










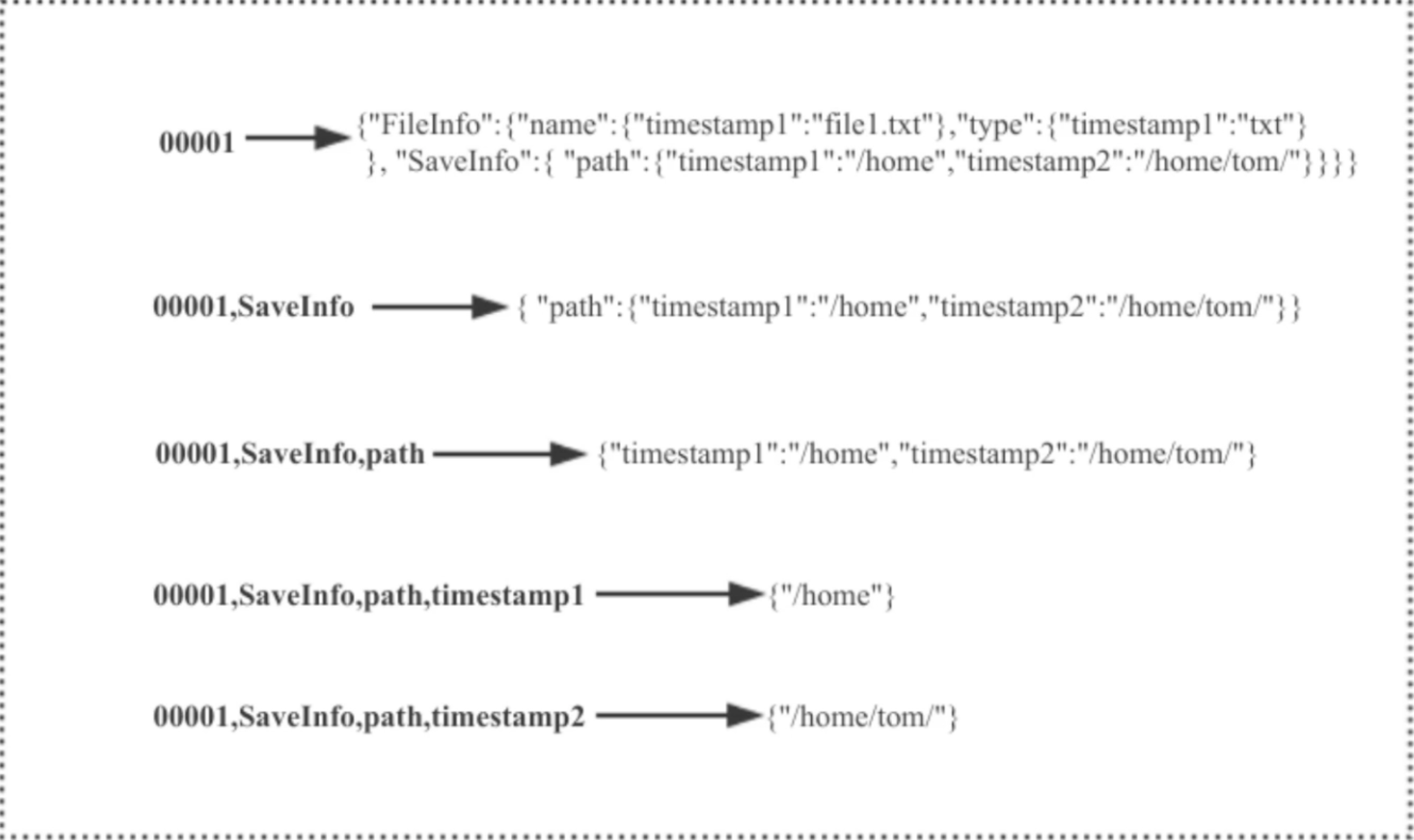




如何用 Python 和 gensim 调用中文词嵌入预训练模型?
利用 Python 和 Spacy 尝试过英文的词嵌入模型后,你是不是很想了解如何对中文词语做向量表达,让机器建模时捕捉更多语义信息呢?这份视频教程,会手把手教你操作。 疑问 写过《如何用Python处理自然语言?(Spacy与Word Embedding)》一文后,不少同学留言或私信询问我,如何用 Spacy 处理中文词语,捕捉更多语义信息。 回顾一下, 利用词嵌入预训练模型,Spacy 可以做许多很酷的事情。 例如计算词语之间的相似程度: 这是“狗”和“猫”的相似度: dog.similarity(cat) 0.80168545 这是“狗”和“橘子”的相似度: dog.similarity(orange) 0.2742508 还可以利用特征语义,计算结果。 例如做个完形填空: ? - woman = king - queen 你一眼就看出来了,应该填写“man”(男人),对吧? 把式子变换一下: guess_word = king - queen + woman 输入右侧词序列: words = ["king", "queen", "woman"] 执行对比函数后,你会看到如下结果...