在进入NIO之前,先回顾一下Java标准IO方式实现的网络server端:
public class IOServerThreadPool {
private static final Logger LOGGER = LoggerFactory.getLogger(IOServerThreadPool.class);
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
ServerSocket serverSocket = null;
try {
serverSocket = new ServerSocket();
serverSocket.bind(new InetSocketAddress(2345));
} catch (IOException ex) {
LOGGER.error("Listen failed", ex);
return;
}
try{
while(true) {
Socket socket = serverSocket.accept();
executorService.submit(() -> {
try{
InputStream inputstream = socket.getInputStream();
LOGGER.info("Received message {}", IOUtils.toString(new InputStreamReader(inputstream)));
} catch (IOException ex) {
LOGGER.error("Read message failed", ex);
}
});
}
} catch(IOException ex) {
try {
serverSocket.close();
} catch (IOException e) {
}
LOGGER.error("Accept connection failed", ex);
}
}
}
这是一个经典的每连接每线程的模型,之所以使用多线程,主要原因在于socket.accept()、socket.read()、socket.write()三个主要函数都是同步阻塞的,当一个连接在处理I/O的时候,系统是阻塞的,如果是单线程的话必然就挂死在那里;但CPU是被释放出来的,开启多线程,就可以让CPU去处理更多的事情。其实这也是所有使用多线程的本质:
- 利用多核。
- 当I/O阻塞系统,但CPU空闲的时候,可以利用多线程使用CPU资源。
现在的多线程一般都使用线程池,可以让线程的创建和回收成本相对较低。在活动连接数不是特别高(小于单机1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的I/O并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。
不过,这个模型最本质的问题在于,严重依赖于线程。但线程是很"贵"的资源,主要表现在:
- 线程的创建和销毁成本很高,在Linux这样的操作系统中,线程本质上就是一个进程。创建和销毁都是重量级的系统函数。
- 线程本身占用较大内存,像Java的线程栈,一般至少分配512K~1M的空间,如果系统中的线程数过千,恐怕整个JVM的内存都会被吃掉一半。
- 线程的切换成本是很高的。操作系统发生线程切换的时候,需要保留线程的上下文,然后执行系统调用。如果线程数过高,可能执行线程切换的时间甚至会大于线程执行的时间,这时候带来的表现往往是系统load偏高、CPU sy使用率特别高(超过20%以上),导致系统几乎陷入不可用的状态。
- 容易造成锯齿状的系统负载。因为系统负载是用活动线程数或CPU核心数,一旦线程数量高但外部网络环境不是很稳定,就很容易造成大量请求的结果同时返回,激活大量阻塞线程从而使系统负载压力过大。
所以,当面对十万甚至百万级连接的时候,传统的BIO模型是无能为力的。随着移动端应用的兴起和各种网络游戏的盛行,百万级长连接日趋普遍,此时,必然需要一种更高效的I/O处理模型。
BIO弱在哪里?
