Node.js 的出现,让 JavaScript 脱离了浏览器的束缚,进入了广阔的服务端开发领域。而 Node.js 对 CommonJS 模块化规范的引入,则更是让 JavaScript成为了一门真正能够适应大型工程的语言。
在 Node.js 中使用模块非常简单,我们日常开发中几乎都有过这样的经历:写一段 JavaScript 代码,require 一些想要的包,然后将代码产物 exports 导出。但是,对于 Node.js 模块化背后的加载与运行原理,我们是否清楚呢。首先抛出以下几个问题:
- Node.js 中的模块支持哪些文件类型?
- 核心模块和第三方模块的加载运行流程有什么不同?
- 除了 JavaScript 模块以外,怎样去写一个 C/C++ 扩展模块?
- ……
本篇文章,就会结合 Node.js 源码,探究一下以上这些问题背后的答案。
1. Node.js 模块类型
在 Node.js 中,模块主要可以分为以下几种类型:
- 核心模块:包含在 Node.js 源码中,被编译进 Node.js 可执行二进制文件 JavaScript 模块,也叫 native 模块,比如常用的 http, fs 等等
- C/C++ 模块,也叫 built-in 模块,一般我们不直接调用,而是在 native module 中调用,然后我们再 require
- native 模块,比如我们在 Node.js 中常用的 buffer,fs,os 等 native 模块,其底层都有调用 built-in 模块。
- 第三方模块:非 Node.js 源码自带的模块都可以统称第三方模块,比如 express,webpack 等等。
- JavaScript 模块,这是最常见的,我们开发的时候一般都写的是 JavaScript 模块
- JSON 模块,这个很简单,就是一个 JSON 文件
- C/C++ 扩展模块,使用 C/C++ 编写,编译之后后缀名为 .node
本篇文章中,我们会一一涉及到上述几种模块的加载、运行原理。
2. Node.js 源码结构一览
这里使用 Node.js 6.x 版本源码为例子来做分析。去 github 上下载相应版本的 Node.js 源码,可以看到代码大体结构如下:
├── AUTHORS
├── BSDmakefile
├── BUILDING.md
├── CHANGELOG.md
├── CODE_OF_CONDUCT.md
├── COLLABORATOR_GUIDE.md
├── CONTRIBUTING.md
├── GOVERNANCE.md
├── LICENSE
├── Makefile
├── README.md
├── android-configure
├── benchmark
├── common.gypi
├── configure
├── deps
├── doc
├── lib
├── node.gyp
├── node.gypi
├── src
├── test
├── tools
└── vcbuild.bat
其中:
- ./lib文件夹主要包含了各种 JavaScript 文件,我们常用的 JavaScript native 模块都在这里。
- ./src文件夹主要包含了 Node.js 的 C/C++ 源码文件,其中很多 built-in 模块都在这里。
- ./deps文件夹包含了 Node.js 依赖的各种库,典型的如 v8,libuv,zlib 等。
我们在开发中使用的 release 版本,其实就是从源码编译得到的可执行文件。如果我们想要对 Node.js 进行一些个性化的定制,则可以对源码进行修改,然后再运行编译,得到定制化的 Node.js 版本。这里以 Linux 平台为例,简要介绍一下 Node.js 编译流程。
首先,我们需要认识一下编译用到的组织工具,即 gyp。Node.js 源码中我们可以看到一个 node.gyp,这个文件中的内容是由 python 写成的一些 JSON-like 配置,定义了一连串的构建工程任务。我们举个例子,其中有一个字段如下:
{
'target_name': 'node_js2c',
'type': 'none',
'toolsets': ['host'],
'actions': [
{
'action_name': 'node_js2c',
'inputs': [
'<@(library_files)',
'./config.gypi',
],
'outputs': [
'<(SHARED_INTERMEDIATE_DIR)/node_natives.h',
],
'conditions': [
[ 'node_use_dtrace=="false" and node_use_etw=="false"', {
'inputs': [ 'src/notrace_macros.py' ]
}],
['node_use_lttng=="false"', {
'inputs': [ 'src/nolttng_macros.py' ]
}],
[ 'node_use_perfctr=="false"', {
'inputs': [ 'src/perfctr_macros.py' ]
}]
],
'action': [
'python',
'tools/js2c.py',
'<@(_outputs)',
'<@(_inputs)',
],
},
],
}, # end node_js2c
这个任务主要的作用从名称 node_js2c 就可以看出来,是将 JavaScript 转换为 C/C++ 代码。这个任务我们下面还会提到。
首先编译 Node.js,需要提前安装一些工具:
- gcc 和 g++ 4.9.4 及以上版本
- clang 和 clang++
- python 2.6 或者 2.7,这里要注意,只能是这两个版本,不可以为python 3+
- GNU MAKE 3.81 及以上版本
有了这些工具,进入 Node.js 源码目录,我们只需要依次运行如下命令:
./configuration
make
make install
即可编译生成可执行文件并安装了。
3. 从 node index.js 开始
让我们首先从最简单的情况开始。假设有一个 index.js 文件,里面只有一行很简单的 console.log('hello world') 代码。当输入 node index.js 的时候,Node.js 是如何编译、运行这个文件的呢?
