本文讲的是初体验SQL Server 2012的Hadoop连接器,电影《天下无贼》中一句经典的“21世纪什么最贵?人才!”,体现了以人为本的价值观。而实际上,深处大数据时代的我们,是不是也应该幽默一回:“21世纪什么最值钱?数据!”。对于企业而言,除了人才,数据也是最重要资产之一。
“大”数据的价值
面对如此庞大的数据,企业该如何挖掘其中的商机呢?这里给出一些应用场景,简单梳理一下大数据的价值所在:
·在以用户为中心的SNS网络中,通过大数据的分析,可以感知客户的情绪(正面,负面)变化,从而分析预测用户对公司产品的评价,以及更加关注哪些产品等等。
·在工业设备制造中,传感器数据有利于监控设备运营,指定检修时间表等。
·GPS时空数据有有利于预测用户的位置,未来的消费欲望等。
·RFID数据有利于物流系统及时跟踪库存量。
Hadoop的“大”数据优势
实际上,在数据时代,人们面临更多的是离散的结构化数据,与之有关的是关系数据库的大量运用,例如微软的SQL Server。而在大数据时代,除了关系数据之外,人们还面临着大量的非结构数据,而这正是Hadoop的价值所在。作为一个分布式系统基础架构,Hadoop支持对大量数据进行分布式处理。对于开发者而言,Hadoop的威力在于:用户无需了解分布式底层细节,即可使用Hadoop开发分布式程序,充分利用集群的高性能计算和存储资源。现如今,作为Apache基金会的开源项目,Hadoop无疑是大数据领域的佼佼者。
什么是SQL Server 2012的Hadoop连接器
作为计算时代的引领者,微软深知,云计算离不开大数据,而SQL Server 2012正是微软云计算数据服务战略的重要步骤,它融合了Hadoop 连接器技术,让SQL Server 也跨入了非结构化大数据领域。
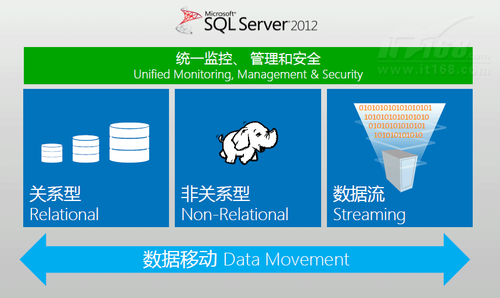
图1显示的SQL Server 2012的体系结构。不难看出,SQL Server 2012是一个支持结构化、非结构化和实时数据的完整数据平台。有了Hadoop的加盟,SQL Server 2012可以轻而易举地支持企业级Hadoop分布式非结构化数据。
![初体验SQL Server 2012的Hadoop连接器]()
▲图 1. SQL Server 大数据框架
具体来说,Hadoop连接器提供了Hadoop非结构数据与SQL Server结构化数据之间的双向迁移能力。而Hive ODBC驱动程序则支持Hive和Microsoft BI 工具(如PowerPivot和Power View)的直接连接,另外,Microsoft Excel与Hadoop的数据交互也可通过Hive附加程序实现。
除了Hadoop连接器,另一个连接器SQL Server Parallel Data Warehouse (PDW) connector for Hadoop,也提供Hadoop与SQL Server PDW数据之间的双向迁移。
使用Hadoop连接的最大价值在于:云计算客户可以自由地在结构化数据与非结构化数据之间来回穿梭。
体验SQL Server 2012的Hadoop连接器
前面提到,Hadoop是一个Apache基金会支持的开源分布式大数据处理框架,能并行处理不同节点的大数据。而作为Hadoop的文件系统,HDFS为用户应用提供了文件级存储支持。
SQL Server支持的Hadoop连接器的基础是Sqoop连接器,主要目标是提供SQL Server与Hadoop之间的数据转换,即结构化数据与非结构化数据之间的双向数据迁移。
下面,结合SQL Server 2012与Hadoop的双向数据转换,我们简单演示以下SQL Server Hadoop连接器的功能。
1. 将SQL Server 2012数据导入到Hadoop
Hadoop存储数据的介质包括文件系统HDFS与数据库Hive两部分。因此,SQL Server 2012导入到Hadoop也分为两部分。
清单1演示的是将SQL Server 2012中名叫testdb的数据库中的testtable表导入到Hadoop的文件系统HDFS中。
清单1
$bin
/
sqoop import
--
connect
'
jdbc:sqlserver://192.168.0.1;username=dbuser;password=dbpasswd;database=testdb' --table testtable --target-dir /data/testData
前面提到,SQL Server Hadoop连接器基于Sqoop,因此,这里的命令为sqoop,对应的导入参数为import –connect。作为源数据库,jdbc:sqlserver 的URL指定了SQL Server 2012对应的主机名192.168.0.1,数据库用户名dbuser与密码dbpasswd。与此同时,还指定了数据库名称testdb以及对应的数据表testtable。而作为目标Hadoop,这里指定了HDFS的目录——/data/testData。
为了加速导入,我们可以采用并行的方式,如清单2所示:
清单2
$bin
/
sqoop import
--
connect
'
jdbc:sqlserver://192.168.0.1;username=dbuser;password=dbpasswd;database=testdb' --table testtable --target-dir /data/testData --split-by id -m 4
清单2是在清单1的基础上,选择-m选项来启动4个进程,同时进行数据的导入操作。--split选项则指定基于数据表中的哪一列进行拆分。我们简单解释下其中的并行工作原理。
a)首先,SQL Server连接器会执行一个查询
select
max(id)
as
max,
