













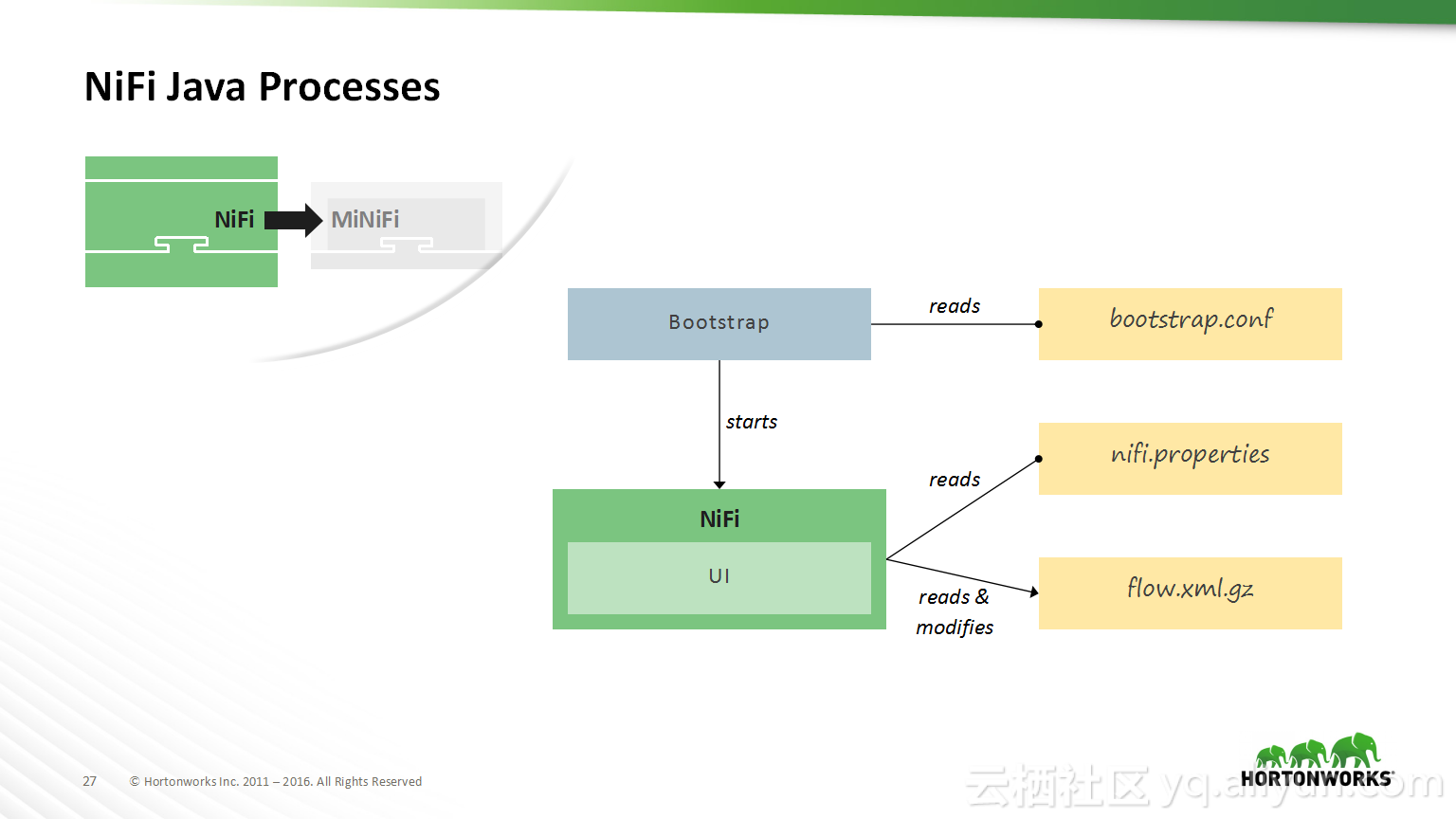
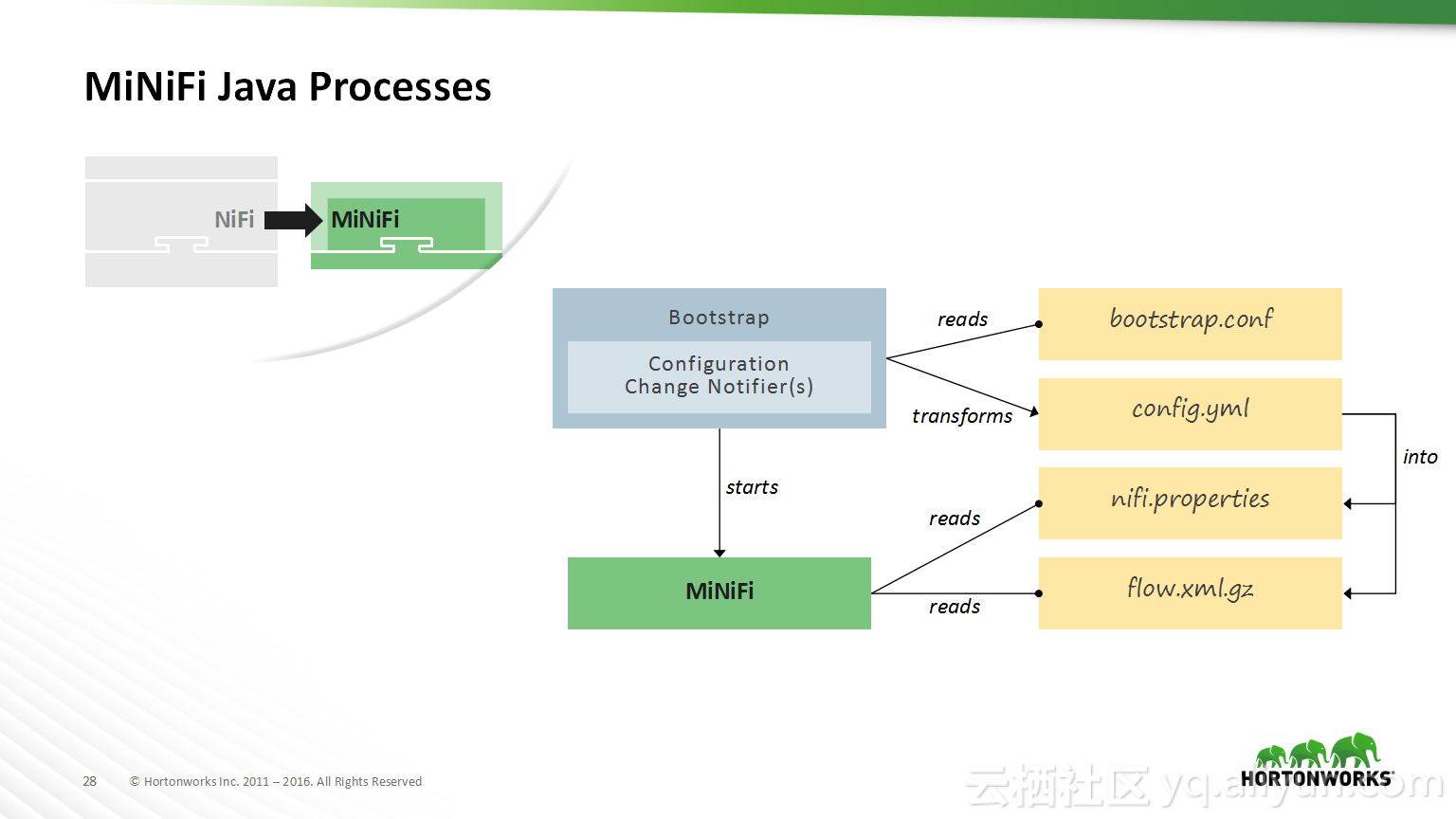

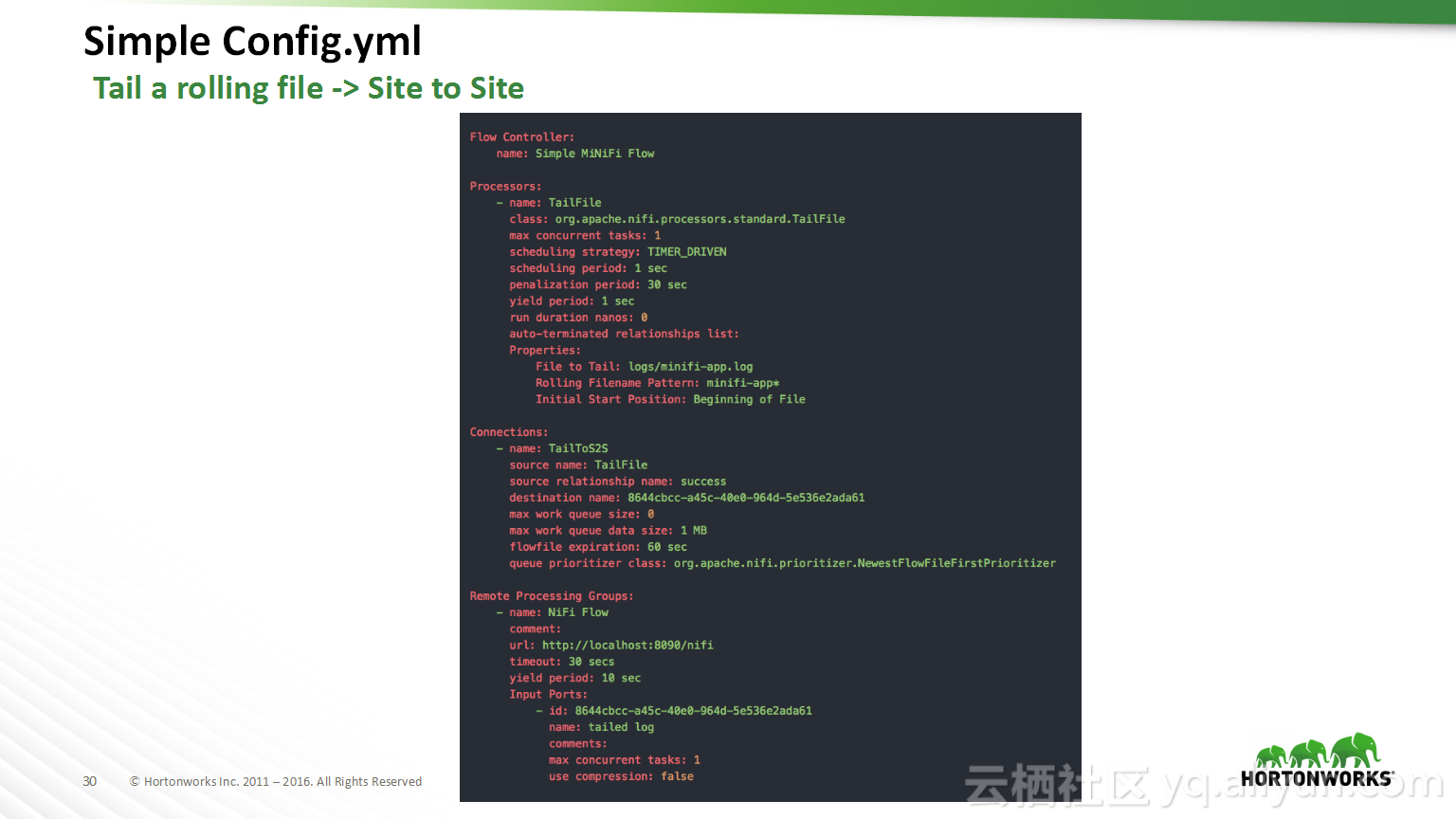

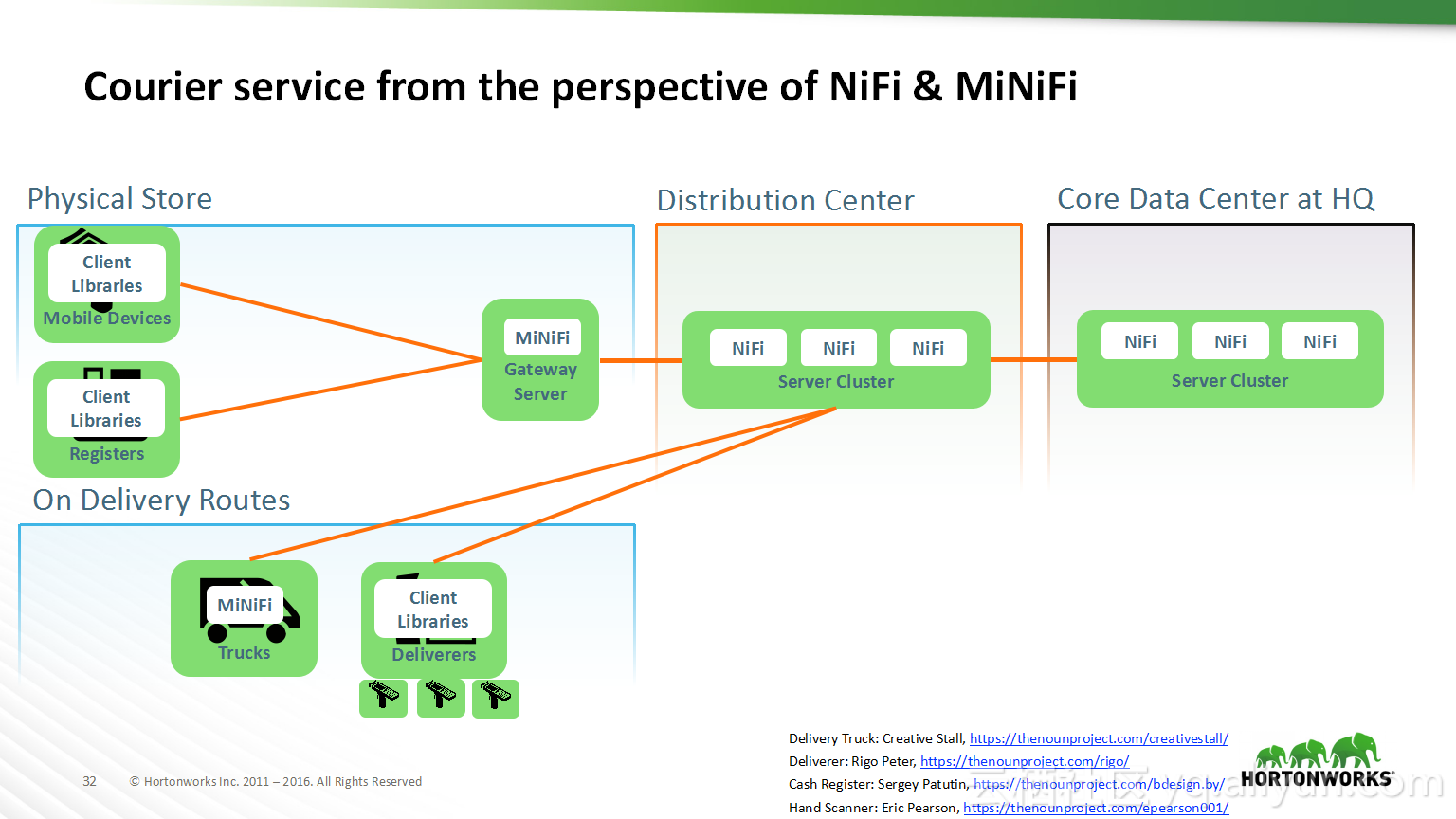



Spark结合源码解决数据倾斜造成Too Large Frame
新公司遇到的第一个spark的坑,寻找原因的过程其实还挺有意思,最终在源码和spark ui上的统计数据的帮助下找到根源,具体如下。 先说下问题 由于严重的数据倾斜,大量数据集中在单个task中,导致shuffle过程中发生异常 完整的exeception是这样的 但奇怪的是,经过尝试减小executor数量后任务反而成功,增大反而失败,经过多次测试,问题稳定复现。 成功的executor数量是7,失败的则是15,集群的active node是7 这结果直接改变了认知,也没爆内存,cpu也够,怎么会这样,executor数量应该越多越快啊,居然还失败了。 解决过程 这个数在几个失败里不一样,但是都超过了Integer.MaxValue。在spark源码中,这条异常发生在TransportFrameDecoder这个类中 检查发现是frame的大小超过了MAX_FRAME_SIZE,而MAX_FRAME_SIZE的大小定义如下 这个TransportFrameDecoder继承自ChannelInboundHandlerAdapter,这是Netty里的类,好了,看到这就明白了,原来错误...