。
点击左侧 “Discovery” 菜单,来到如下界面:
-
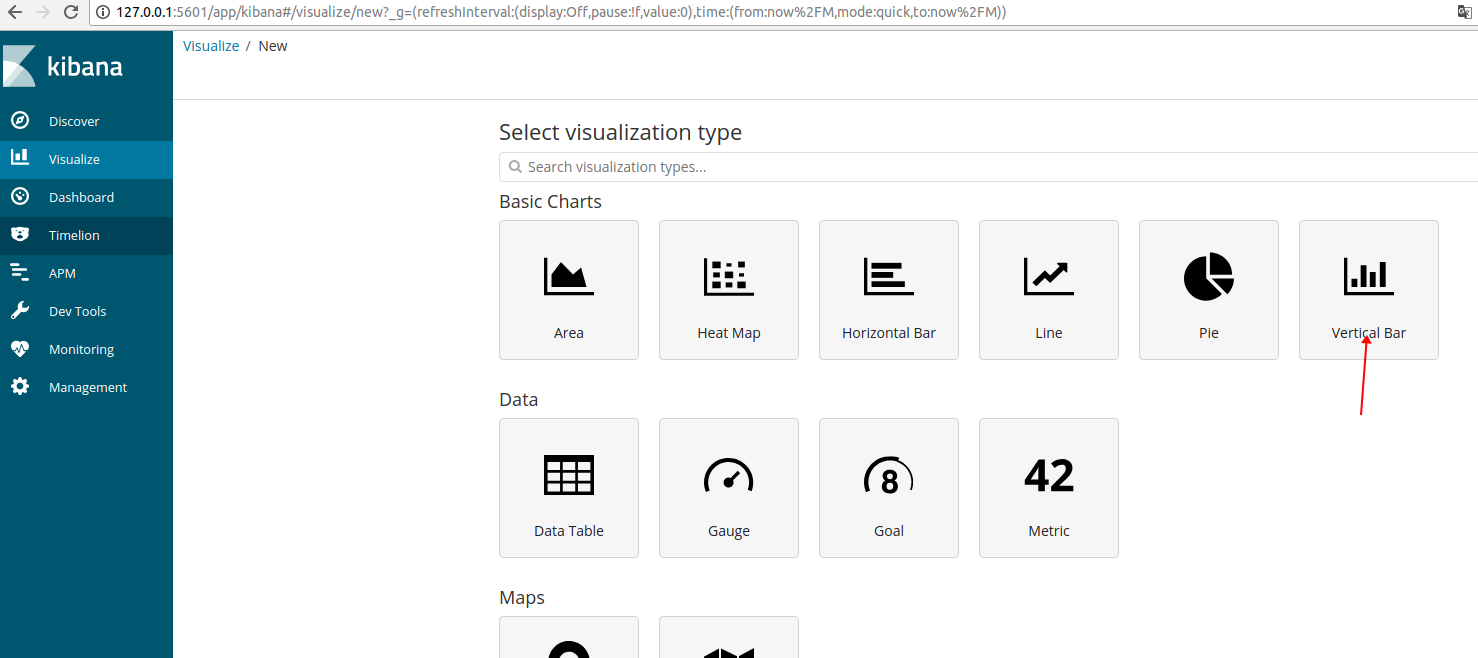
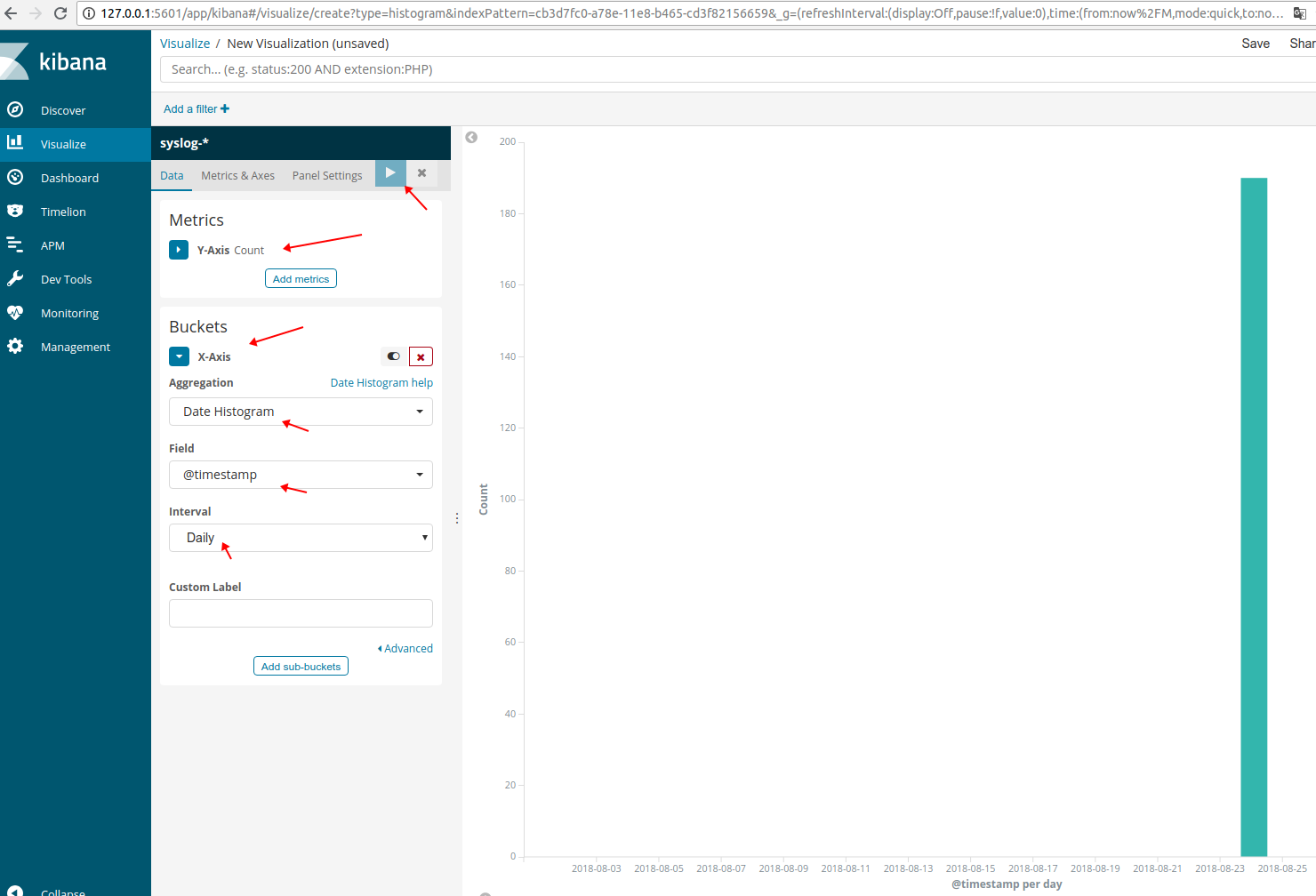
2、Visualize
“Visualize” 菜单界面主要用于将查询出的数据进行可视化展示,且可以将其保存或加载合并到 