1:KafKa的官方网址:http://kafka.apache.org/
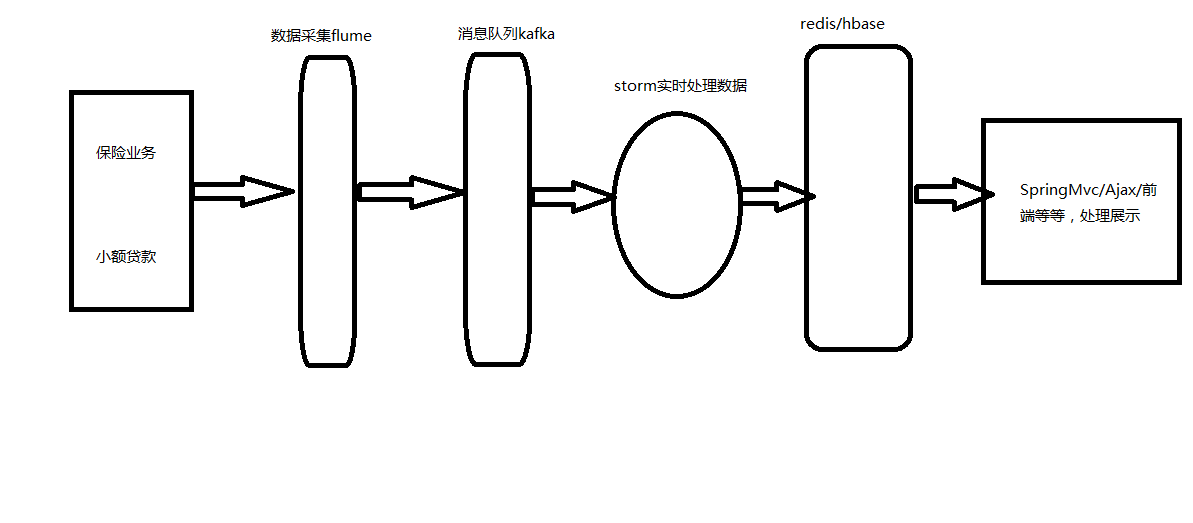
开发流程图,如:
![]()
2:KafKa的基础知识:
2.1:kafka是一个分布式的消息缓存系统
2.2:kafka集群中的服务器都叫做broker
2.3:kafka有两类客户端,一类叫producer(消息生产者),一类叫做consumer(消息消费者),客户端和broker服务器之间采用tcp协议连接
2.4:kafka中不同业务系统的消息可以通过topic进行区分,而且每一个消息topic都会被分区,以分担消息读写的负载
2.5:每一个分区都可以有多个副本,以防止数据的丢失
2.6:某一个分区中的数据如果需要更新,都必须通过该分区所有副本中的leader来更新
2.7:消费者可以分组,比如有两个消费者组A和B,共同消费一个topic:order_info,A和B所消费的消息不会重复
比如 order_info 中有100个消息,每个消息有一个id,编号从0-99,那么,如果A组消费0-49号,B组就消费50-99号
2.8:消费者在具体消费某个topic中的消息时,可以指定起始偏移量