都说NIO更高效,那BIO怎么就弱了呢?弱在哪里呢?现在通过上面BIO方式编写的server一探究竟。
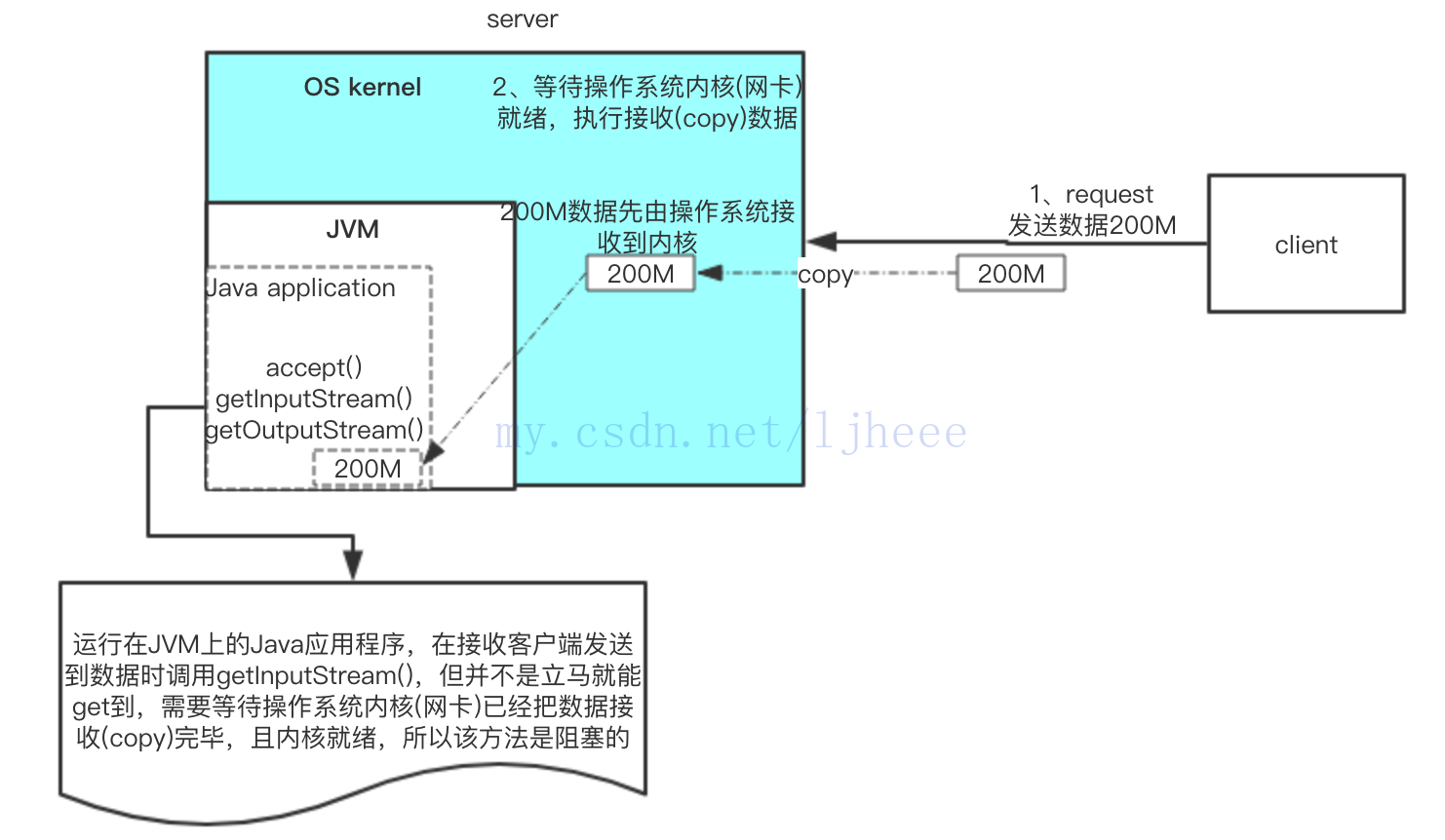
场景:假设客户端在与server建立连接后,请求传输200M数据。
server端运行在某服务器操作系统上,JVM在该服务器操作系统内核(OS kernel)之上,而BIO方式编写的server程序(Java application)则是跑在JVM上。
将经历以下步骤:
1、client请求发送数据
2、server端的Java application并不能直接开始接收数据,而是需要等待 OS kernel 接收网络数据传输的网卡准备就绪,网卡是专门负责网络数据传输的。
3、网卡就绪,执行接收数据到OS kernel,此时数据需要完整地copy到操作系统内核缓冲区中。这是第一次copy数据,传输的时间取决于传输数据的大小和网络带宽。(传输时间=数据大小/带宽)
4、运行在JVM上的Java应用程序,在接收客户端发送到数据时调用getInputStream(),但并不是立马就能get到,需要等待操作系统内核(网卡)已经把数据接收(copy)完毕,且内核准备就绪。
5、内核准备就绪,会通过管道将数据全部复制到JVM中,这一次是将内核缓冲区中的数据copy到JVM中(JVM运行时数据区)。
6、这时数据已全部存在在JVM中,server端应用程序才能通过InputStream将数据传输到Java application业务处理处,此时真正拿到client传来的数据(也就是getInputStream()里面的内容),执行具体的业务逻辑处理。
还需要注意的是:java.io.inputstream 传输数据时,数据必须是完整的。也就是说,上例中传输200M数据,操作系统内核必须全部接收好,一次性给我(JVM)。
