
一张图了解云栖大会·上海峰会降价产品
2018云栖大会·上海峰会上,阿里云宣布开启新一轮核心产品降价,最高降幅达50%,涉及产品包括弹性计算ECS、对象存储OSS、表格存储、性能测试PTS等,其中对象存储OSS统一降至0.12元/GB/月,刷新了全网最低价。 更多产品信息请戳:https://yunqi.aliyun.com/2018/shanghai/product?spm=5176.8142029.759399.2.a7236d3e2qNVQU
正如Hadoop在介绍MapReduce编程模型时选择word count的例子,并且使用图形来说明一样,笔者对于Spark编程模型也选择用图形展现。
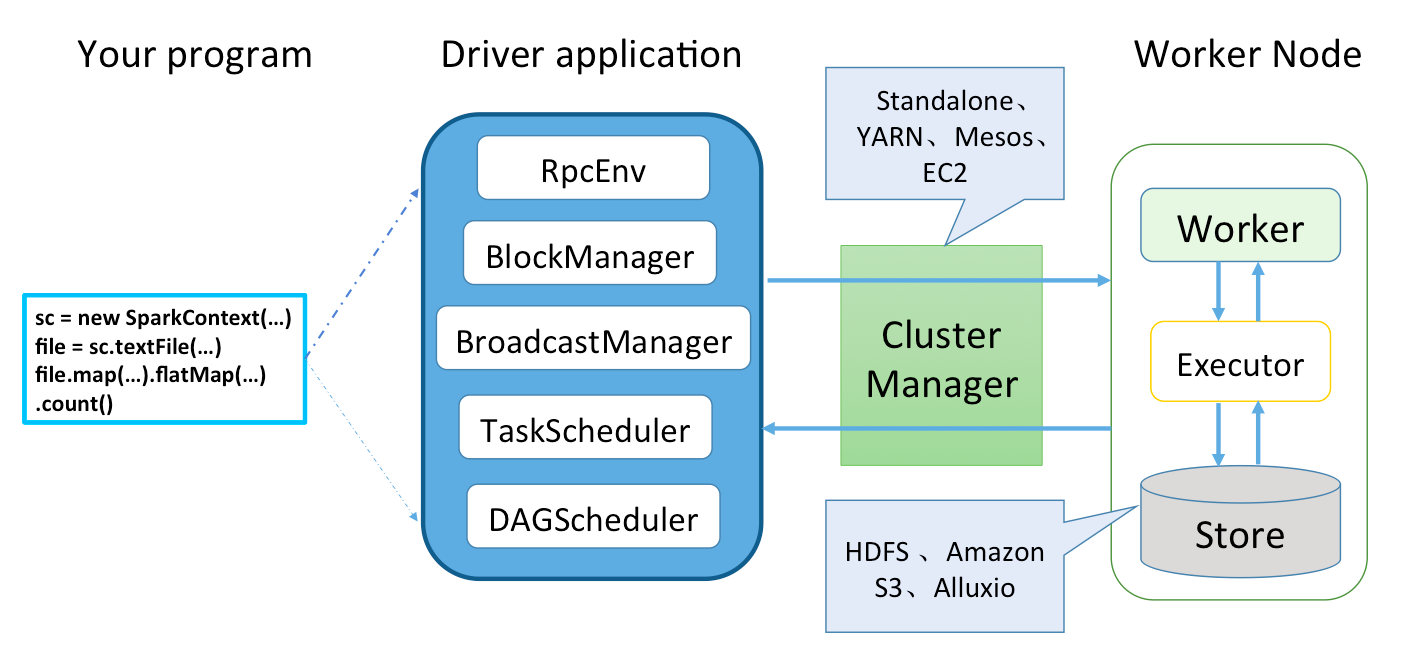
Spark 应用程序从编写到提交、执行、输出的整个过程如图2-5所示。
图2-5 代码执行过程
图2-5中描述了Spark编程模型的关键环节的步骤如下:
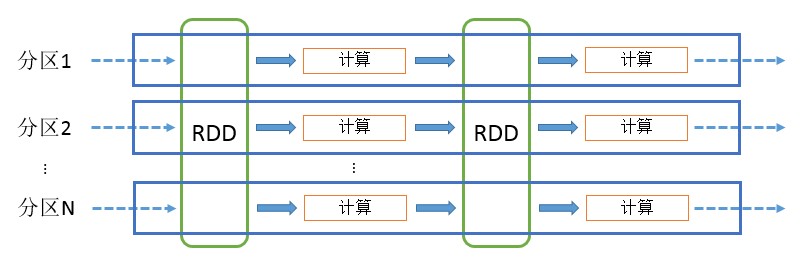
RDD可以看做是对各种数据计算模型的统一抽象,Spark的计算过程主要是RDD的迭代计算过程,如图2-6所示。RDD的迭代计算过程非常类似于管道。分区数量取决于Partition数量的设定,每个分区的数据只会在一个Task中计算。所有分区可以在多个机器节点的Executor上并行执行。
图2-6 RDD计算模型
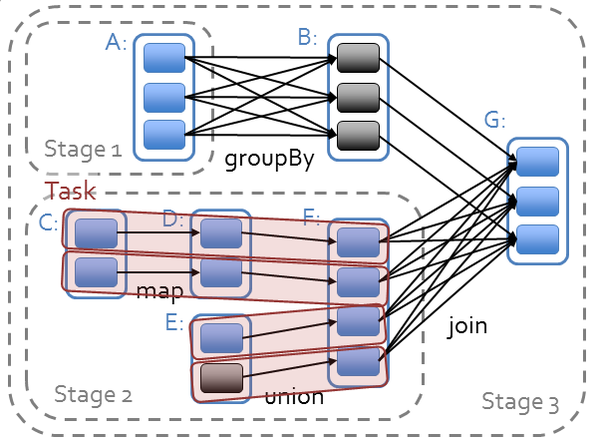
图2-6只是简单的从分区的角度将RDD的计算看作是管道,如果从RDD的血缘关系、Stage划分的角度来看,由RDD构成的DAG经过DAGScheduler调度后,将变成图2-7所示的样子。
图2-7 DAGScheduler对由RDD构成的DAG进行调度
