在简书也码了1W多字了,发现还是爬虫类的文章看的人多。
算法工程师现在都啥价位了,你们还在看爬虫→_→
介绍
这次爬的是当下大火的APP--抖音,批量下载一个用户发布的所有视频。
各位也应该知道,抖音只有移动端,官网打开除了给你个APP下载二维码啥也没有,所以相比爬PC网站,还是遇到了更多的问题,也花了更多的时间,不过好在基本实现了,除了一点咱在后面说。
思路梳理
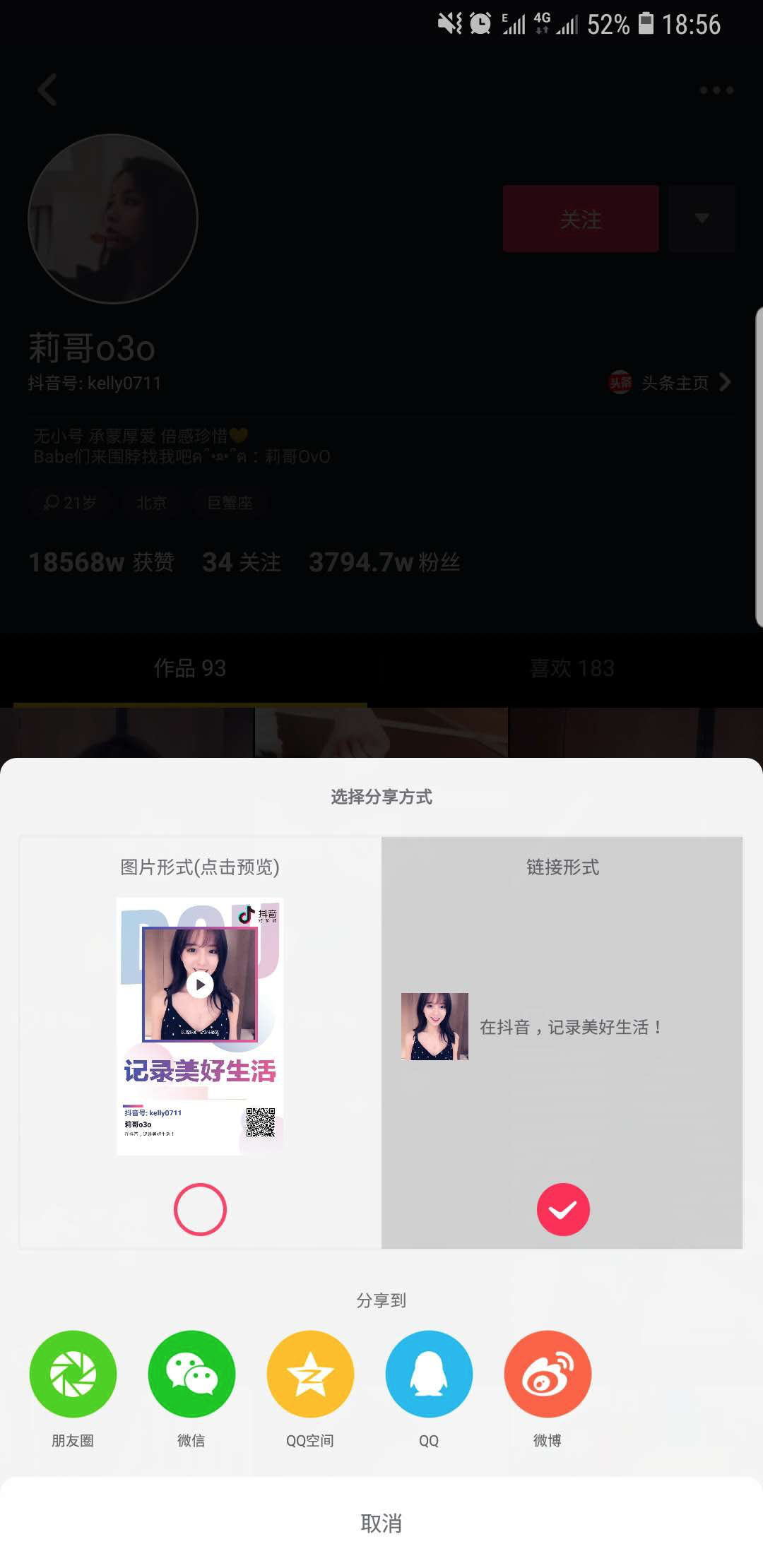
- 其实如果看了其他博主爬抖音的教程就发现,大部分都是通过fildder手机抓包来获取接口地址等信息,其实不用那么麻烦,我们通过分享选择链接形式就可以获取到信息:
-
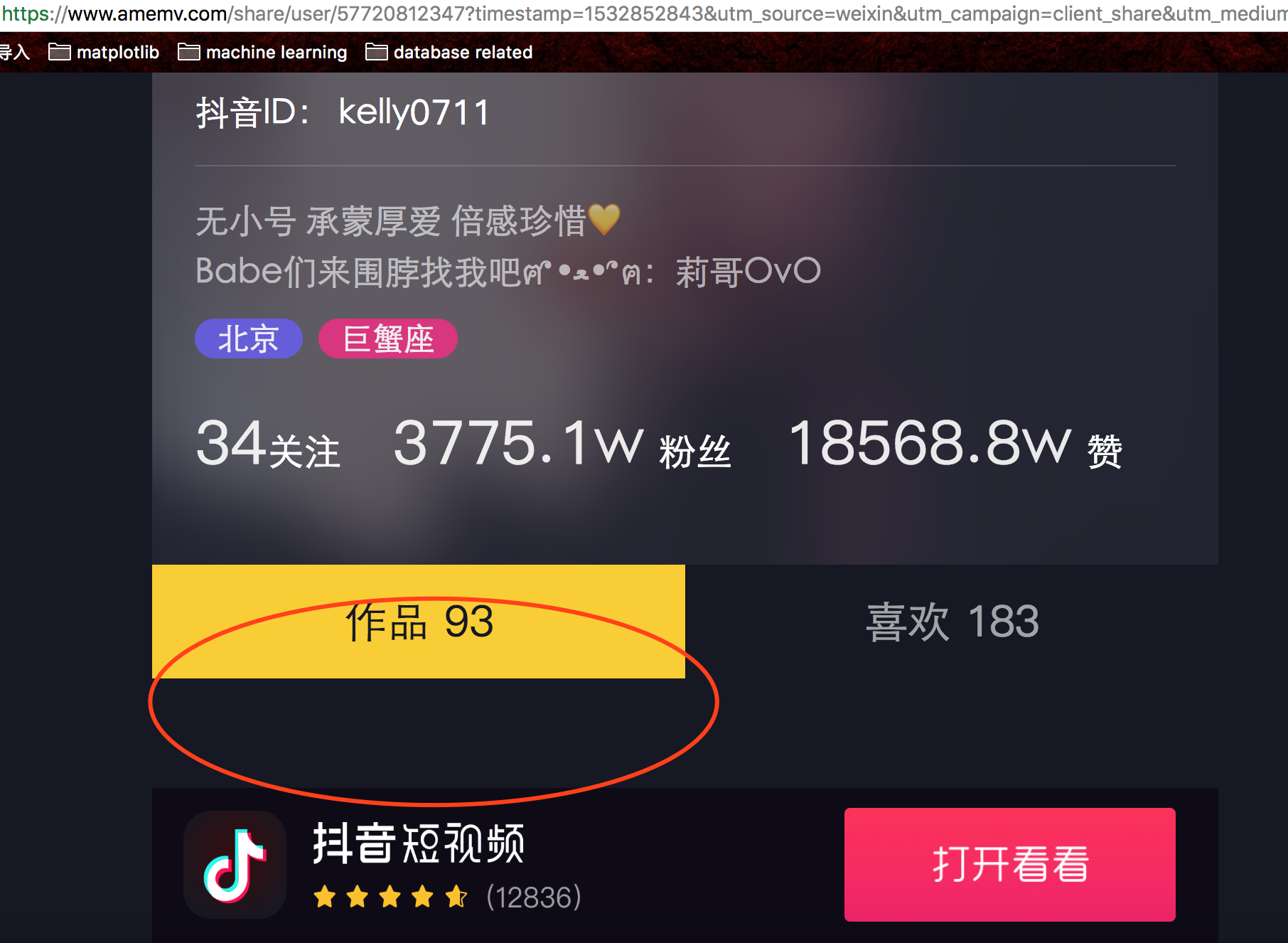
然后电脑访问这个链接,就可以打开页面了,不过很快我们就会发现一个问题,电脑访问这个地址发布视频是空的:
-
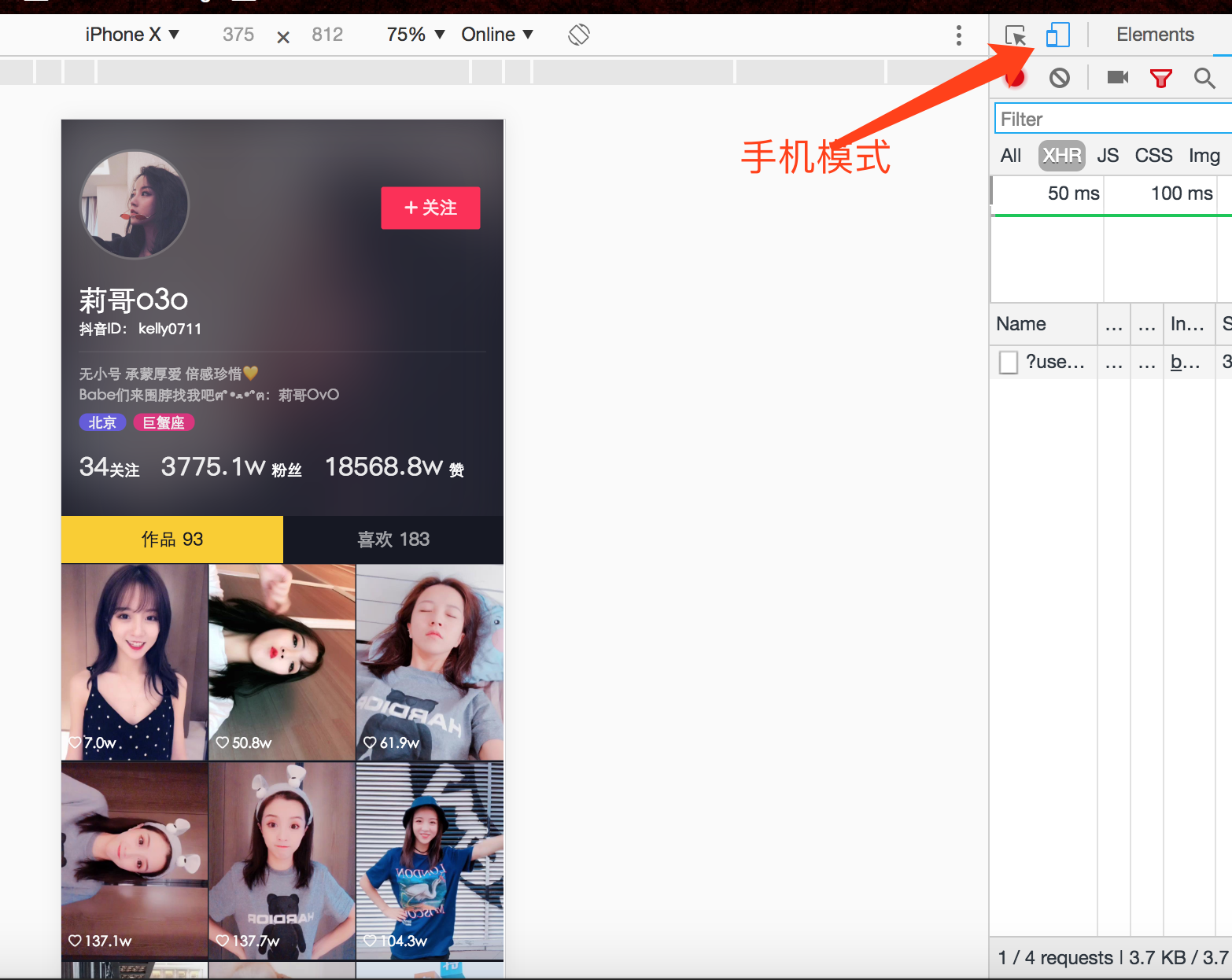
谷歌Chrome浏览器有一个模拟手机访问的功能,我们选在iPhone X模式来访问页面,果然看到发布的视频了:
-
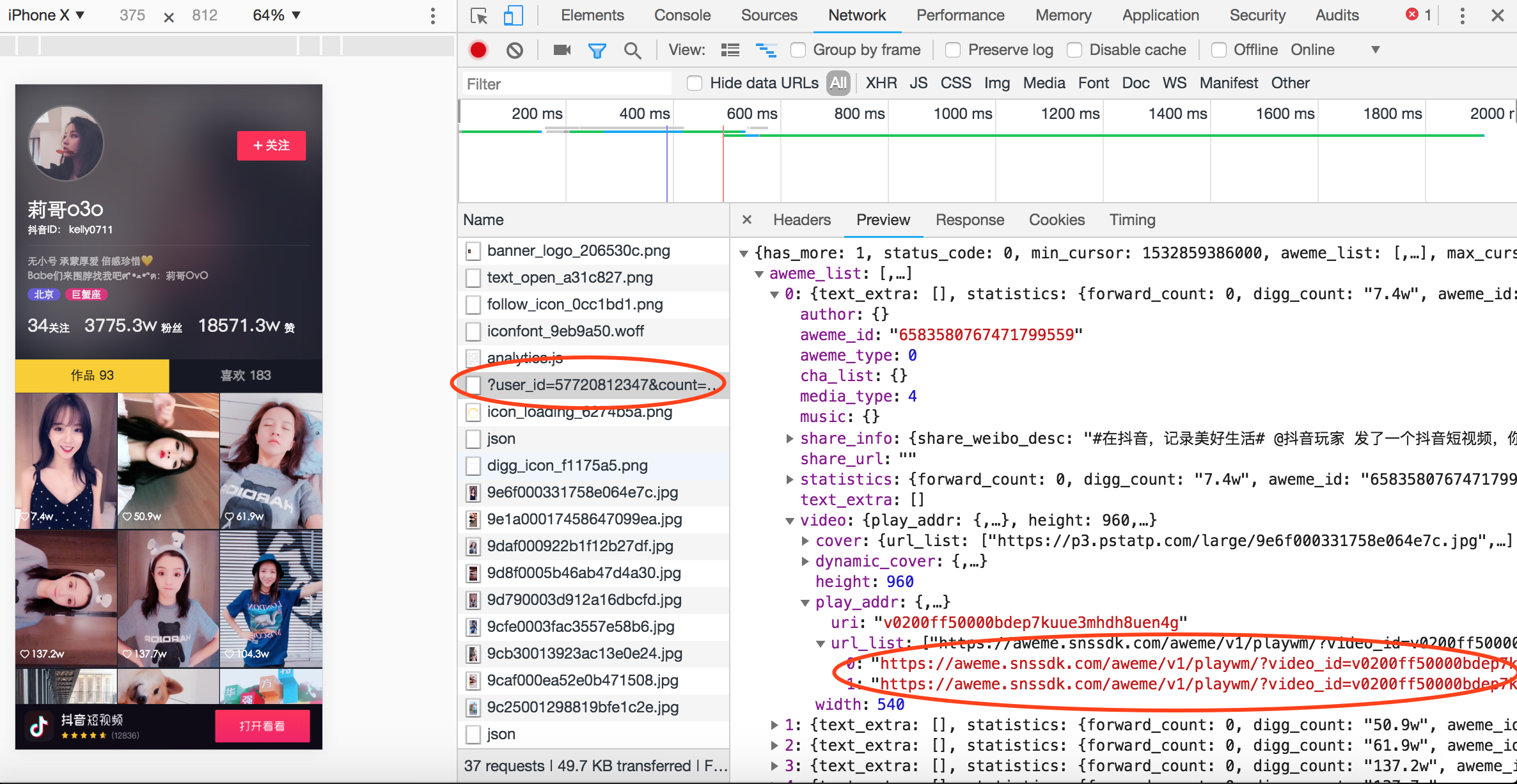