当输入 Node.js 命令的时候,调用的是 Node.js 源码当中的 main 函数,在 src/node_main.cc 中:
// src/node_main.cc
#include "node.h"
#ifdef _WIN32
#include <VersionHelpers.h>
int wmain(int argc, wchar_t *wargv[]) {
// windows下面的入口
}
#else
// UNIX
int main(int argc, char *argv[]) {
// Disable stdio buffering, it interacts poorly with printf()
// calls elsewhere in the program (e.g., any logging from V8.)
setvbuf(stdout, nullptr, _IONBF, 0);
setvbuf(stderr, nullptr, _IONBF, 0);
// 关注下面这一行
return node::Start(argc, argv);
}
#endif
这个文件只做入口用,区分了 Windows 和 Unix 环境。我们以 Unix 为例,在 main 函数中最后调用了 node::Start,这个是在 src/node.cc 文件中:
// src/node.cc
int Start(int argc, char** argv) {
// ...
{
NodeInstanceData instance_data(NodeInstanceType::MAIN,
uv_default_loop(),
argc,
const_cast<const char**>(argv),
exec_argc,
exec_argv,
use_debug_agent);
StartNodeInstance(&instance_data);
exit_code = instance_data.exit_code();
}
// ...
}
// ...
static void StartNodeInstance(void* arg) {
// ...
{
Environment::AsyncCallbackScope callback_scope(env);
LoadEnvironment(env);
}
// ...
}
// ...
void LoadEnvironment(Environment* env) {
// ...
Local<String> script_name = FIXED_ONE_BYTE_STRING(env->isolate(),
"bootstrap_node.js");
Local<Value> f_value = ExecuteString(env, MainSource(env), script_name);
if (try_catch.HasCaught()) {
ReportException(env, try_catch);
exit(10);
}
// The bootstrap_node.js file returns a function 'f'
CHECK(f_value->IsFunction());
Local<Function> f = Local<Function>::Cast(f_value);
// ...
f->Call(Null(env->isolate()), 1, &arg);
}
整个文件比较长,在上面代码段里,只截取了我们最需要关注的流程片段,调用关系如下: Start -> StartNodeInstance -> LoadEnvironment。
在 LoadEnvironment 需要我们关注,主要做的事情就是,取出 bootstrap_node.js 中的代码字符串,解析成函数,并最后通过 f->Call 去执行。
OK,重点来了,从 Node.js 启动以来,我们终于看到了第一个 JavaScript 文件 bootstrap_node.js,从文件名我们也可以看出这个是一个入口性质的文件。那么我们快去看看吧,该文件路径为 lib/internal/bootstrap_node.js:
// lib/internal/boostrap_node.js
(function(process) {
function startup() {
// ...
else if (process.argv[1]) {
const path = NativeModule.require('path');
process.argv[1] = path.resolve(process.argv[1]);
const Module = NativeModule.require('module');
// ...
preloadModules();
run(Module.runMain);
}
// ...
}
// ...
startup();
}
// lib/module.js
// ...
// bootstrap main module.
Module.runMain = function() {
// Load the main module--the command line argument.
Module._load(process.argv[1], null, true);
// Handle any nextTicks added in the first tick of the program
process._tickCallback();
};
// ...
这里我们依然关注主流程,可以看到,bootstrap_node.js 中,执行了一个 startup() 函数。通过 process.argv[1] 拿到文件名,在我们的 node index.js 中,process.argv[1] 显然就是 index.js,然后调用 path.resolve 解析出文件路径。在最后,run(Module.runMain) 来编译执行我们的 index.js。
而 Module.runMain 函数定义在 lib/module.js 中,在上述代码片段的最后,列出了这个函数,可以看到,主要是调用 Module._load 来加载执行 process.argv[1]。
下文我们在分析模块的 require 的时候,也会来到 lib/module.js 中,也会分析到 Module._load。因此我们可以看出,Node.js 启动一个文件的过程,其实到最后,也是 require 一个文件的过程,可以理解为是立即 require 一个文件。下面就来分析 require 的原理。
4. 模块加载原理的关键:require
我们进一步,假设我们的 index.js 有如下内容:
var http = require('http');
那么当执行这一句代码的时候,会发生什么呢?
require的定义依然在 lib/module.js 中:
// lib/module.js
// ...