3:KafKa集群的安装搭建,注意区分单节点KafKa集群的搭建。
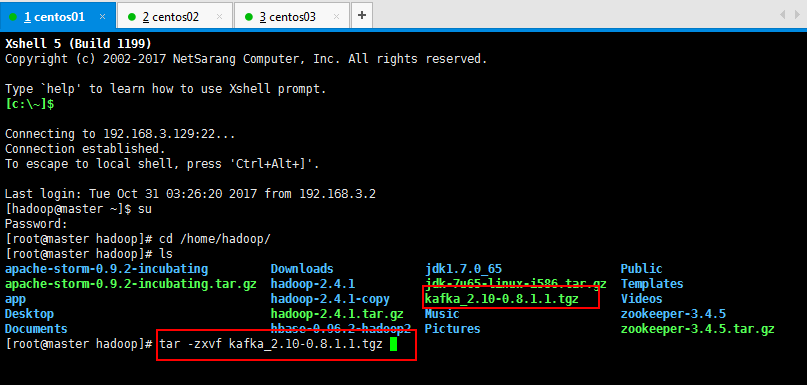
3.1:kafka集群安装,第一步上传kafka_2.10-0.8.1.1.tgz到虚拟机上面,过程省略,然后进行解压缩操作:
![]()
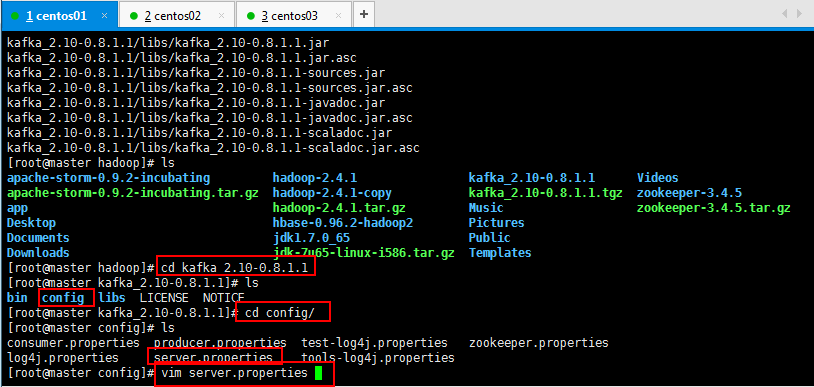
3.2:修改kafka配置文件,修改server.properties
![]()
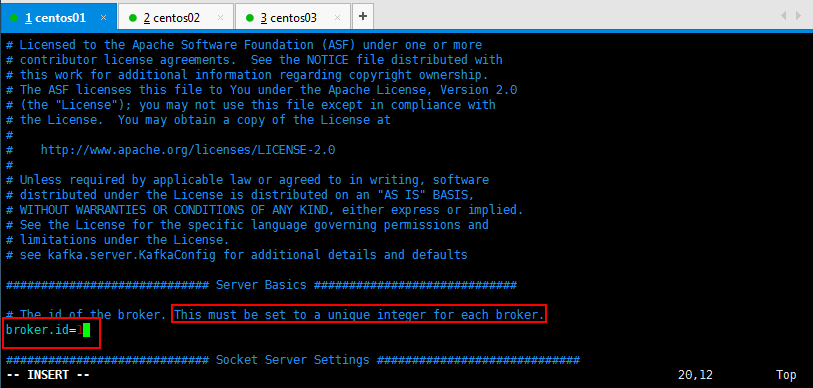
修改如下所示,具体情况可以根据手册修改,详细修改可以参考Kafka的文档:
![]()
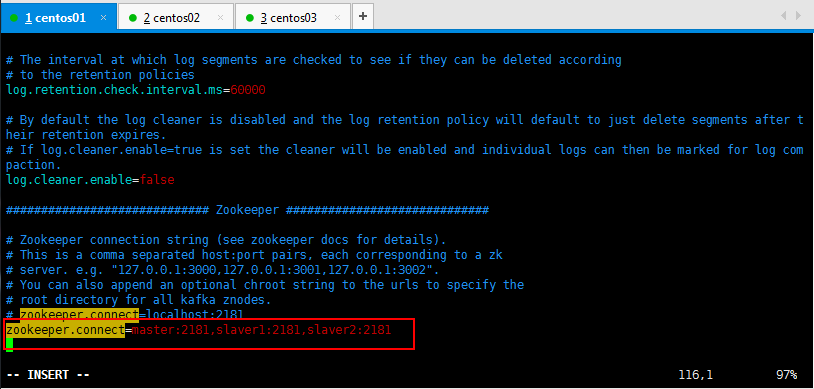
使用自己部署的Zookeeper集群,修改如下所示:
可以直接搜索:/zookeeper.connect找到所要修改的内容:
![]()
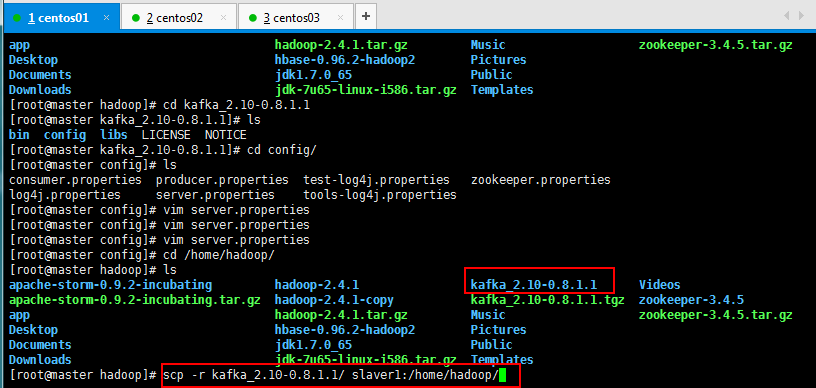
将配置好的Kafka复制到另外两个节点上面:
[root@master hadoop]# scp -r kafka_2.10-0.8.1.1/ slaver1:/home/hadoop/
[root@master hadoop]# scp -r kafka_2.10-0.8.1.1/ slaver2:/home/hadoop/
![]()
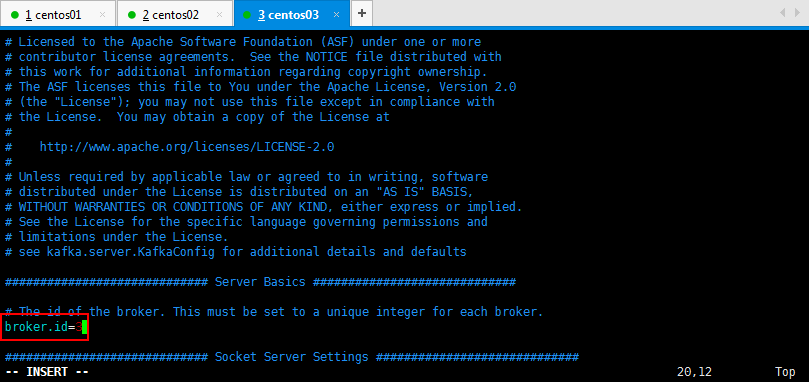
然后修改一下另外两台的broker.id=2和broker.id=3:
![]()
![]()
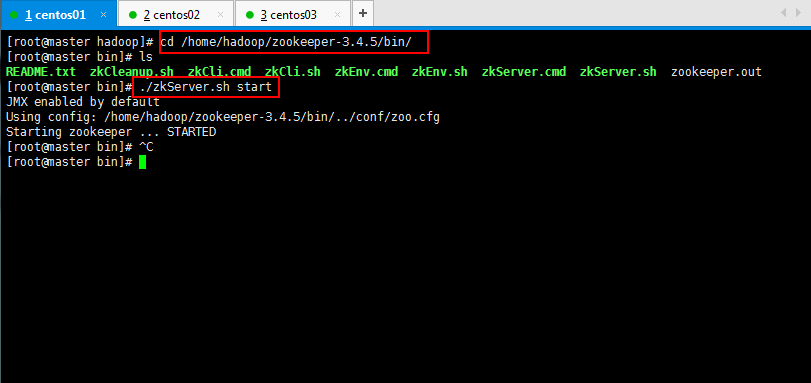
3.3:将zookeeper集群启动:
[root@master hadoop]# cd /home/hadoop/zookeeper-3.4.5/bin/
[root@master bin]# ./zkServer.sh start
[root@slaver2 bin]# ./zkServer.sh status
![]()
3.4:在每一台节点上启动broker:
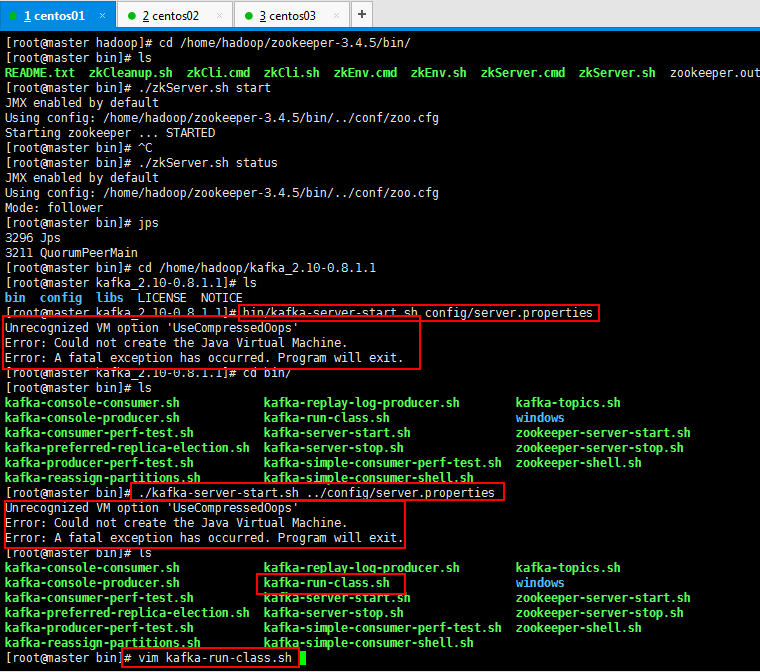
bin/kafka-server-start.sh config/server.properties