Dashboard 中。
点击左侧 “Visualize” 菜单,再点击界面中间的 “Create a visualization” 按钮来到如下界面:
本次测试选择柱状图演示,点击柱状图:
点击右上角“Save” 按钮可以进行保存。笔者将该可视化保存为 “syslog access”。
-
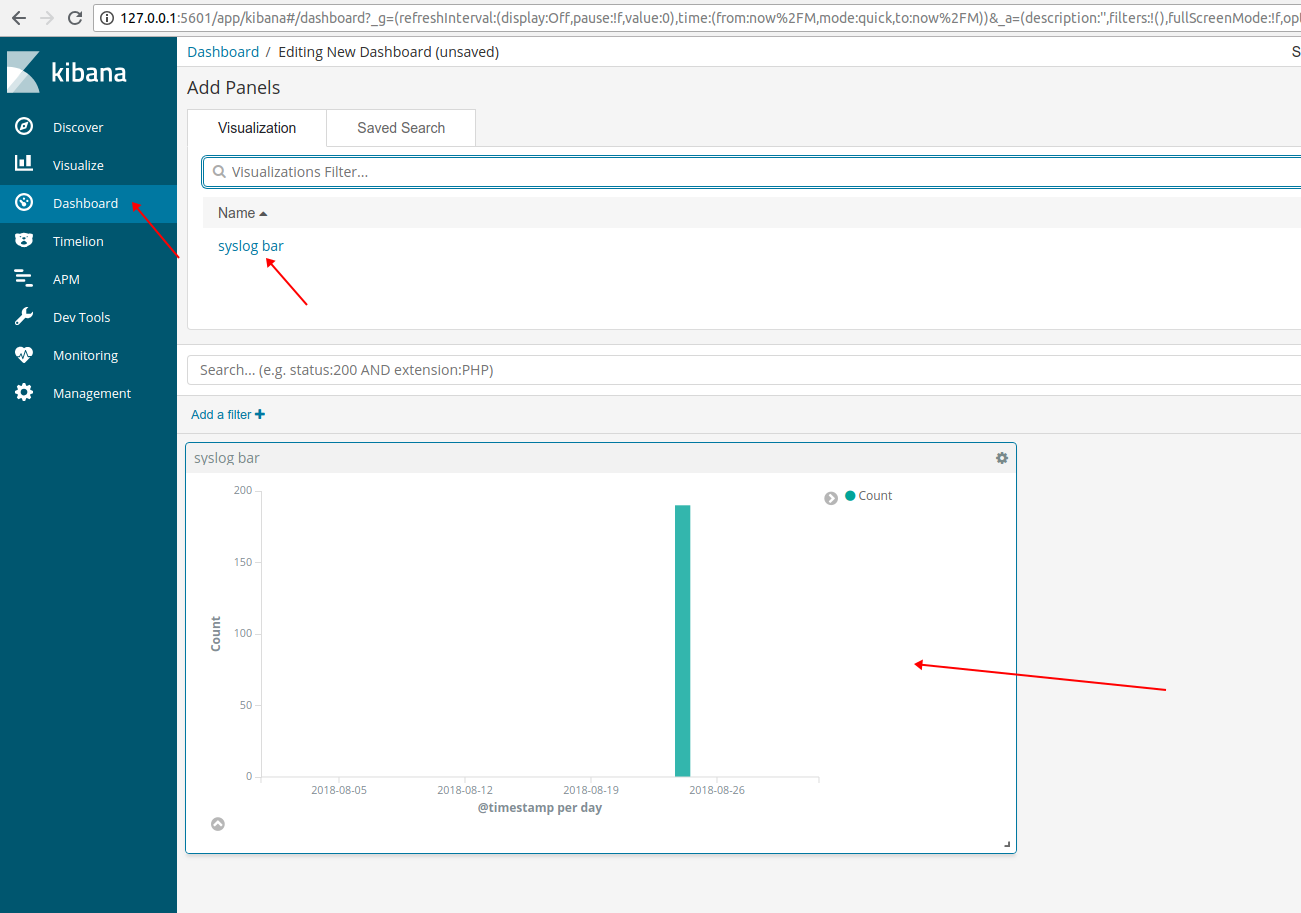
3、Dashboard
在“Dashboard” 菜单界面中,我们可以自由排列一组已保存的可视化数据。
点击左侧 “Dashboard” 菜单,再点击界面中间的 “Create a dashboard” 按钮进行创建:
-