Module.prototype.require = function(path) {
assert(path, 'missing path');
assert(typeof path === 'string', 'path must be a string');
return Module._load(path, this, /* isMain */ false);
};
// ...
require 方法定义在Module的原型链上。可以看到这个方法中,调用了 Module._load。
我们这么快就又来到了 Module._load 来看看这个关键的方法究竟做了什么吧:
// lib/module.js
// ...
Module._load = function(request, parent, isMain) {
if (parent) {
debug('Module._load REQUEST %s parent: %s', request, parent.id);
}
var filename = Module._resolveFilename(request, parent, isMain);
var cachedModule = Module._cache[filename];
if (cachedModule) {
return cachedModule.exports;
}
if (NativeModule.nonInternalExists(filename)) {
debug('load native module %s', request);
return NativeModule.require(filename);
}
var module = new Module(filename, parent);
if (isMain) {
process.mainModule = module;
module.id = '.';
}
Module._cache[filename] = module;
tryModuleLoad(module, filename);
return module.exports;
};
// ...
这段代码的流程比较清晰,具体说来:
- 根据文件名,调用 Module._resolveFilename 解析文件的路径
- 查看缓存 Module._cache 中是否有该模块,如果有,直接返回
- 通过 NativeModule.nonInternalExists 判断该模块是否为核心模块,如果核心模块,调用核心模块的加载方法 NativeModule.require
- 如果不是核心模块,新创建一个 Module 对象,调用 tryModuleLoad 函数加载模块
我们首先来看一下 Module._resolveFilename,看懂这个方法对于我们理解 Node.js 的文件路径解析原理很有帮助:
// lib/module.js
// ...
Module._resolveFilename = function(request, parent, isMain) {
// ...
var filename = Module._findPath(request, paths, isMain);
if (!filename) {
var err = new Error("Cannot find module '" + request + "'");
err.code = 'MODULE_NOT_FOUND';
throw err;
}
return filename;
};
// ...
在 Module._resolveFilename 中调用了 Module._findPath,模块加载的判断逻辑实际上集中在这个方法中,由于这个方法较长,直接附上 github 该方法代码:
https://github.com/nodejs/node/blob/v6.x/lib/module.js#L158
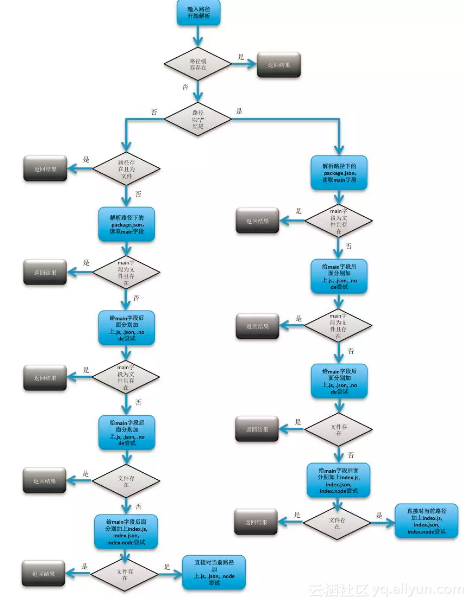
可以看出,文件路径解析的逻辑流程是这样的:
- 先生成 cacheKey,判断相应 cache 是否存在,若存在直接返回
- 如果 path 的最后一个字符不是 /:
- 如果路径是一个文件并且存在,那么直接返回文件的路径
- 如果路径是一个目录,调用 tryPackage 函数去解析目录下的 package.json,然后取出其中的 main 字段所写入的文件路径
- 判断路径如果存在,直接返回
- 尝试在路径后面加上 .js, .json, .node 三种后缀名,判断是否存在,存在则返回
- 尝试在路径后面依次加上 index.js, index.json, index.node,判断是否存在,存在则返回
- 如果还不成功,直接对当前路径加上 .js, .json, .node 后缀名进行尝试
- 如果 path 的最后一个字符是 /:
- 调用 tryPackage ,解析流程和上面的情况类似
- 如果不成功,尝试在路径后面依次加上 index.js, index.json, index.node,判断是否存在,存在则返回
解析文件中用到的 tryPackage 和 tryExtensions 方法的 github 链接:
https://github.com/nodejs/node/blob/v6.x/lib/module.js#L108 https://github.com/nodejs/node/blob/v6.x/lib/module.js#L146
整个流程可以参考下面这张图:
![9ced9f75e7085c1973b3849e7476c6b1ab9d46df]()
而在文件路径解析完成之后,根据文件路径查看缓存是否存在,存在直接返回,不存在的话,走到 3 或者 4 步骤。