select
min(id)
as
min from test
通过查询,获取到需要拆分字段(id)的最大值和最小值,假设分别是1和1000。
b) 然后,Sqoop会根据需要并行导入的数量,进行拆分查询,并行导入将拆分为如下4条SQL同时执行:
select
*
from test where
0
<=
id
<
250
;
select
*
from test where
250
<=
id
<
500
;
select
*
from test where
500
<=
id
<
750
;
select
*
from test where
750
<=
id
<
1000
;
这样,就达到了并行导入的目的。
除了默认的文本文件,HDFS还支持二进制文件,也称为序列化文件sequencefile。清单3是在清单1的基础上,使用--as-sequencefile选项,指定导出文件格式为二进制文件,而非清单1所示的文本文件。
清单3
$bin
/
sqoop import
--
connect
'
jdbc:sqlserver://192.168.0.1;username=dbuser;password=dbpasswd;database=testdb' --table testtable --target-dir /data/testData --as-sequencefile
以上3个例子都是描述SQL Server 数据库与HDFS文件的转换。清单4则是描述SQL Server数据库与Hive数据库的转换,即结构化数据库向非结构化数据库的数据导入。
清单4
$bin
/
sqoop import
--
connect
'
jdbc:sqlserver://192.168.0.1;username=dbuser;password=dbpasswd;database=testdb' --table testtable --target-dir /data/testData –hive-import
注意,在执行该命令之前,请确保环境变量HIVE_HOME(即Hive的安装目录)被正确设置。
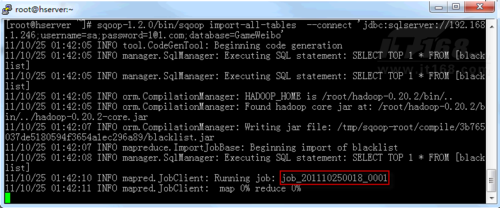
图2显示的是将SQL Server数据库GameWeibo的数据表blacklist导入到Hadoop当中,后台启动MapReduce作业执行导入操作。
![体验SQL Server 2012的Hadoop连接器]()
可以通过Hadoop提供的Web视图,查看MapReduce导入作业的ID、名称、作业状态等信息,如图3所示。
![体验SQL Server 2012的Hadoop连接器]()
现在,可以查看Hadoop的HDFS文件中的数据,如图4所示。
![体验SQL Server 2012的Hadoop连接器]()
2. 将Hadoop数据导出到SQL Server 2012
很显然,这一部分的内容与前一部分的内容正好相对,因此,对应的导出命令为export。
清单5显示的将Hadoop的文件系统HDFS中的/data/testData目录的数据导出到SQL Server 2012中名叫testdb的数据库中的testtable表中。与清单1相比,除了参数从import改成export,--target-dir也变成了--export-dir。
清单5
$bin
/
sqoop export
--
connect
'
jdbc:sqlserver://192.168.0.1;username=dbuser;password=dbpasswd;database=testdb' --table testable --export-dir /data/testData
清单6是清单2的逆过程,这里不做过多解释。
清单6
$bin
/
sqoop export
--
connect
'
jdbc:sqlserver://192.168.0.1;username=dbuser;password=dbpasswd;database=testdb' --table testable --export-dir /data/testData –m 4
对于其它Export命令操作,读者可使用Import命令的逆向思维来思考,这里不再举例赘述。
为了方便读者理解,以下给出的是SQL Server Hadoop连接器最常用13命令的解释说明。
| 序号 |
命令 |
描述说明 |
| 1 |
impor |
从关系型数据库中导入数据(来自表或者查询语句)到HDFS中 |
| 2 |
export |
将HDFS中的数据导入到关系型数据库中 |
| 3 |
codegen |
获取数据库中某张表数据生成Java并打成jar包 |
| 4 |
create-hive-table |
创建Hive表 |
| 5 |
eval |
查看SQL执行结果 |
| 6 |
import-all-tables |
导入某个数据库下所有表到HDFS中 |
| 7 |
job |
列出所有数据库名 |
| 8 |
list-databases |
列出某个数据库下所有表 |
| 9 |
list-tables |
查看帮助 |
| 10 |
merge |
查看版本 |
| 11 |
metastore |
从关系型数据库中导入数据(来自表或者查询语句)到HDFS中 |
| 12 |
help |
将HDFS中的数据导入到关系型数据库中 |
| 13 |
version |
获取数据库中某张表数据生成Java并打成jar包 |
小结
总之,有了Hadoop连接器的支持,SQL Server 2012是一个可支持结构化、非结构化和实时的数据的完整数据库平台,用户实现了结构化数据与非结构化数据的双向迁移。
作者: 李培帅
来源: IT168
原文标题:初体验SQL Server 2012的Hadoop连接器