目录
0. 参考地址
基本介绍 https://www.cnblogs.com/yinheyi/p/8127871.html
实验演示 https://www.cnblogs.com/xybaby/p/6406191.html#_label_2
详细讲解 http://aju.space/2017/07/31/Drive-into-python-asyncio-programming-part-1.html
官方文档selecotors https://docs.python.org/3/library/selectors.html
官方文档select https://docs.python.org/3/library/select.html
1. 前言
并发的解决方案中,因为阻塞IO调用的原因,同步模型(串行/多进程/多线程)并不适合大规模高并发.在非阻塞IO调用中,我们可以使用一个线程完成高并发的功能,不过因为非阻塞IO会立即返回,如何判断IO准备就绪以及就绪之后如何处理就变成了关键,所以我们需要附带额外的处理.
不论使用哪一种额外处理方式,核心都是为了获知IO准备就绪且执行对应的操作,额外处理方式之一就是回调+事件循环.
OS已经为我们提供了select/poll/epoll/kqueue等多种底层操作系统接口用以处理IO准备就绪的通知(即通过OS提供的接口可以方便的编写事件循环).而程序还需要完成:如何在IO准备就绪的时候执行预定的操作.
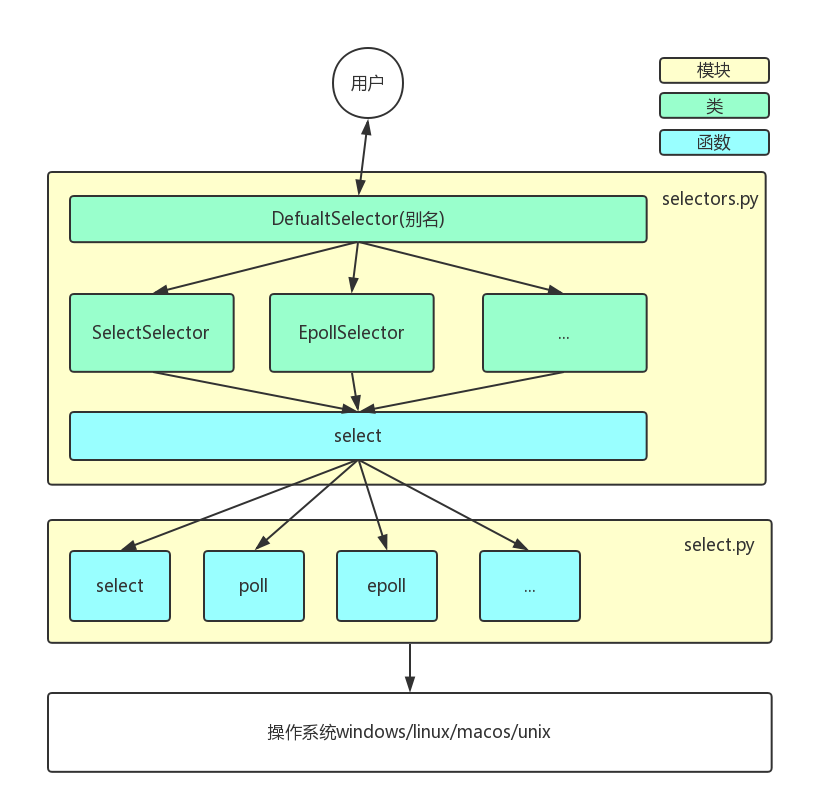
selecotrs模块,总代码611行,其中有5个类是同一个级别,只是根据OS的类型而有所不同.模块中还包含大量的注释,所以核心代码数量就在100行左右.selectors模块为我们提供了异步编程中的回调模型(后面还会写异步编程中的协程模型),所以我觉得对此模块的研究是很有必要的.