这里,在 3、4 两步产生了两个分支,即核心模块和第三方模块的加载方法不一样。由于我们假设了我们的 index.js 中为 var http = require('http'),http 是一个核心模块,所以我们先来分析核心模块加载的这个分支。
4.1 核心模块加载原理
核心模块是通过 NativeModule.require 加载的,NativeModule的定义在 bootstrap_node.js 中,附上 github 链接:
https://github.com/nodejs/node/blob/v6.x/lib/internal/bootstrap_node.js#L401
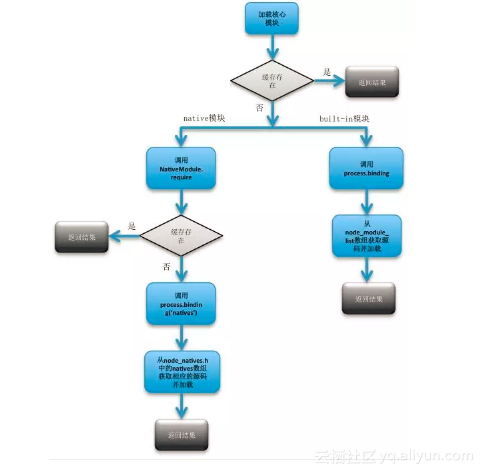
从代码中可以看到,NativeModule.require 的流程如下:
- 判断 cache 中是否已经加载过,如果有,直接返回 exports
- 新建 nativeModule 对象,然后缓存,并加载编译
首先我们来看一下如何编译,从代码中看是调用了 compile 方法,而在 NativeModule.prototype.compile 方法中,首先是通过 NativeModule.getSource 获取了要加载模块的源码,那么这个源码是如何获取的呢?看一下 getSource 方法的定义:
// lib/internal/bootstrap_node.js
// ...
NativeModule._source = process.binding('natives');
// ...
NativeModule.getSource = function(id) {
return NativeModule._source[id];
};
直接从 NativeModule._source 获取的,而这个又是在哪里赋值的呢?在上述代码中也截取了出来,是通过 NativeModule._source = process.binding('natives') 获取的。
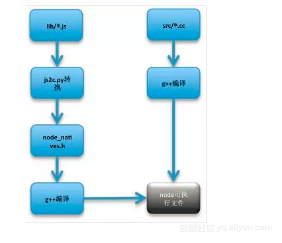
这里就要插入介绍一下 JavaScript native 模块代码是如何存储的了。Node.js 源码编译的时候,会采用 v8 附带的 js2c.py 工具,将 lib 文件夹下面的 js 模块的代码都转换成 C 里面的数组,生成一个 node_natives.h 头文件,记录这个数组:
namespace node {
const char node_native[] = {47, 47, 32, 67, 112 …}
const char console_native[] = {47, 47, 32, 67, 112 …}
const char buffer_native[] = {47, 47, 32, 67, 112 …}
…
}
struct _native {const char name; const char* source; size_t source_len;};
static const struct _native natives[] = {
{ “node”, node_native, sizeof(node_native)-1 },
{“dgram”, dgram_native, sizeof(dgram_native)-1 },
{“console”, console_native, sizeof(console_native)-1 },
{“buffer”, buffer_native, sizeof(buffer_native)-1 },
…
}
而上文中 NativeModule._source = process.binding('natives'); 的作用,就是取出这个 natives 数组,赋值给NativeModule._source,所以在 getSource 方法中,直接可以使用模块名作为索引,从数组中取出模块的源代码。
在这里我们插入回顾一下上文,在介绍 Node.js 编译的时候,我们介绍了 node.gyp,其中有一个任务是 node_js2c,当时笔者提到从名称看这个任务是将 JavaScript 转换为 C 代码,而这里的 natives 数组中的 C 代码,正是这个构建任务的产物。而到了这里,我们终于知道了这个编译任务的作用了。
知道了源码的获取,继续往下看 compile 方法,看看源码是如何编译的:
// lib/internal/bootstrap_node.js
NativeModule.wrap = function(script) {
return NativeModule.wrapper[0] + script + NativeModule.wrapper[1];
};
NativeModule.wrapper = [
'(function (exports, require, module, __filename, __dirname) { ',
'\n});'
];
NativeModule.prototype.compile = function() {
var source = NativeModule.getSource(this.id);
source = NativeModule.wrap(source);
this.loading = true;
try {
const fn = runInThisContext(source, {
filename: this.filename,
lineOffset: 0,
displayErrors: true
});
fn(this.exports, NativeModule.require, this, this.filename);
this.loaded = true;
} finally {
this.loading = false;
}
};
// ...