看似简单的serverSocket.accept()后,开启子线程,执行socket.getInputStream()拿client传过来的数据,其实经历上面的步骤,Java application需要借助OS kernel 完成2次copy。这也是为什么这种方式通常是一个连接一个线程,2次copy受到网络拥塞、网络波动等因素的影响。
基于事件、通知模型的NIO
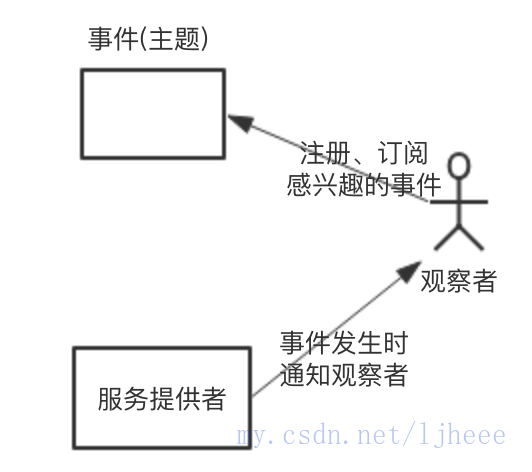
提到事件、通知,大家自然会想到——观察者模式,简单描述如下:
观察者模式中三个组成角色,观察者、被观察者(服务提供者)、观察的主题,也就是事件。观察者首先需要订阅感兴趣的事件,然后当事件发生时,被观察者会进行通知。
基于事件、通知模型的NIO,就是基于此实现的。此实现非常巧妙,观察者是JVM,被观察者是OS kernel 。
JVM作为观察者,它可以向OS kernel 订阅连接事件、数据可读事件、数据可写事件。Java NIO提供了事件池Keys,当订阅的事件发生时,OS kernel 就会通知JVM,并将该事件放入事件池当中,而运行在JVM上的Java application可以用NIO提供的selector从事件池中轮询就绪的消息;轮询到就绪的事件后即可直接执行。
在JVM注册事件后,只需要selector事件池就好了,select到就绪的事件就处理,整个过程就无其他需要阻塞等待执行的地方。通常selector是一个单独的线程。
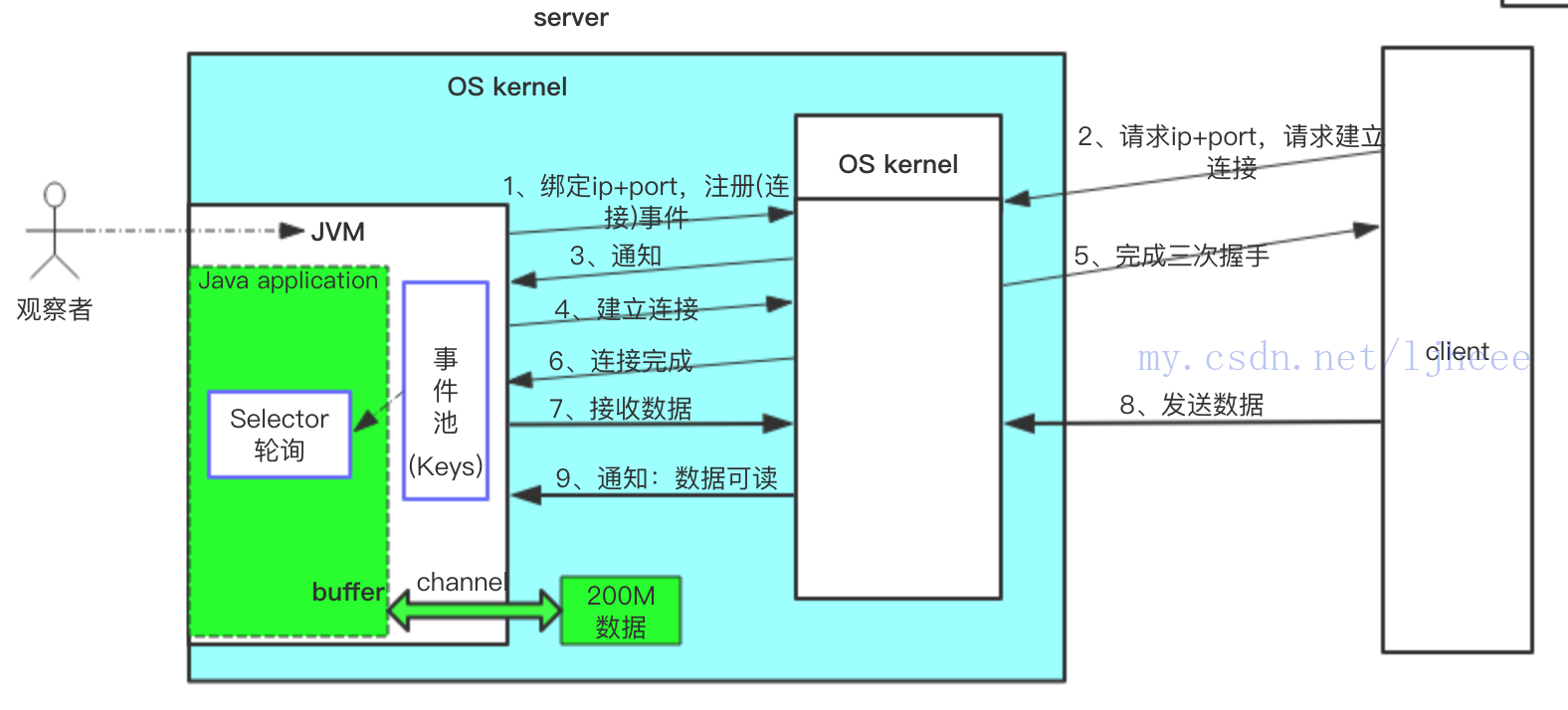
还是以上面传输200M数据的场景,梳理下NIO的工作方式:
1、首先server端需要绑定IP+port,并向OS kernel 注册连接事件,等待客户端的连接请求。
2、client客户端请求server地址,请求建立连接。
3、OS kernel 得知client网络连接请求,并通知JVM,将连接事件放入事件池。操作系统内核OS kernel 有专门负责网络数据传输的网卡,对于即将发生的网络传输事件,操作系统内核会早于JVM得知;可读可写事件也类似。
4、运行在JVM上的Java application,selector线程select到连接事件,server端执行建立连接(ssc.accept())。