Unrecognized VM option 'UseCompressedOops'
Error: Could not create the Java Virtual Machine.
Error: A fatal exception has occurred. Program will exit.
启动的时候报错了,问题的根本是UseCompressedOops是jdk8的,而我的jdk是7,所以解决一下问题:
原因是jdk的版本不匹配,需要修改一下配置文件
修改文件:
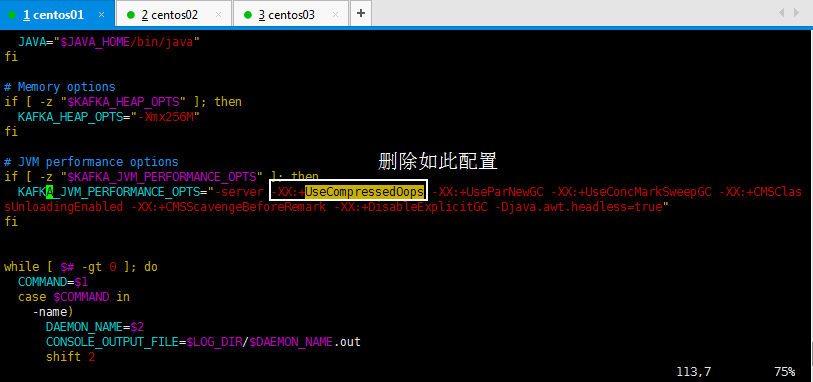
去掉这个配置
-XX:+UseCompressedOops
![]()
进去以后,搜索一下比较快:/UseCompressedOops,然后看到如下,删除如此配置:
[root@master bin]# vim kafka-run-class.sh
其他两个节点的都按照如此删除掉即可:
![]()
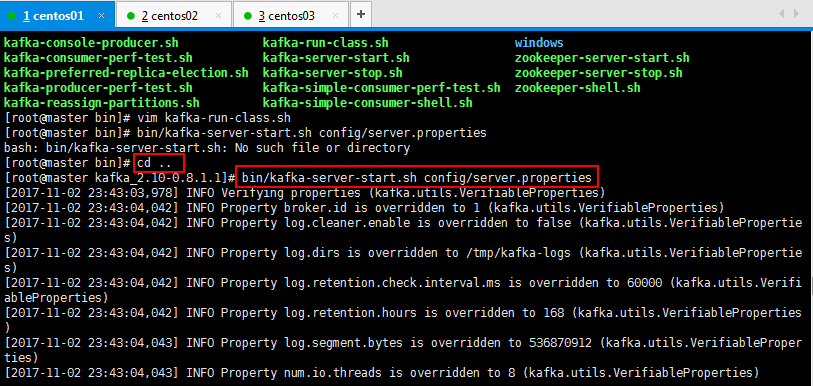
修改好以后开始跑:
在每一台节点上启动broker