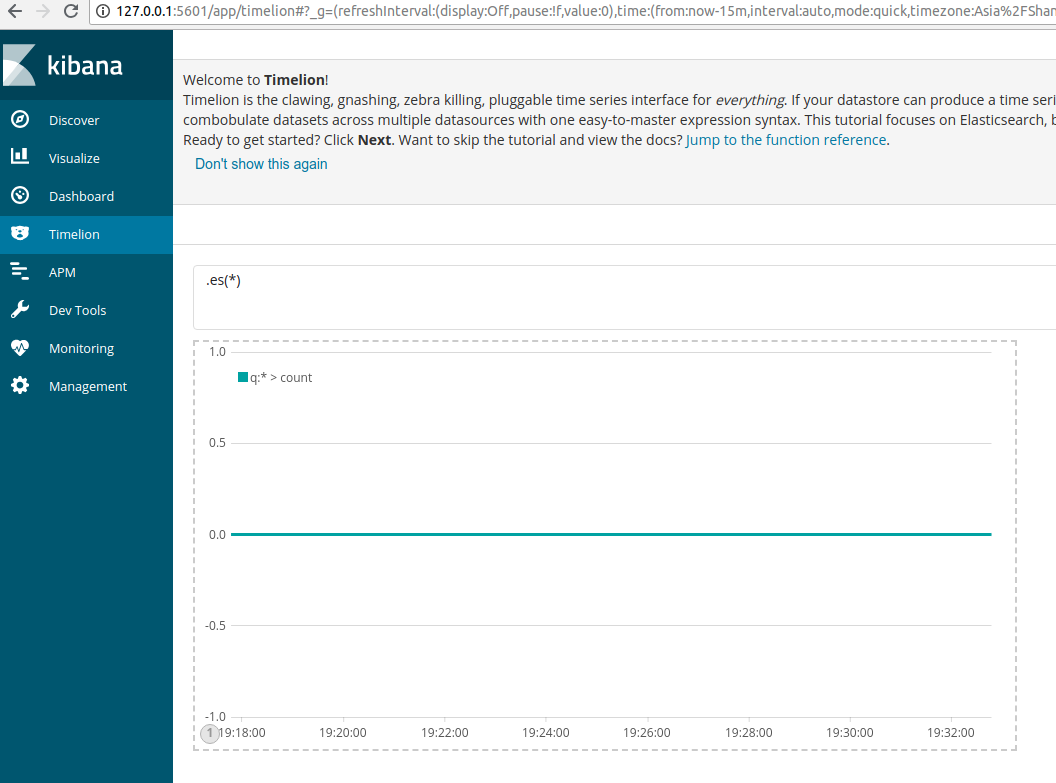
4、Timelion
Timelion 是一个时间序列数据的可视化,可以结合在一个单一的可视化完全独立的数据源。它是由一个简单的表达式语言驱动的,用来检索时间序列数据,进行计算,找出复杂的问题的答案,并可视化的结果。
-
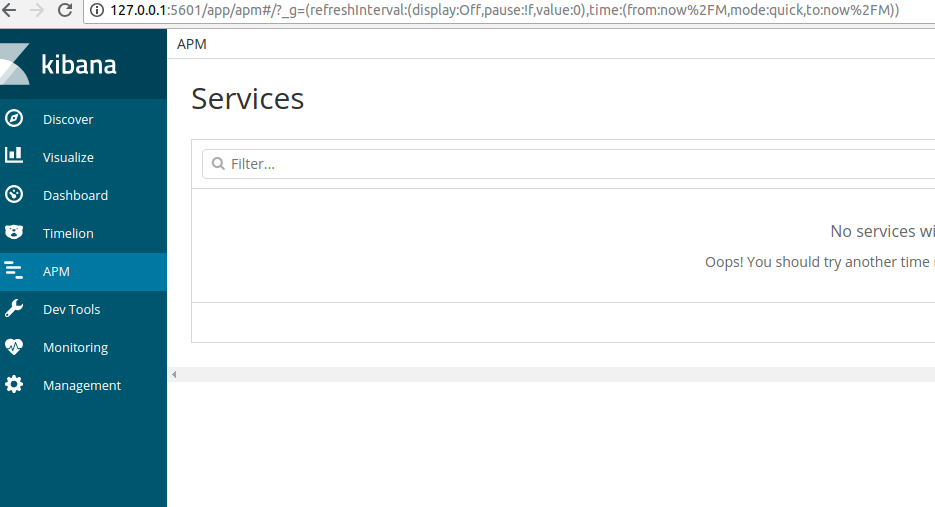