NativeModule.prototype.compile 在获取到源码之后,它主要做了:使用 wrap 方法处理源代码,最后调用 runInThisContext 进行编译得到一个函数,最后执行该函数。其中 wrap 方法,是给源代码加上了一头一尾,其实相当于是将源码包在了一个函数中,这个函数的参数有 exports, require, module 等。这就是为什么我们写模块的时候,不需要定义 exports, require, module 就可以直接用的原因。
至此就基本讲清楚了 Node.js 核心模块的加载过程。说到这里大家可能有一个疑惑,上述分析过程,好像只涉及到了核心模块中的 JavaScript native模块,那么对于 C/C++ built-in 模块呢?
其实是这样的,对于 built-in 模块而言,它们不是通过 require 来引入的,而是通过 precess.binding('模块名') 引入的。一般我们很少在自己的代码中直接使用 process.binding 来引入built-in模块,而是通过 require 引用native模块,而 native 模块里面会引入 built-in 模块。比如我们常用的 buffer 模块,其内部实现中就引入了 C/C++ built-in 模块,这是为了避开 v8 的内存限制:
// lib/buffer.js
'use strict';
// 通过 process.binding 引入名为 buffer 的 C/C++ built-in 模块
const binding = process.binding('buffer');
// ...
这样,我们在 require('buffer') 的时候,其实是间接的使用了 C/C++ built-in 模块。
这里再次出现了 process.binding!事实上,process.binding 这个方法定义在 node.cc 中:
// src/node.cc
// ...
static void Binding(const FunctionCallbackInfo<Value>& args) {
// ...
node_module* mod = get_builtin_module(*module_v);
// ...
}
// ...
env->SetMethod(process, "binding", Binding);
// ...
Binding 这个函数中关键的一步是 get_builtin_module。这里需要再次插入介绍一下 C/C++ 内建模块的存储方式:
在 Node.js 中,内建模块是通过一个名为 node_module_struct 的结构体定义的。所以的内建模块会被放入一个叫做 node_module_list 的数组中。而 process.binding 的作用,正是使用 get_builtin_module 从这个数组中取出相应的内建模块代码。
综上,我们就完整介绍了核心模块的加载原理,主要是区分 JavaScript 类型的 native 模块和 C/C++ 类型的 built-in 模块。这里绘制一张图来描述一下核心模块加载过程:
![3dc2463a0ea0e4c54a02ebe3b9b9d16b0c37a89c]()
而回忆我们在最开始介绍的,native 模块在源码中存放在 lib/ 目录下,而 built-in 模块在源码中存放在 src/ 目录下,下面这张图则从编译的角度梳理了 native 和 built-in 模块如何被编译进 Node.js 可执行文件:
![86ff444911475f7be3d19655b4c82a04e5de3616]()
4.2 第三方模块加载原理
下面让我们继续分析第二个分支,假设我们的 index.js 中 require 的不是 http,而是一个用户自定义模块,那么在 module.js 中, 我们会走到 tryModuleLoad 方法中:
// lib/module.js
// ...
function tryModuleLoad(module, filename) {
var threw = true;
try {
module.load(filename);
threw = false;
} finally {
if (threw) {
delete Module._cache[filename];
}
}
}
// ...
Module.prototype.load = function(filename) {
debug('load %j for module %j', filename, this.id);
assert(!this.loaded);
this.filename = filename;
this.paths = Module._nodeModulePaths(path.dirname(filename));
var extension = path.extname(filename) || '.js';
if (!Module._extensions[extension]) extension = '.js';
Module._extensions[extension](this, filename);
this.loaded = true;
};
// ...
这里看到,tryModuleLoad 中实际调用了 Module.prototype.load 定义的方法,这个方法主要做的事情是,检测 filename 的扩展名,然后针对不同的扩展名,调用不同的 Module._extensions 方法来加载、编译模块。接着我们看看 Module._extensions:
// lib/module.js
// ...
// Native extension for .js
Module._extensions['.js'] = function(module, filename) {
var content = fs.readFileSync(filename, 'utf8');
module._compile(internalModule.stripBOM(content), filename);
};
// Native extension for .json
Module._extensions['.json'] = function(module, filename) {
var content = fs.readFileSync(filename, 'utf8');
try {
module.exports = JSON.parse(internalModule.stripBOM(content));
} catch (err) {
err.message = filename + ': ' + err.message;
throw err;
}
};
//Native extension for .node
Module._extensions['.node'] = function(module, filename) {
return process.dlopen(module, path._makeLong(filename));
};
// ...