2. 核心类
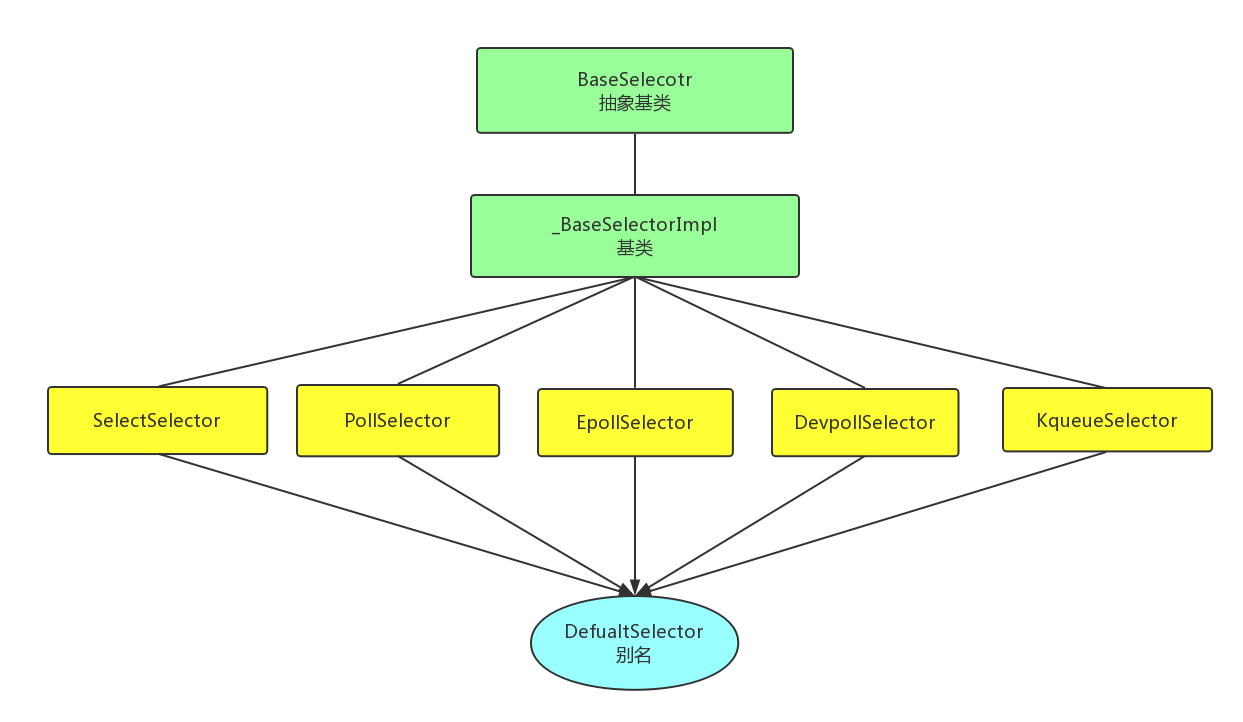
selectors模块中的核心类如下:
![img_8492f5c46f2113dc98aeff6af62d236e.jpe]()
BaseSelector:是一个抽象基类,定义了核心子类的函数接口.BaseSelector类定义的核心接口如下:
@abstractmethod
register(self, fileobj, events, data=None) # 提供文件对象的注册
@abstractmethod
unregister(self, fileobj) # 注销已注册的文件对象
@abstractmethod
select(self, timeout=None) # 向OS查询准备就绪的文件对象
其中,前两个函数封装了文件对象,并提供了data变量用于保存附加数据,这就提供了回调的环境.第三个函数select是对OS底层select/poll/epoll接口的封装,用以提供一个统一的对外接口.
_BaseSelectorImpl:是一个实现了register和unregister的基类,注意,此基类并没有实现select函数,因为select函数在不同OS上使用的底层接口不同,所以应该在对应的子类中定义
SelectSelector:使用windows时的接口
EpollSelector:使用linux时的接口(其他3个类相似,只是应用于不同的OS)
DefaultSelector:此为类别名,selectors模块会根据所在操作系统的类型,选择最优的接口
如下只对selectselector类的核心代码进行分析,其他对应类的代码逻辑基本一致.
3. SelectSelector核心函数代码分析
有名元祖selectorkey
SelectorKey = namedtuple('SelectorKey', ['fileobj', 'fd', 'events', 'data'])
此对象是一个有名元祖,可以认为是对文件对象fileobj,对应的描述符值fd,对应的事件events,附带的数据data这几个属性的封装.此对象是核心操作对象,关联了需要监控的文件对象,关联了需要OS关注的事件,保存了附带数据(其实这里就放的回调函数)
3.1 注册
def __init__(self):
super().__init__()
self._readers = set() # 使用集合处理唯一性
self._writers = set()
首先,构造函数中定义了_readers和_writers变量用于保存需要监听的文件对象的文件描述符值,并使用集合特性来处理唯一性.
def register(self, fileobj, events, data=None):
key = super().register(fileobj, events, data)
if events & EVENT_READ:
self._readers.add(key.fd)
if events & EVENT_WRITE:
self._writers.add(key.fd)
return key
一般我们使用register作为第一个操作的函数,代表着你需要监听的文件对象,以及,当它发生你关注的事件时,你要如何处理.
此函数有3个参数,分别是文件对象,监听事件(可读为1,可写为2),附带数据.
fileobj文件对象是类文件对象,与平台强相关,在windows上只能是socket,在linux上可以是任何linux支持的文件对象.
events是一个int类型的值,就是EVENT_ERAD和EVENT_WRITE
data是附带数据,我们可以把回调函数放在这里
此函数返回的key就是一个selectorkey有名元祖
register函数将用户监听的文件对象和事件注册到有名元祖中,并加入监听集合_readers和_writers中
3.2 注销
def unregister(self, fileobj):
key = super().unregister(fileobj)
self._readers.discard(key.fd)
self._writers.discard(key.fd)
return key
当我们不需要监听某一个文件对象时,使用unregister注销它.这会使得它从_readers和_writers中被弹出.
