版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/SunnyYoona/article/details/53163460
Sqoop的本质还是一个命令行工具,和HDFS,MapReduce相比,并没有什么高深的理论。
我们可以通过sqoop help命令来查看sqoop的命令选项,如下:
16/11/13 20:10:17 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6usage: sqoop COMMAND [ARGS]Available commands: codegen Generate code to interact with database records create-hive-table Import a table definition into Hive eval Evaluate a SQL statement and display the results export Export an HDFS directory to a database table help List available commands import Import a table from a database to HDFS import-all-tables Import tables from a database to HDFS import-mainframe Import datasets from a mainframe server to HDFS job Work with saved jobs list-databases List available databases on a server list-tables List available tables in a database merge Merge results of incremental imports metastore Run a standalone Sqoop metastore version Display version informationSee 'sqoop help COMMAND' for information on a specific command.
其中使用频率最高的选项还是import 和 export 选项。
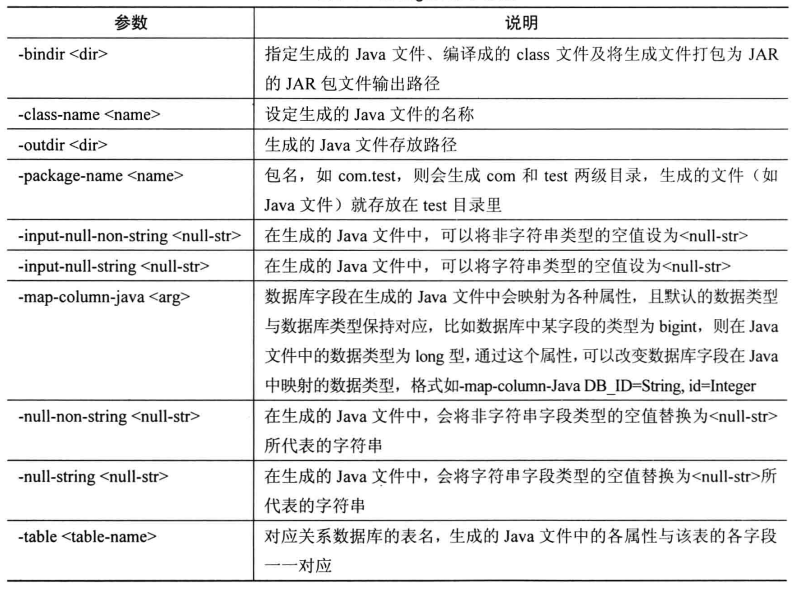
1. codegen
将关系型数据库表的记录映射为一个Java文件,Java class类以及相关的jar包,该命令将数据库表的记录映射为一个Java文件,在该Java文件中对应有表的各个字段。生成的jar和class文件在Metastore功能使用时会用到。该命令选项的参数如下图所示:
![]()
举例:
sqoop codegen --connect jdbc:mysql://localhost:3306/test --table order_info -outdir /home/xiaosi/test/ --username root -password root
上面实例以test数据库的order_info表来生成Java代码,其中-outdir指定了Java代码生成的路径
运行结果信息如下:
16/11/13 21:50:34 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6Enter password: 16/11/13 21:50:38 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.16/11/13 21:50:38 INFO tool.CodeGenTool: Beginning code generation16/11/13 21:50:38 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `order_info` AS t LIMIT 116/11/13 21:50:38 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `order_info` AS t LIMIT 116/11/13 21:50:38 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /opt/hadoop-2.7.2注: /tmp/sqoop-xiaosi/compile/ea41fe40e1f12f6b052ad9fe4a5d9710/order_info.java使用或覆盖了已过时的 API。注: 有关详细信息, 请使用 -Xlint:deprecation 重新编译。16/11/13 21:50:39 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-xiaosi/compile/ea41fe40e1f12f6b052ad9fe4a5d9710/order_info.jar
我们还可以使用-bindir指定编译成的class文件以及将生成文件打包为jar的jar包文件输出路径:
16/11/13 21:53:55 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6Enter password: 16/11/13 21:53:58 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.16/11/13 21:53:58 INFO tool.CodeGenTool: Beginning code generation16/11/13 21:53:58 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `order_info` AS t LIMIT 116/11/13 21:53:58 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `order_info` AS t LIMIT 116/11/13 21:53:58 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /opt/hadoop-2.7.2注: /home/xiaosi/data/order_info.java使用或覆盖了已过时的 API。注: 有关详细信息, 请使用 -Xlint:deprecation 重新编译。16/11/13 21:53:59 INFO orm.CompilationManager: Writing jar file: /home/xiaosi/data/order_info.jar