5、APM
应用程序性能监视(APM)从应用程序内部收集深入的性能指标和错误。它允许您实时监控数千个应用程序的性能。
需要先安装apm server 和agent , 移步去看小编另一篇博文apm server
-
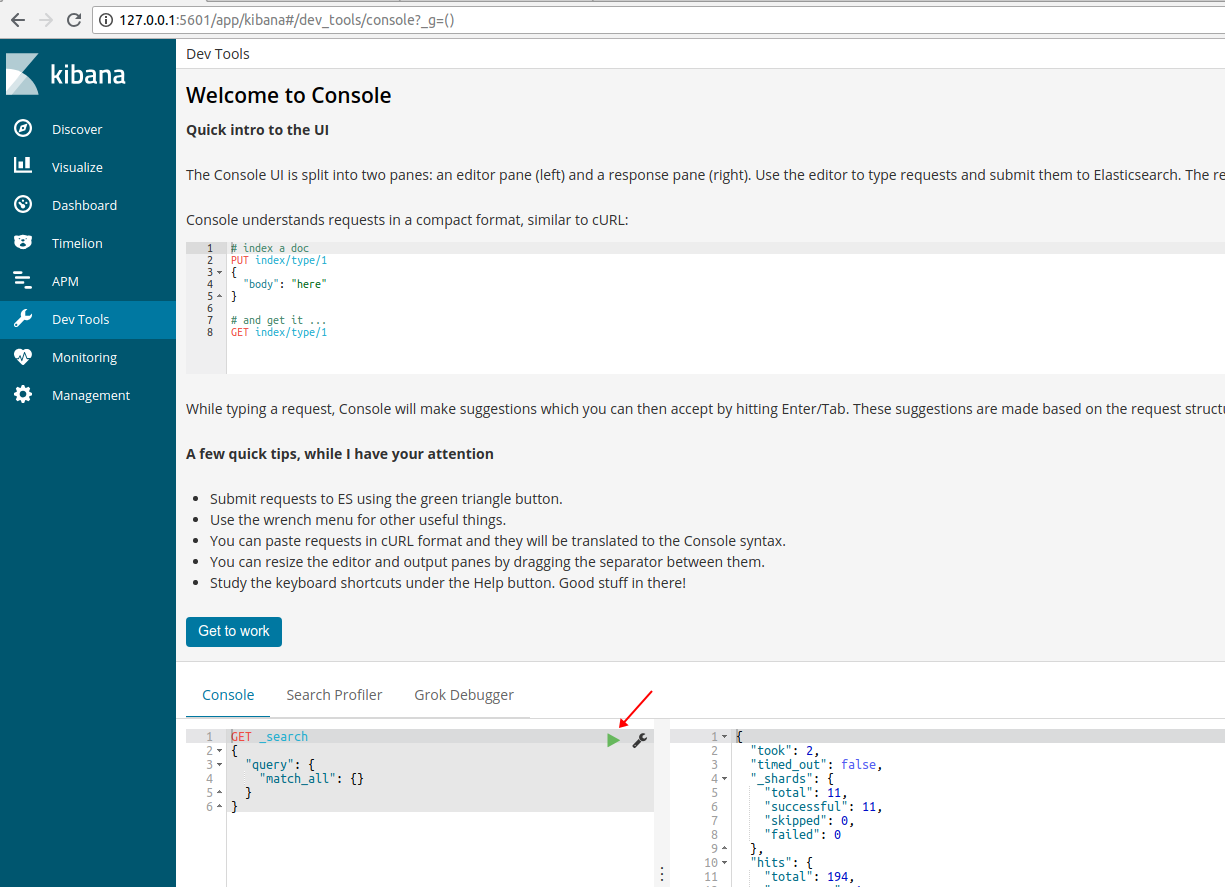