可以看出,一共支持三种类型的模块加载:.js, .json, .node。其中 .json 类型的文件加载方法是最简单的,直接读取文件内容,然后 JSON.parse 之后返回对象即可。
下面来看对 .js 的处理,首先也是通过 fs 模块同步读取文件内容,然后调用了 module._compile,看看相关代码:
// lib/module.js
// ...
Module.wrap = NativeModule.wrap;
// ...
Module.prototype._compile = function(content, filename) {
// ...
// create wrapper function
var wrapper = Module.wrap(content);
var compiledWrapper = vm.runInThisContext(wrapper, {
filename: filename,
lineOffset: 0,
displayErrors: true
});
// ...
var result = compiledWrapper.apply(this.exports, args);
if (depth === 0) stat.cache = null;
return result;
};
// ...
首先调用 Module.wrap 对源代码进行包裹,之后调用 vm.runInThisContext 方法进行编译执行,最后返回 exports 的值。而从 Module.wrap = NativeModule.wrap 这一句可以看出,第三方模块的 wrap 方法,和核心模块的 wrap 方法是一样的。我们回忆一下刚才讲到的核心js模块加载关键代码:
// lib/internal/bootstrap_node.js
NativeModule.wrap = function(script) {
return NativeModule.wrapper[0] + script + NativeModule.wrapper[1];
};
NativeModule.wrapper = [
'(function (exports, require, module, __filename, __dirname) { ',
'\n});'
];
NativeModule.prototype.compile = function() {
var source = NativeModule.getSource(this.id);
source = NativeModule.wrap(source);
this.loading = true;
try {
const fn = runInThisContext(source, {
filename: this.filename,
lineOffset: 0,
displayErrors: true
});
fn(this.exports, NativeModule.require, this, this.filename);
this.loaded = true;
} finally {
this.loading = false;
}
};
两厢对比,发现二者对源代码的编译执行几乎是一模一样的。从整体流程上来讲,核心 JavaScript 模块与第三方 JavaScript 模块最大的不同就是,核心 JavaScript 模块源代码是通过 process.binding('natives') 从内存中获取的,而第三方 JavaScript 模块源代码是通过 fs.readFileSync 方法从文件中读取的。
最后,再来看一下加载第三方 C/C++模块(.node后缀)。直观上来看,很简单,就是调用了 process.dlopen 方法。这个方法的定义在 node.cc 中:
// src/node.cc
// ...
env->SetMethod(process, "dlopen", DLOpen);
// ...
void DLOpen(const FunctionCallbackInfo<Value>& args) {
// ...
const bool is_dlopen_error = uv_dlopen(*filename, &lib);
// ...
}
// ...
实际上最终调用了 DLOpen 函数,该函数中最重要的是使用 uv_dlopen 方法打开动态链接库,然后对 C/C++ 模块进行加载。uv_dlopen 方法是定义在 libuv 库中的。libuv 库是一个跨平台的异步 IO 库。对于扩展模块的动态加载这部分功能,在 *nix 平台下,实际上调用的是 dlfcn.h 中定义的 dlopen() 方法,而在 Windows 下,则为 LoadLibraryExW() 方法,在两个平台下,他们加载的分别是 .so 和 .dll 文件,而 Node.js 中,这些文件统一被命名了 .node 后缀,屏蔽了平台的差异。
关于 libuv 库,是 Node.js 异步 IO 的核心驱动力,这一块本身就值得专门作为一个专题来研究,这里就不展开讲了。
到此为止,我们理清楚了三种第三方模块的加载、编译过程。
5. C/C++ 扩展模块的开发以及应用场景
上文分析了 Node.js 当中各类模块的加载流程。大家对于 JavaScript 模块的开发应该是驾轻就熟了,但是对于 C/C++ 扩展模块开发可能还有些陌生。这一节就简单介绍一下扩展模块的开发,并谈谈其应用场景。
