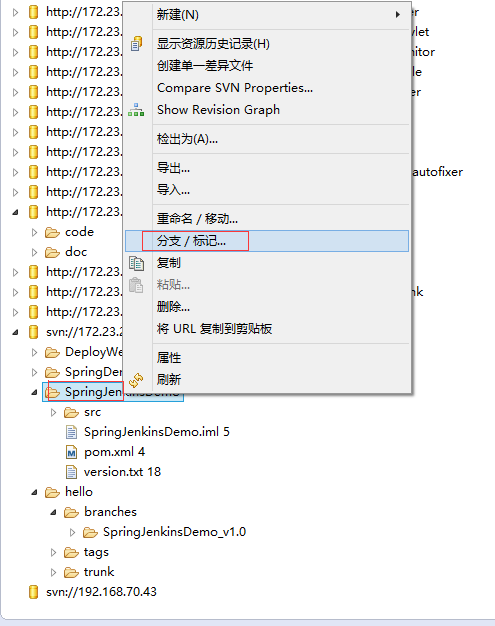

Apache Spark 内存管理详解
Apache Spark 内存管理详解 Spark 作为一个基于内存的分布式计算引擎,其内存管理模块在整个系统中扮演着非常重要的角色。理解 Spark 内存管理的基本原理,有助于更好地开发 Spark 应用程序和进行性能调优。本文旨在梳理出 Spark 内存管理的脉络,抛砖引玉,引出读者对这个话题的深入探讨。本文中阐述的原理基于 Spark 2.1 版本,阅读本文需要读者有一定的 Spark 和 Java 基础,了解 RDD、Shuffle、JVM 等相关概念。 在执行 Spark 的应用程序时,Spark 集群会启动 Driver 和 Executor 两种 JVM 进程,前者为主控进程,负责创建 Spark 上下文,提交 Spark 作业(Job),并将作业转化为计算任务(Task),在各个 Executor 进程间协调任务的调度,后者负责在工作节点上执行具体的计算任务,并将结果返回给 Driver,同时为需要持久化的 RDD 提供存储功能[1]。由于 Driver 的内存管理相对来说较为简单,本文主要对 Executor 的内存管理进行分析,下文中的 Spark 内存均特指 Ex...