我们接下来看下后台请求,不多,很快就找到我们需要的视频信息了,也能直接打开观看视频,到这感觉已经成功了一大半了:
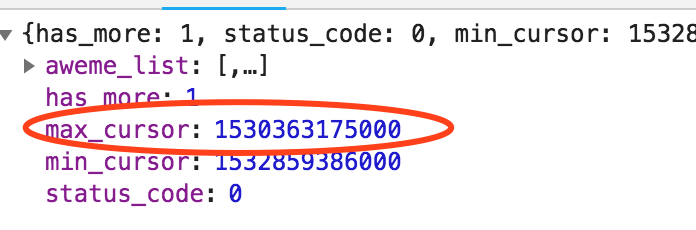
- 但很快我们有发现了新问题,可以看到莉哥总共发布了93个作品,但我们实际获取到但链接只有19个。其实我们用过抖音,包括微博这些应用的都知道,很多信息他们不是一次加载完的,当你拖动页面的时候才会继续加载。所以我们尝试上拉页面,就会发现后台又多了一个请求,返回了新加载的视频信息。
https://www.amemv.com/aweme/v1/aweme/post/?user_id=57720812347&count=21&max_cursor=0&aid=1128&_signature=KRLTTRAdclaWZCKrElzZVykS01&dytk=4830f6e279a5f53872aab9e9dc112d33
https://www.amemv.com/aweme/v1/aweme/post/?user_id=57720812347&count=21&max_cursor=1530363175000&aid=1128&_signature=KRLTTRAdclaWZCKrElzZVykS01&dytk=4830f6e279a5f53872aab9e9dc112d33
两个地址除了max_cursor其他都一样,其实就是上一条返回的json数据中的max_cursor就是下个链接中的max_cursor,然后has_more等于1的时候表示还未全部加载,这样逻辑就清楚了,我们只要先判断has_more是否等于1,等于1的时候我们将max_cursor的值传入下一个链接继续访问获取视频地址,直到has_more等于0为止。
-
这样所有视频地址都有了,就开始下载吧!!