图2-7中共展示了A、B、C、D、E、F、G一共七个RDD。每个RDD中的小方块代表一个分区,将会有一个Task处理此分区的数据。RDD A经过groupByKey转换后得到RDD B。RDD C经过map转换后得到RDD D。RDD D和RDD E经过union转换后得到RDD F。RDD B和RDD F经过join转换后得到RDD G。从图中可以看到map和union生成的RDD与其上游RDD之间的依赖是NarrowDependency,而groupByKey和join生成的RDD与其上游的RDD之间的依赖是ShuffleDependency。由于DAGScheduler按照ShuffleDependency作为Stage的划分的依据,因此A被划入了ShuffleMapStage 1;C、D、E、F被划入了ShuffleMapStage 2;B和G被划入了ResultStage 3。
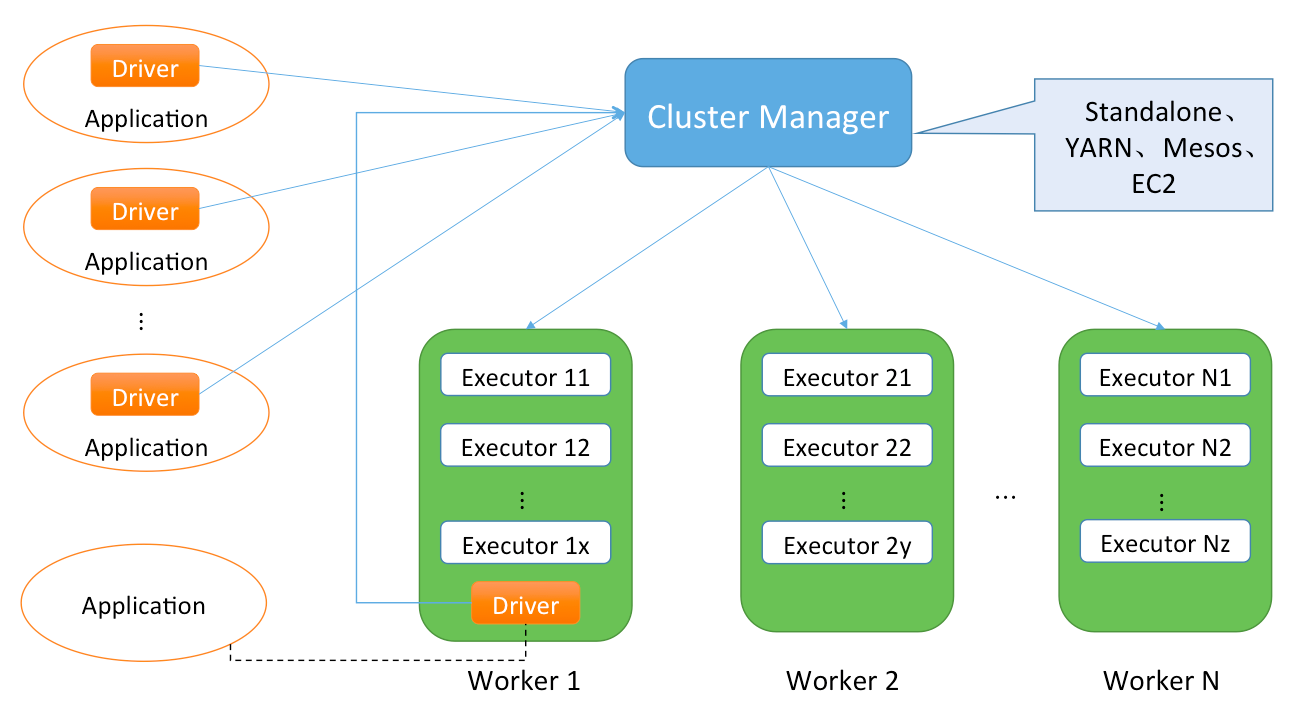
从集群部署的角度来看,Spark集群由以下部分组成:
这些组成部分之间的整体关系如图2-8所示。
图2-8 Spark基本架构图
每项技术的诞生都会由某种社会需求所驱动,Spark正是在实时计算的大量需求下诞生的。Spark借助其优秀的处理能力,可用性高,丰富的数据源支持等特点,在当前大数据领域变得火热,参与的开发者也越来越多。Spark经过几年的迭代发展,如今已经提供了丰富的功能。笔者相信,Spark在未来必将产生更耀眼的火花。

微信关注我们
转载内容版权归作者及来源网站所有!
低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