5、client完成三次握手。建立连接完成,也有一个对应的事件OP_CONNECT,OS kernel 也会把它放入事件池。
6、Java application的selector线程select到连接完成事件。
7、server端订阅可读事件(准备接收数据),告诉OS kernel 等数据准备好来通知我。
8、client发送200M数据,数据由OS kernel 网卡接收到内核缓冲区。
9、接收完成后,OS kernel 会通知JVM数据准备就绪,将数据可读事件放入事件池。此时数据在内核缓冲区,不在JVM中。
10、Java application的selector线程select到可读事件,通过NIO提供的channel将200M数据(从内核缓冲区)接收到JVM运行时数据区。此时server端接收client发送的数据完毕。
Java application通过NIO提供的channel copy数据,channel有网络套接字/文件Chanel等多种类型,channel是类似于Linux系统里面的管道,是双向通道。在使用channel时,Java application还会用到buffer,buffer也有多种类型。
Tomcat优化配置
Tomcat 默认单机配置下QPS 100-150
QPS150以上 延迟200ms
QPS300以上 延迟500ms 并有丢失连接。
Tomcat 可以配置成nio方式
config/server.xml中 将connector节点的protocol改成protocol="org.apache.coyote.http11.Http11NioProtocol"。
更高效的方式:
APR:通过JNI,用c语言实现的更高效的网络数据交换方式。APR 是tomcat特有的。
AIO:和底层联系更密切,selector都给省略了。
转载请联系原作者
https://www.jianshu.com/u/dd8907cc9fa5