上面实例指定编译成的class文件(order_info.class)以及将生成文件打包为jar的jar包文件(order_info.jar)输出路径为/home/xiaosi/data路径,java文件(order_info.java)路径为/home/xiaosi/test
2. create-hive-table
这个命令上一篇文章[Sqoop导入与导出]中已经使用过了,作用就是生成与关系数据库表的表结构对应的Hive表。该命令选项的参数如下图所示:
![]()
举例:
sqoop create-hive-table --connect jdbc:mysql://localhost:3306/test --table employee --username root -password root --fields-terminated-by ','
3. eval
eval命令选项可以让Sqoop使用SQL语句对关系性数据库进行操作,在使用import这种工具进行数据导入的时候,可以预先了解相关的SQL语句是否正确,并能将结果显示在控制台。
3.1 选择查询评估计算
使用eval工具,我们可以评估计算任何类型的SQL查询。我们以test数据库的order_info表为例子:
sqoop eval --connect jdbc:mysql://localhost:3306/test --username root --query "select * from order_info limit 3" -P
运行结果信息:
16/11/13 22:25:19 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6Enter password: 16/11/13 22:25:22 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.------------------------------------------------------------| id | order_time | business | ------------------------------------------------------------| 358574046793404 | 2016-04-05 | flight | | 358574046794733 | 2016-08-03 | hotel | | 358574050631177 | 2016-05-08 | vacation | ------------------------------------------------------------
3.2 插入评估计算
Sqoop的eval工具可以适用于两个模拟和定义的SQL语句。这意味着,我们可以使用eval的INSERT语句了。下面的命令用于在test数据库的order_info表中插入新行:
sqoop eval --connect jdbc:mysql://localhost:3306/test --username root --query "insert into order_info (id, order_time, business) values('358574050631166', '2016-11-13', 'hotel')" -P
运行结果信息输出:
16/11/13 22:29:42 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6Enter password: 16/11/13 22:29:44 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.16/11/13 22:29:44 INFO tool.EvalSqlTool: 1 row(s) updated.
如果命令成功执行,会在控制台上显示更新的行的状态。
或者我们可以在mysql中查询我们刚插入的那条信息:
mysql> select * from order_info where id = "358574050631166";+-----------------+------------+----------+| id | order_time | business |+-----------------+------------+----------+| 358574050631166 | 2016-11-13 | hotel |+-----------------+------------+----------+1 row in set (0.00 sec)
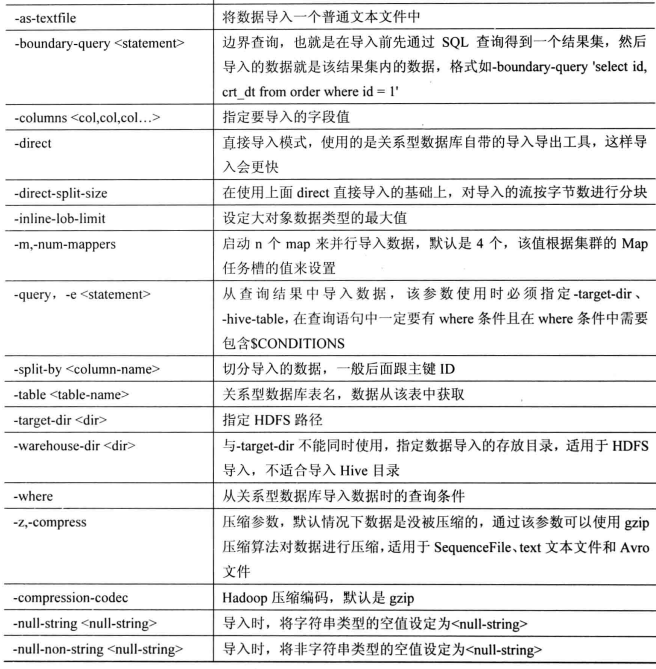
4. export
从HDFS中将数据导出到关系性数据库中。该命令选项的参数如下图所示:
![]()
![]()
举例:
在HDFS文件中的员工数据的一个例子,数据如下:
hadoop fs -text /user/xiaosi/employee/* | lessyoona,qunar,创新事业部xiaosi,qunar,创新事业部jim,ali,淘宝kom,ali,淘宝lucy,baidu,搜索jim,ali,淘宝
在将HDFS中数据导出到关系性数据库时,必须在关系性数据库中新建一张来接受数据的表,如下:
CREATE TABLE `employee` ( `name` varchar(255) DEFAULT NULL, `company` varchar(255) DEFAULT NULL, `depart` varchar(255) DEFAULT NULL);
下面执行导出操作,命令如下:
sqoop export --connect jdbc:mysql://localhost:3306/test --table employee --export-dir /user/xiaosi/employee --username root -m 1 --fields-terminated-by ',' -P