bin/kafka-server-start.sh config/server.properties
![]()
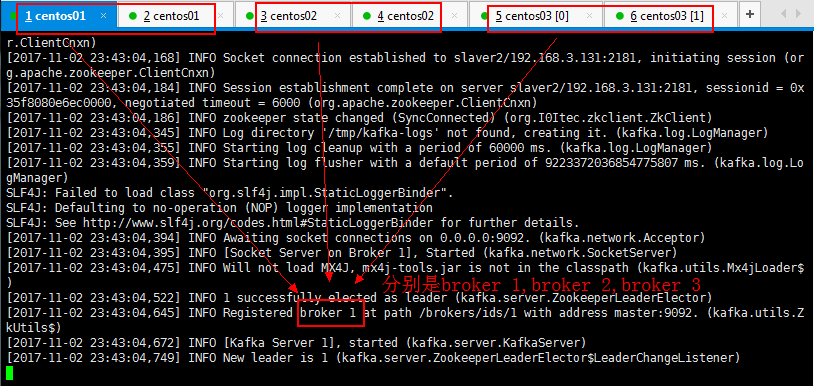
然后按照如此将其他两个节点都启动起来,然后复制xshell的连接看一下jps进程启动情况:
三个都启动起来,可以看一下,broker 1,broker 2,broker 3都启动起来了:
![]()
可以使用复制的xshell窗口查看jps进程启动情况:
![]()
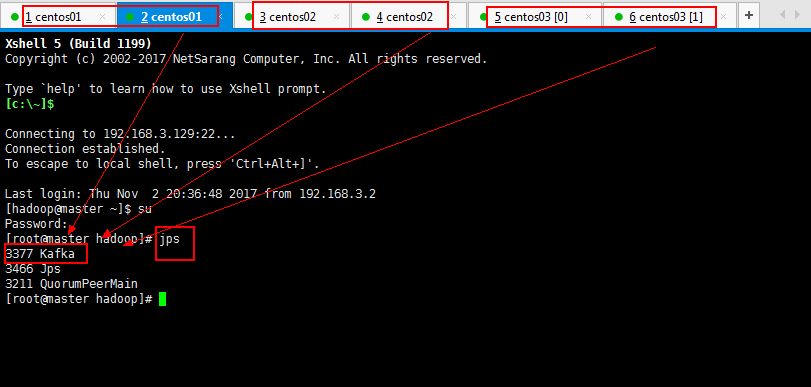
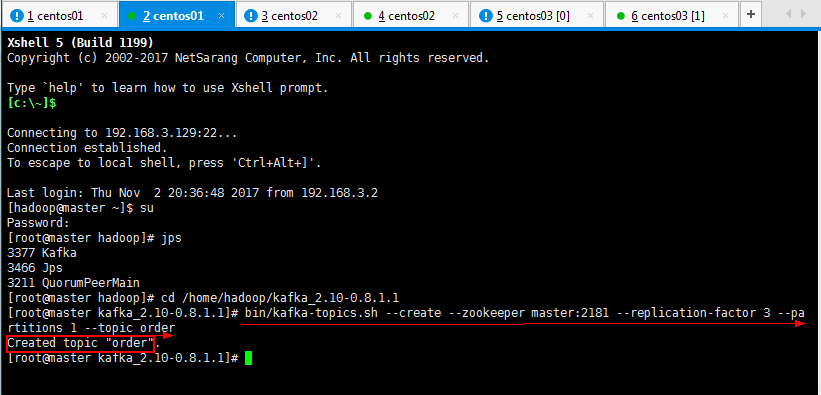
3.5:在kafka集群中创建一个topic:
[root@master kafka_2.10-0.8.1.1]# bin/kafka-topics.sh --create --zookeeper master:2181 --replication-factor 3 --partitions 1 --topic order
![]()
可以查看一下自己创建的topic:
[root@master kafka_2.10-0.8.1.1]# bin/kafka-topics.sh --list --zookeeper master:2181
可以创建多个多个topic,也可以查看一下自己创建的topic:
![]()
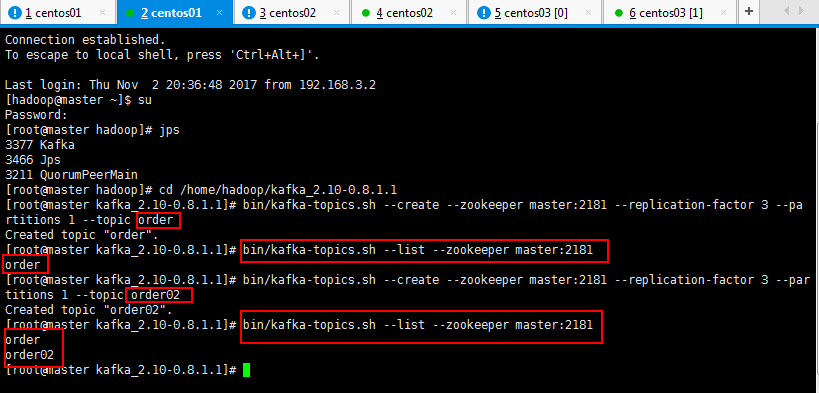
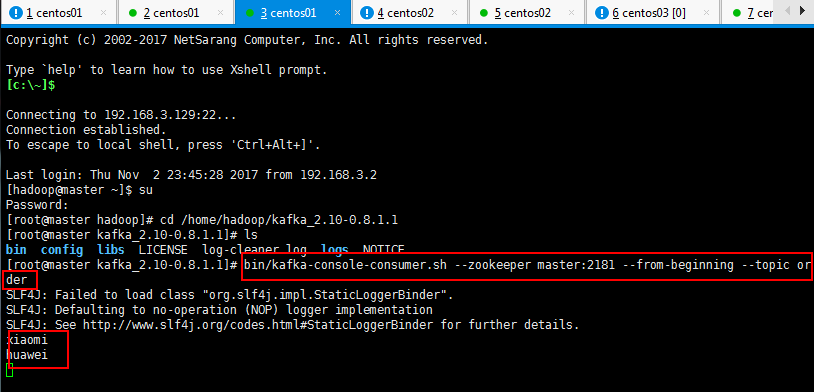
3.6:用一个producer向某一个topic中写入消息,生产者产生消息,消费者消费消息,如下生产者可以生产:
如下先启动一下生产者,先不生产消息,然后一个消费者,看看是否有输出,然后再生产消息,再去消费者看看消费消息:
#生产者
[root@master kafka_2.10-0.8.1.1]# bin/kafka-console-producer.sh --broker-list master:9092 --topic order
#消费者
[root@master kafka_2.10-0.8.1.1]# bin/kafka-console-consumer.sh --zookeeper master:2181 --from-beginning --topic order