6、Dev Tools
“Dev Tools” 菜单界面使用户方便的通过浏览器直接与 Elasticsearch 进行交互,发送 RESTFUL 请求可以对 Elasticsearch 数据进行增删改查:
-
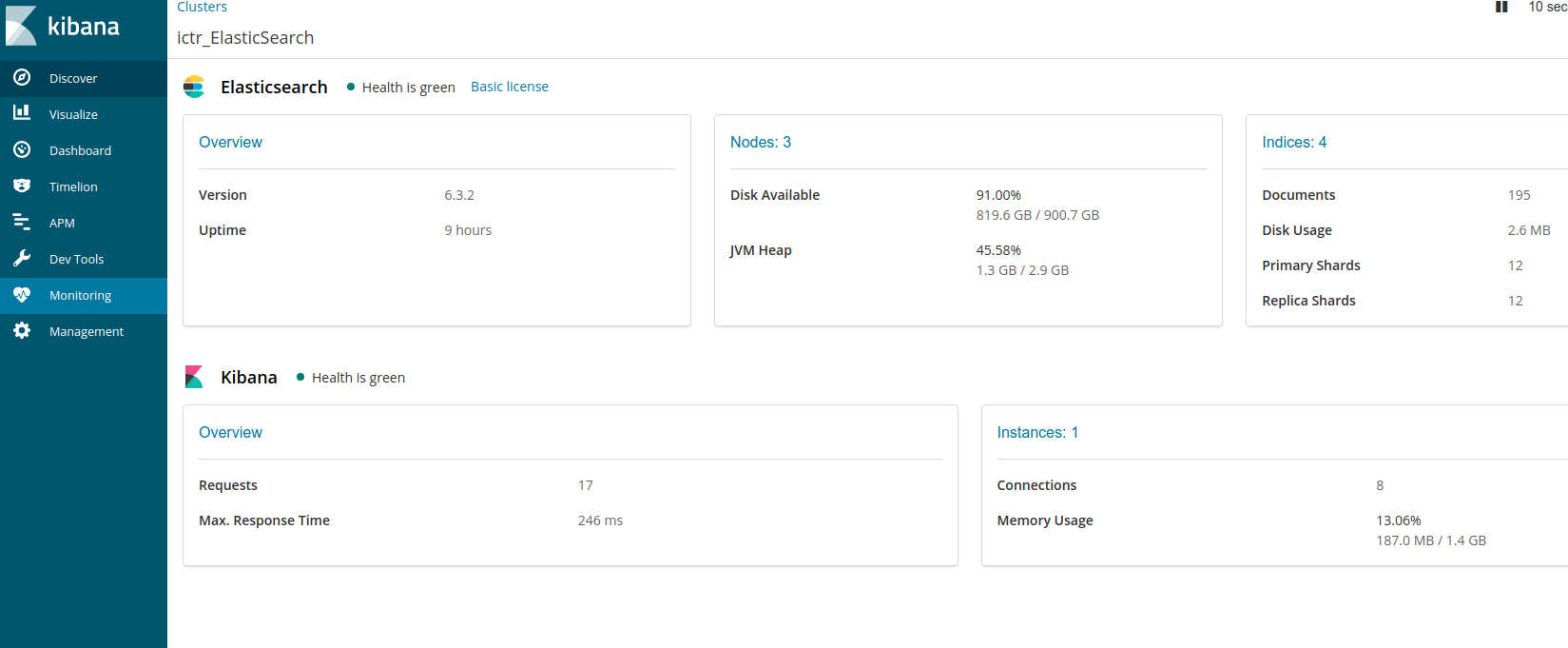
7 Monitoring
监控系统