运行结果信息输出:
16/11/13 23:40:49 INFO mapreduce.Job: The url to track the job: http://localhost:8080/16/11/13 23:40:49 INFO mapreduce.Job: Running job: job_local611430785_000116/11/13 23:40:49 INFO mapred.LocalJobRunner: OutputCommitter set in config null16/11/13 23:40:49 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.sqoop.mapreduce.NullOutputCommitter16/11/13 23:40:49 INFO mapred.LocalJobRunner: Waiting for map tasks16/11/13 23:40:49 INFO mapred.LocalJobRunner: Starting task: attempt_local611430785_0001_m_000000_016/11/13 23:40:49 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]16/11/13 23:40:49 INFO mapred.MapTask: Processing split: Paths:/user/xiaosi/employee/part-m-00000:0+12016/11/13 23:40:49 INFO Configuration.deprecation: map.input.file is deprecated. Instead, use mapreduce.map.input.file16/11/13 23:40:49 INFO Configuration.deprecation: map.input.start is deprecated. Instead, use mapreduce.map.input.start16/11/13 23:40:49 INFO Configuration.deprecation: map.input.length is deprecated. Instead, use mapreduce.map.input.length16/11/13 23:40:49 INFO mapreduce.AutoProgressMapper: Auto-progress thread is finished. keepGoing=false16/11/13 23:40:49 INFO mapred.LocalJobRunner: 16/11/13 23:40:49 INFO mapred.Task: Task:attempt_local611430785_0001_m_000000_0 is done. And is in the process of committing16/11/13 23:40:49 INFO mapred.LocalJobRunner: map16/11/13 23:40:49 INFO mapred.Task: Task 'attempt_local611430785_0001_m_000000_0' done.16/11/13 23:40:49 INFO mapred.LocalJobRunner: Finishing task: attempt_local611430785_0001_m_000000_016/11/13 23:40:49 INFO mapred.LocalJobRunner: map task executor complete.16/11/13 23:40:50 INFO mapreduce.Job: Job job_local611430785_0001 running in uber mode : false16/11/13 23:40:50 INFO mapreduce.Job: map 100% reduce 0%16/11/13 23:40:50 INFO mapreduce.Job: Job job_local611430785_0001 completed successfully16/11/13 23:40:50 INFO mapreduce.Job: Counters: 20 File System Counters FILE: Number of bytes read=22247825 FILE: Number of bytes written=22732498 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=126 HDFS: Number of bytes written=0 HDFS: Number of read operations=12 HDFS: Number of large read operations=0 HDFS: Number of write operations=0 Map-Reduce Framework Map input records=6 Map output records=6 Input split bytes=136 Spilled Records=0 Failed Shuffles=0 Merged Map outputs=0 GC time elapsed (ms)=0 Total committed heap usage (bytes)=245366784 File Input Format Counters Bytes Read=0 File Output Format Counters Bytes Written=016/11/13 23:40:50 INFO mapreduce.ExportJobBase: Transferred 126 bytes in 2.3492 seconds (53.6344 bytes/sec)16/11/13 23:40:50 INFO mapreduce.ExportJobBase: Exported 6 records.