![]()
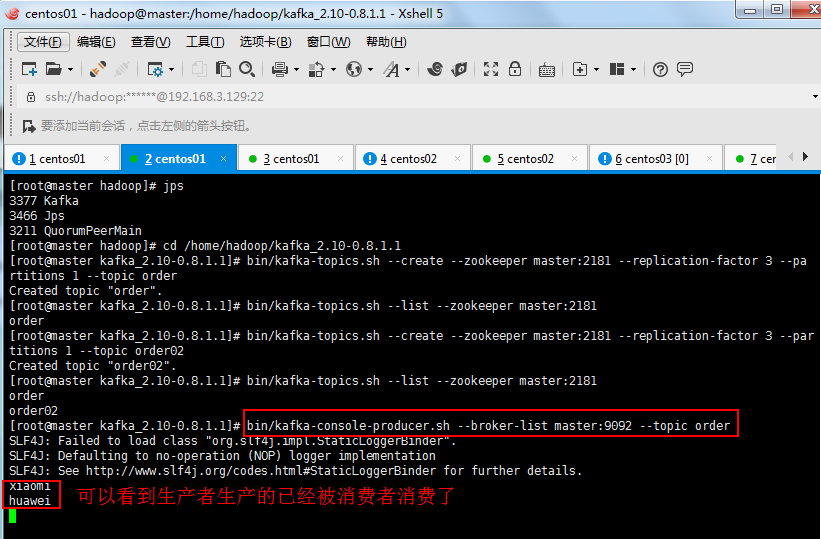
上面是生产者:
下面是消费者:
![]()
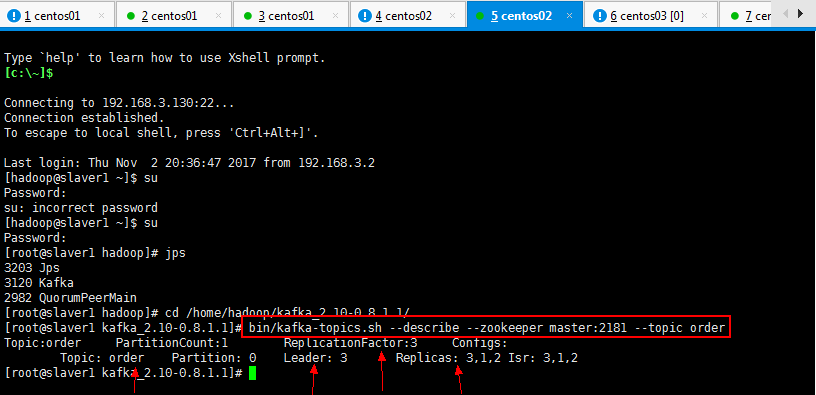
3.7:查看一个topic的分区及副本状态信息:
自己可以找任意一个xshell复制连接进程查看:
[root@slaver1 kafka_2.10-0.8.1.1]# bin/kafka-topics.sh --describe --zookeeper master:2181 --topic order
![]()
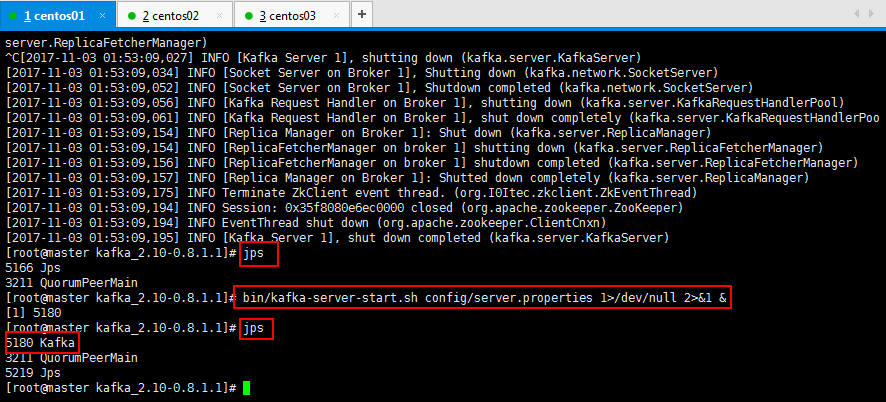
4:kafka运行在后台如何操作,如下所示:
1>/dev/null:代表标准输入到这个目录;
2>&1:代表标准输出也到这个目录下面;
&:代表这个是后台运行;
[root@master kafka_2.10-0.8.1.1]# bin/kafka-server-start.sh config/server.properties 1>/dev/null 2>&1 &
![]()