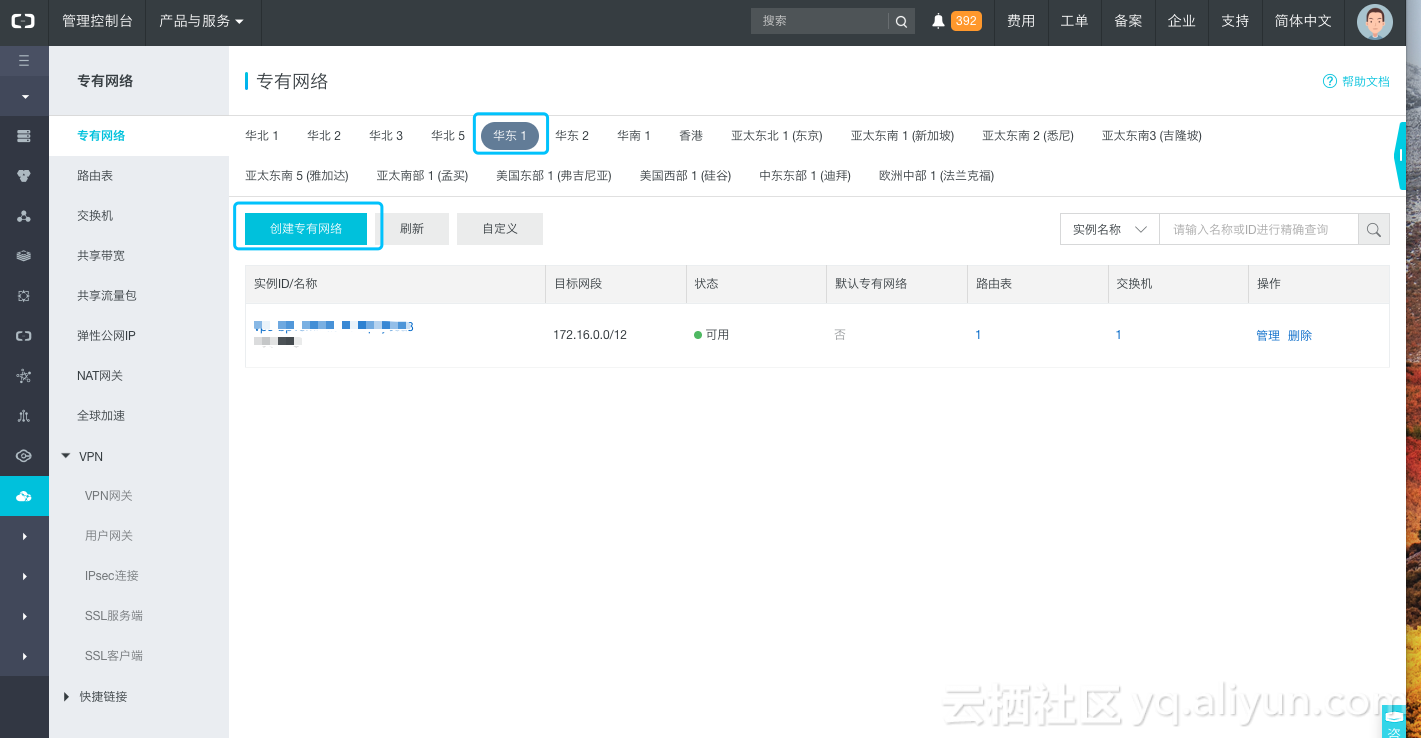
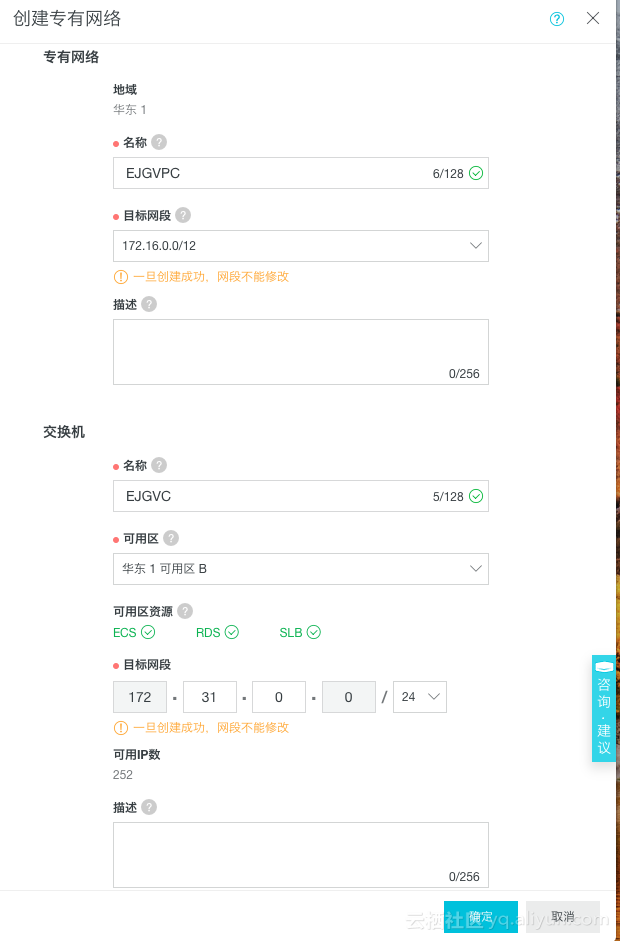
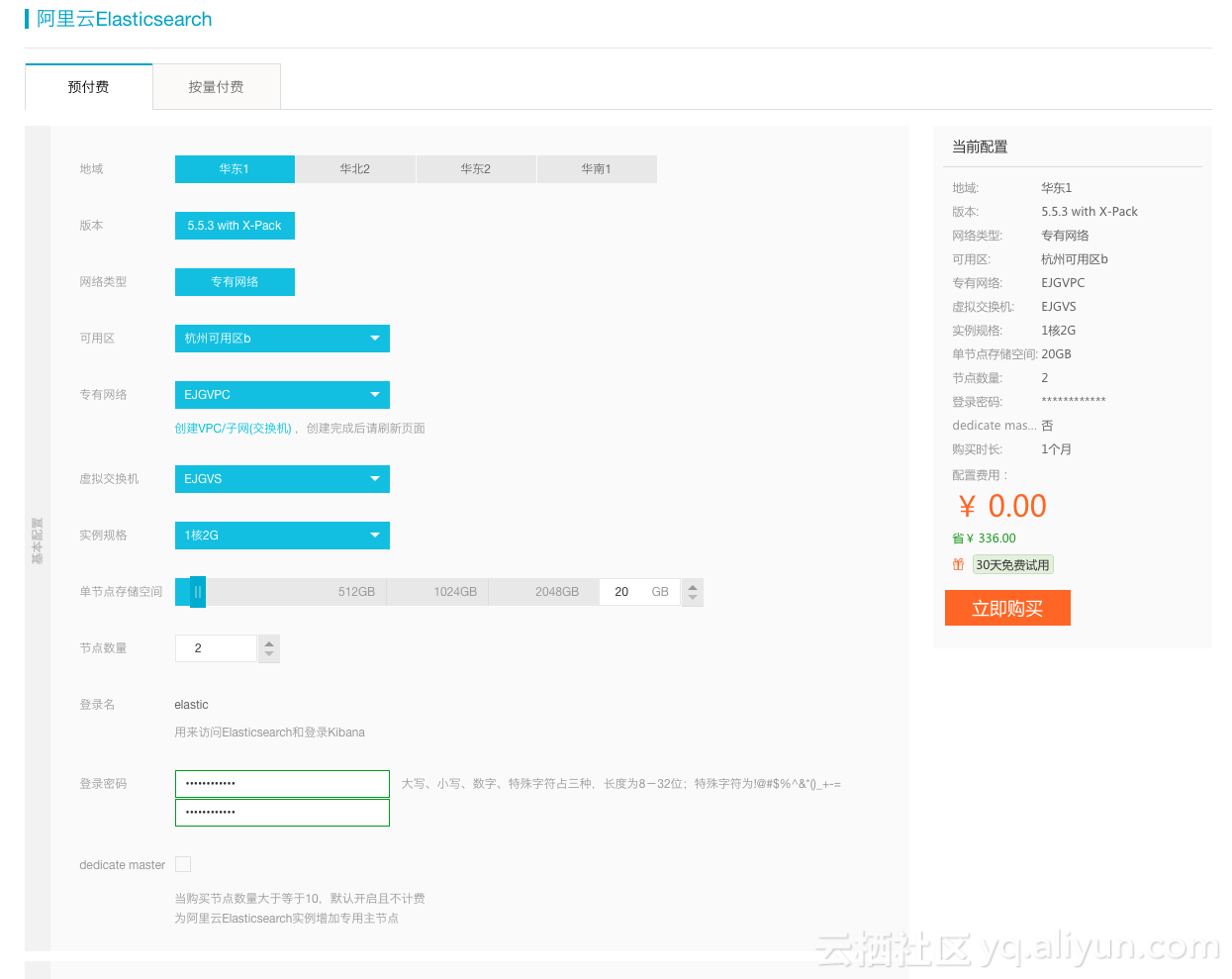
 购买页面的登录账号默认为“elastic”,密码可自行设置,与登录Kibana的账号密码是一致的。
购买页面的登录账号默认为“elastic”,密码可自行设置,与登录Kibana的账号密码是一致的。

MaxCompute JOIN优化小结
Join是MaxCompute中最基本的语法,但由于数据量和倾斜问题,非常容易出现性能问题。一般情况下,join产生的问题有两大类: 数据倾斜问题:join会将key相同的数据分发到同一个instance上处理,如果某个key上的数据量特别多则会导致该instance处理时间比其他instance处理时间长,这就是我们常说的数据倾斜,这也是join计算性能问题的罪魁祸首; 数据量问题:关联的两表基本没有热点问题,但两个表数据量都非常大同样会影响性能,比如记录数达几十亿条,如商品表、库存表等; 虽然MaxCompute中提供了一些通用的优化算法,但从业务角度解决性能问题往往更精确,更有效。对于MaxComputesql优化,在云栖社区上已经有比较多的经验积累,本文主要对join产生的性能问题以及解法做些总结。 不同数据类型k