代码部分
# -*- coding: utf-8 -*-
#date : 2018-07-29
#author : Awesome_Tang
#version : Python 2.7.9
from selenium import webdriver
from bs4 import BeautifulSoup
import json
import requests
import sys
import time
import os
import uuid
from contextlib import closing
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
class douyin_spider(object):
"""docstring for douyin_spider"""
def __init__(self,user_id,_signature,dytk):
print '*******DouYin_spider******'
print 'Author : Awesome_Tang'
print 'Date : 2018-07-29'
print 'Version: Python2.7'
print '**************************'
print ''
self.userid = user_id
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36'}
mobile_emulation = {'deviceName': 'iPhone X'}
# chrome浏览器模拟iPhone X进行页面访问
options = webdriver.ChromeOptions()
options.add_experimental_option("mobileEmulation", mobile_emulation)
self.browser = webdriver.Chrome(chrome_options=options)
self._signature= _signature
self.dytk= dytk
self.url = 'https://www.amemv.com/aweme/v1/aweme/post/?user_id=%s&count=32&max_cursor=0&aid=1128&_signature=%s&dytk=%s'%(self.userid,self._signature,self.dytk)
def handle_url(self):
url_list = [self.url,]
self.browser.get(self.url)
web_data = self.browser.page_source
soup = BeautifulSoup(web_data, 'lxml')
web_data = soup.pre.string
web_data = json.loads(str(web_data))
if web_data['status_code'] == 0:
while web_data['has_more'] == 1:
# 最大加载32条视频信息,has_more等于1表示还未全部加载完
max_cursor = web_data['max_cursor']
# 获取时间戳
url = 'https://www.amemv.com/aweme/v1/aweme/post/?user_id=%s&count=32&max_cursor=%s&aid=1128&_signature=%s&dytk=%s'%(self.userid,max_cursor,self._signature,self.dytk)
url_list.append(url)
self.browser.get(url)
web_data = self.browser.page_source
soup = BeautifulSoup(web_data, 'lxml')
web_data = soup.pre.string
web_data = json.loads(str(web_data))
else:
max_cursor = web_data['max_cursor']
# 获取时间戳
url = 'https://www.amemv.com/aweme/v1/aweme/post/?user_id=%s&count=32&max_cursor=%s&aid=1128&_signature=%s&dytk=%s'%(self.userid,max_cursor,self._signature,self.dytk)
url_list.append(url)
else:
url_list = []
return url_list
def get_download_url(self,url_list):
download_url = []
title_list = []
if len(url_list)> 0:
for url in url_list:
self.browser.get(url)
web_data = self.browser.page_source
soup = BeautifulSoup(web_data, 'lxml')
web_data = soup.pre.string
web_data = json.loads(str(web_data))
if web_data['status_code'] == 0:
for i in range(len(web_data['aweme_list'])):
download_url.append(web_data['aweme_list'][i]['video']['play_addr']['url_list'][0])
title_list.append(web_data['aweme_list'][i]['share_info']['share_desc'].encode('utf-8'))
return download_url,title_list
def videodownloader(self,url,title):
size = 0
path = title+'.mp4'
with closing(requests.get(url, headers = self.headers ,stream=True, verify=False)) as response:
chunk_size = 1024
content_size = int(response.headers['content-length'])
if response.status_code == 200:
print '%s is downloading...'%title
sys.stdout.write('[File Size]: %0.2f MB\n' % (content_size/chunk_size/1024))
with open(path, 'wb') as f:
for data in response.iter_content(chunk_size=chunk_size):
f.write(data)
size += len(data)
f.flush()
sys.stdout.write('[Progress]: %0.2f%%' % float(size/content_size*100) + '\r')
sys.stdout.flush()
else:
print response.status_code
def run(self):
url = 'https://www.amemv.com/aweme/v1/aweme/post/?user_id=%s&count=32&max_cursor=0&aid=1128&_signature=%s&dytk=%s'%(self.userid,self._signature,self.dytk)
url_list = self.handle_url()
download_url,title_list = self.get_download_url(url_list)
for i in range(len(download_url)):
url = download_url[i]
title = title_list[i]
self.videodownloader(url,title)
if __name__ == '__main__':
# 创建对象
# 传入三个参数,user_id,_signature,dytk
douyin_spider = douyin_spider('95870186531','RFE1JhAbHxD7J8TA9HCumURRNT','539f2c59bb57577983b3818b7a7f32ef')
douyin_spider.run()
print '******DouYin_spider@Awesome_Tang、******'
问题
- 开始说了,目前还存在一个问题,我们看接口地址可以发现,目前需要5个参数分别是:
user_id, max_cursor,count,_signature, dytk
前面三个都没问题,而且我看有的博主5/6月份都文章都还只需要前三个参数,_signature, dytk是两个加密之后的参数,不知道咋加密的,而且selenium似乎也没有获取后台请求地址的方法,返回的视频地址也没有在页面进行渲染,所以现在还需要点击分享链接之后手动填入_signature, dytk两个值,有点冒傻气~
skr~skr~~