关于 Node.js 扩展模块的开发,在 Node.js 官网文档中专门有一节予以介绍,大家可以移步官网文档查看:https://nodejs.org/docs/latest-v6.x/api/addons.html 。这里仅仅以其中的 hello world 例子来介绍一下编写扩展模块的一些比较重要的概念:
假设我们希望通过扩展模块来实现一个等同于如下 JavaScript 函数的功能:
module.exports.hello = () => 'world';
首先创建一个 hello.cc 文件,编写如下代码:
// hello.cc
#include <node.h>
namespace demo {
using v8::FunctionCallbackInfo;
using v8::Isolate;
using v8::Local;
using v8::Object;
using v8::String;
using v8::Value;
void Method(const FunctionCallbackInfo<Value>& args) {
Isolate* isolate = args.GetIsolate();
args.GetReturnValue().Set(String::NewFromUtf8(isolate, "world"));
}
void init(Local<Object> exports) {
NODE_SET_METHOD(exports, "hello", Method);
}
NODE_MODULE(NODE_GYP_MODULE_NAME, init)
} // namespace demo
文件虽短,但是已经出现了一些我们比较陌生的代码,这里一一介绍一下,对于了解扩展模块基础知识还是很有帮助的。
首先在开头引入了 node.h,这个是编写 Node.js 扩展时必用的头文件,里面几乎包含了我们所需要的各种库、数据类型。
其次,看到了很多 using v8:xxx 这样的代码。我们知道,Node.js 是基于 v8 引擎的,而 v8 引擎,就是用 C++ 来写的。我们要开发 C++ 扩展模块,便需要使用 v8 中提供的很多数据类型,而这一系列代码,正是声明了需要使用 v8 命名空间下的这些数据类型。
然后来看 Method 方法,它的参数类型 FunctionCallbackInfo<Value>& args,这个 args 就是从 JavaScript 中传入的参数,同时,如果想在 Method 中为 JavaScript 返回变量,则需要调用 args.GetReturnValue().Set 方法。
接下来需要定义扩展模块的初始化方法,这里是 Init 函数,只有一句简单的 NODE_SET_METHOD(exports, "hello", Method);,代表给 exports 赋予一个名为 hello 的方法,这个方法的具体定义就是 Method 函数。
最后是一个宏定义:NODE_MODULE(NODE_GYP_MODULE_NAME, init),第一个参数是希望的扩展模块名称,第二个参数就是该模块的初始化方法。
为了编译这个模块,我们需要通过npm安装 node-gyp 编译工具。该工具将 Google 的 gyp 工具封装,用来构建 Node.js 扩展。安装这个工具后,我们在源码文件夹下面增加一个名为 bingding.gyp 的配置文件,对于我们这个例子,文件只要这样写:
{
"targets": [
{
"target_name": "addon",
"sources": [ "hello.cc" ]
}
]
}
这样,运行 node-gyp build 即可编译扩展模块。在这个过程中,node-gyp 还会去指定目录(一般是 ~/.node-gyp)下面搜我们当前 Node.js 版本的一些头文件和库文件,如果不存在,它还会帮我们去 Node.js 官网下载。这样,在编写扩展的时候,通过 #include <>,我们就可以直接使用所有 Node.js 的头文件了。
如果编译成功,会在当前文件夹的 build/Release/ 路径下看到一个 addon.node,这个就是我们编译好的可 require 的扩展模块。
从上面的例子中,我们能大体看出扩展模块的运作模式,它可以接收来自 JavaScript 的参数,然后中间可以调用 C/C++ 语言的能力去做各种运算、处理,然后最后可以将结果再返回给 JavaScript。
值得注意的是,不同 Node.js 版本,依赖的 v8 版本不同,导致很多 API 会有差别,因此使用原生 C/C++ 开发扩展的过程中,也需要针对不同版本的 Node.js 做兼容处理。比如说,声明一个函数,在 v6.x 和 v0.12 以下的版本中,分别需要这样写:
Handle<Value> Example(const Arguments& args); // 0.10.x
void Example(FunctionCallbackInfo<Value>& args); // 6.x
可以看到,函数的声明,包括函数中参数的写法,都不尽相同。这让人不由得想起了在 Node.js 开发中,为了写 ES6,也是需要使用 Babel 来帮忙进行兼容性转换。那么在 Node.js 扩展开发领域,有没有类似 Babel 这样帮助我们处理兼容性问题的库呢?答案是肯定的,它的名字叫做 NAN (Native Abstraction for Node.js)。它本质上是一堆宏,能够帮助我们检测 Node.js 的不同版本,并调用不同的 API。例如,在 NAN 的帮助下,声明一个函数,我们不需要再考虑 Node.js 版本,而只需要写一段这样的代码:
#include <nan.h>
NAN_METHOD(Example) {
// ...