3.3 查询
def select(self, timeout=None):
timeout = None if timeout is None else max(timeout, 0)
ready = []
try:
r, w, _ = self._select(self._readers, self._writers, [], timeout)
except InterruptedError:
return ready
r = set(r)
w = set(w)
for fd in r | w:
events = 0
if fd in r:
events |= EVENT_READ
if fd in w:
events |= EVENT_WRITE
key = self._key_from_fd(fd)
if key:
ready.append((key, events & key.events))
return ready
这段代码描述了用户向OS发起的查询逻辑.select函数的timeout参数默认是None,这意味着默认情况下,如果没有任何一个就绪事件的发生,select调用会被永远阻塞.
select函数调用底层select/poll/epoll接口,此函数在SelectSelector类和EpollSelector类中的定义有所区别,会根据OS的类型调用对应接口,windows和linux实际调用的底层接口对比如下:
用户统一调用高层select函数,此函数实际调用的接口为:
# windows下使用select(SelectSelector类)
r, w, _ = self._select(self._readers, self._writers, [], timeout)
# linux下使用epoll(EpollSelector类)
fd_event_list = self._epoll.poll(timeout, max_ev)
函数使用ready变量保存准备就绪的元祖(key, events)
在windows中,一旦底层select接口返回,会得到3个列表,前两个表示可读和可写的文件对象列表,并使用集合处理为唯一性.准备就绪的元祖对象会加入ready列表中返回.如果定义了timeout不为None,且发生了超时,会返回一个空列表.
4. 别名
# Choose the best implementation, roughly:
# epoll|kqueue|devpoll > poll > select.
# select() also can't accept a FD > FD_SETSIZE (usually around 1024)
if 'KqueueSelector' in globals():
DefaultSelector = KqueueSelector
elif 'EpollSelector' in globals():
DefaultSelector = EpollSelector
elif 'DevpollSelector' in globals():
DefaultSelector = DevpollSelector
elif 'PollSelector' in globals():
DefaultSelector = PollSelector
else:
DefaultSelector = SelectSelector
selectors模块定义了一个别名DefaultSelector用于根据OS类型自动指向最优的接口类.
5. 总结
1 操作系统提供的select/poll/epoll接口可以用于编写事件循环,而selectors模块封装了select模块,select模块是一个低级别的模块,封装了select/poll/epoll/kqueue等接口.
2 selectors模块中定义了有名元祖selectorkey,此对象封装了文件对象/描述符值/事件/附带数据,selectorkey为我们提供了回调的环境
3 使用selectors模块可以实现使用回调模型来完成高并发的方案.
4 (非常重要)异步回调模型,大部分事件和精力都是对回调函数的设计.回调模型使得每一个涉及IO操作的地方都需要单独分割出来作为函数,这会分割代码导致可读性下降和维护难度的上升.
5 回调函数之间的通信很困难,需要通过层层函数传递.
6 回调模型很难理解
6. 代码报错问题
1. 文件描述符数量
Traceback (most recent call last):
File "F:/projects/hello/hello.py", line 119, in <module>
loop()
File "F:/projects/hello/hello.py", line 102, in loop
events = selector.select()
File "F:\projects\hello\selectors.py", line 323, in select
r, w, _ = self._select(self._readers, self._writers, [], timeout)
File "F:\projects\hello\selectors.py", line 314, in _select
r, w, x = select.select(r, w, w, timeout)
ValueError: too many file descriptors in select()
在windows上,底层使用的是select接口,可以支持的文件描述符数量理论说是1024,实际测试描述符必须小于512(我的电脑是win10 64bit)
在linux上使用的是epoll,可以支持大于1024的文件描述符数量,不过测试发现在达到4000左右的时候也会报错。
stack overflow解释1:https://stackoverflow.com/questions/31321127/too-many-file-descriptors-in-select-python-in-windows
stack overflow解释2:
https://stackoverflow.com/questions/47675410/python-asyncio-aiohttp-valueerror-too-many-file-descriptors-in-select-on-win
2. 监听列表是否可以为空
Traceback (most recent call last):
File "F:/projects/hello/world.py", line 407, in <module>
loop()
File "F:/projects/hello/world.py", line 378, in loop
events = selector.select()
File "F:\projects\hello\selectors.py", line 323, in select
r, w, _ = self._select(self._readers, self._writers, [], timeout)
File "F:\projects\hello\selectors.py", line 314, in _select
r, w, x = select.select(r, w, w, timeout)
OSError: [WinError 10022] 提供了一个无效的参数。
在windows上,监听的文件对象列表不可以为空:
![img_9afd45af30a40359b9e9369a03cb48de.png]()
7. 关系图
![img_2968d865a19ecf34aedabf15245340d7.jpe]()