为解决软件依赖安装时官方源访问速度慢的问题,腾讯云为一些软件搭建了缓存服务。您可以通过使用腾讯云软件源站来提升依赖包的安装速度。为了方便用户自由搭建服务架构,目前腾讯云软件源站支持公网访问和内网访问。
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service 的首字母简称,一个易于构建 AI Agent 应用的动态服务发现、配置管理和AI智能体管理平台。Nacos 致力于帮助您发现、配置和管理微服务及AI智能体应用。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据、流量管理。Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。
Spring框架(Spring Framework)是由Rod Johnson于2002年提出的开源Java企业级应用框架,旨在通过使用JavaBean替代传统EJB实现方式降低企业级编程开发的复杂性。该框架基于简单性、可测试性和松耦合性设计理念,提供核心容器、应用上下文、数据访问集成等模块,支持整合Hibernate、Struts等第三方框架,其适用范围不仅限于服务器端开发,绝大多数Java应用均可从中受益。
WebStorm 是jetbrains公司旗下一款JavaScript 开发工具。目前已经被广大中国JS开发者誉为“Web前端开发神器”、“最强大的HTML5编辑器”、“最智能的JavaScript IDE”等。与IntelliJ IDEA同源,继承了IntelliJ IDEA强大的JS部分的功能。
扫码在手机上查看文章
扫描二维码,手机阅读更方便
有任何问题或合作意向欢迎联系我们
Email: 99873273@qq.com
QQ: 99873273