}
NAN 的宏会在编译的时候自动判断,根据 Node.js 版本的不同展开不同的结果,从而解决了兼容性问题。对 NAN 更详细的介绍,感兴趣的同学可以移步该项目的 github 主页:https://github.com/nodejs/nan。
介绍了这么多扩展模块的开发,可能有同学会问了,像这些扩展模块实现的功能,看起来似乎用js也可以很快的实现,何必大费周折去开发扩展呢?这就引出了一个问题:C/C++ 扩展的适用场景。
笔者在这里大概归纳了几类 C/C++ 适用的情景:
- 计算密集型应用。我们知道,Node.js 的编程模型是单线程 + 异步 IO,其中单线程导致了它在计算密集型应用上是一个软肋,大量的计算会阻塞 JavaScript 主线程,导致无法响应其他请求。对于这种场景,就可以使用 C/C++ 扩展模块,来加快计算速度,毕竟,虽然 v8 引擎的执行速度很快,但终究还是比不过 C/C++。另外,使用 C/C++,还可以允许我们开多线程,避免阻塞 JavaScript 主线程,社区里目前已经有一些基于扩展模块的 Node.js 多线程方案,其中最受欢迎的可能是一个叫做 thread-a-gogo 的项目,具体可以移步 github:https://github.com/xk/node-threads-a-gogo。
- 内存消耗较大的应用。Node.js 是基于 v8 的,而 v8 一开始是为浏览器设计的,所以其在内存方面是有比较严格的限制的,所以对于一些需要较大内存的应用,直接基于 v8 可能会有些力不从心,这个时候就需要使用扩展模块,来绕开 v8 的内存限制,最典型的就是我们常用的 buffer.js 模块,其底层也是调用了 C++,在 C++ 的层面上去申请内存,避免 v8 内存瓶颈。
关于第一点,笔者这里也分别用原生 Node.js 以及 Node.js 扩展实现了一个测试例子来对比计算性能。测试用例是经典的计算斐波那契数列,首先使用 Node.js 原生语言实现一个计算斐波那契数列的函数,取名为 fibJs:
function fibJs(n) {
if (n === 0 || n === 1) {
return n;
}
else {
return fibJs(n - 1) + fibJs(n - 2);
}
}
然后使用 C++ 编写一个实现同样功能的扩展函数,取名 fibC:
// fibC.cpp
#include <node.h>
#include <math.h>
using namespace v8;
int fib(int n) {
if (n == 0 || n ==1) {
return n;
}
else {
return fib(n - 1) + fib(n - 2);
}
}
void Method(const FunctionCallbackInfo<Value>& args) {
Isolate* isolate = args.GetIsolate();
int n = args[0]->NumberValue();
int result = fib(n);
args.GetReturnValue().Set(result);
}
void init(Local < Object > exports, Local < Object > module) {
NODE_SET_METHOD(module, "exports", Method);
}
NODE_MODULE(fibC, init)
在测试中,分别使用这两个函数计算从 1~40 的斐波那契数列:
function testSpeed(fn, testName) {
var start = Date.now();
for (var i = 0; i < 40; i++) {
fn(i);
}
var spend = Date.now() - start;
console.log(testName, 'spend time: ', spend);
}
// 使用扩展模块测试
var fibC = require('./build/Release/fibC'); // 这里是扩展模块编译产物的存放路径
testSpeed(fibC, 'c++ test:');
// 使用 JavaScript 函数进行测试
function fibJs(n) {
if (n === 0 || n === 1) {
return n;
}
else {
return fibJs(n - 1) + fibJs(n - 2);
}
}
testSpeed(fibJs, 'js test:');
// c++ test: spend time: 1221
// js test: spend time: 2611
多次测试,扩展模块平均花费时长大约 1.2s,而 JavaScript 模块花费时长大约 2.6s,可见在此场景下,C/C++ 扩展性能还是要快上不少的。
当然,这几点只是基于笔者的认识。在实际开发过程中,大家在遇到问题的时候,也可以尝试着考虑如果使用 C/C++ 扩展模块,问题是不是能够得到更好的解决。
结语
文章读到这里,我们再回去看一下一开始提出的那些问题,是否在文章分析的过程中都得到了解答?再来回顾一下本文的逻辑脉络:
- 首先以一个node index.js 的运行原理开始,指出使用node 运行一个文件,等同于立即执行一次require 。
- 然后引出了node中的require方法,在这里,区分了核心模块、内建模块和非核心模块几种情况,分别详述了加载、编译的流程原理。在这个过程中,还分别涉及到了模块路径解析、模块缓存等等知识点的描述。
- 最后介绍了大家不太熟悉的c/c++扩展模块的开发,并结合一个性能对比的例子来说明其适用场景。
事实上,通过学习 Node.js 模块加载流程,有助于我们更深刻的了解 Node.js 底层的运行原理,而掌握了其中的扩展模块开发,并学会在适当的场景下使用,则能够使得我们开发出的 Node.js 应用性能更高。
学习 Node.js 原理是一条漫长的路径。建议了解了底层模块机制的读者,可以去更深入的学习 v8, libuv 等等知识,对于精通 Node.js,必将大有裨益。
原文发布时间为:2018-08-15
本文作者:马龄阳
本文来自云栖社区合作伙伴“前端大学”,了解相关信息可以关注“前端大学”微信公众号