导出完毕之后,我们可以在mysql中通过employee表进行查询:
mysql> select name, company from employee;+--------+---------+| name | company |+--------+---------+| yoona | qunar || xiaosi | qunar || jim | ali || kom | ali || lucy | baidu || jim | ali |+--------+---------+6 rows in set (0.00 sec)
5. import
将数据表中的数据导入HDFS或者Hive中,该命令选项的参数如下图所示:
![]()
![]()
举例:
sqoop import --connect jdbc:mysql://localhost:3306/test --target-dir /user/xiaosi/data/order_info --query 'select * from order_info where $CONDITIONS' -m 1 --username root -P
如上代码从查询结果中导入数据到HDFS中,存储路径由--target-dir参数指定。这里,使用了--query选项,不能同时与--table选项使用。同时,变量$CONDITIONS必须在WHERE语句之后,供Sqoop进程运行命令过程中使用。
运行结果信息如下:
16/11/14 12:08:50 INFO mapreduce.Job: The url to track the job: http://localhost:8080/16/11/14 12:08:50 INFO mapreduce.Job: Running job: job_local127577466_000116/11/14 12:08:50 INFO mapred.LocalJobRunner: OutputCommitter set in config null16/11/14 12:08:50 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 116/11/14 12:08:50 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter16/11/14 12:08:50 INFO mapred.LocalJobRunner: Waiting for map tasks16/11/14 12:08:50 INFO mapred.LocalJobRunner: Starting task: attempt_local127577466_0001_m_000000_016/11/14 12:08:50 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 116/11/14 12:08:50 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]16/11/14 12:08:50 INFO db.DBInputFormat: Using read commited transaction isolation16/11/14 12:08:50 INFO mapred.MapTask: Processing split: 1=1 AND 1=116/11/14 12:08:50 INFO db.DBRecordReader: Working on split: 1=1 AND 1=116/11/14 12:08:50 INFO db.DBRecordReader: Executing query: select * from order_info where ( 1=1 ) AND ( 1=1 )16/11/14 12:08:50 INFO mapreduce.AutoProgressMapper: Auto-progress thread is finished. keepGoing=false16/11/14 12:08:50 INFO mapred.LocalJobRunner: 16/11/14 12:08:51 INFO mapred.Task: Task:attempt_local127577466_0001_m_000000_0 is done. And is in the process of committing16/11/14 12:08:51 INFO mapred.LocalJobRunner: 16/11/14 12:08:51 INFO mapred.Task: Task attempt_local127577466_0001_m_000000_0 is allowed to commit now16/11/14 12:08:51 INFO output.FileOutputCommitter: Saved output of task 'attempt_local127577466_0001_m_000000_0' to hdfs://localhost:9000/user/xiaosi/data/order_info/_temporary/0/task_local127577466_0001_m_00000016/11/14 12:08:51 INFO mapred.LocalJobRunner: map16/11/14 12:08:51 INFO mapred.Task: Task 'attempt_local127577466_0001_m_000000_0' done.16/11/14 12:08:51 INFO mapred.LocalJobRunner: Finishing task: attempt_local127577466_0001_m_000000_016/11/14 12:08:51 INFO mapred.LocalJobRunner: map task executor complete.16/11/14 12:08:51 INFO mapreduce.Job: Job job_local127577466_0001 running in uber mode : false16/11/14 12:08:51 INFO mapreduce.Job: map 100% reduce 0%16/11/14 12:08:51 INFO mapreduce.Job: Job job_local127577466_0001 completed successfully16/11/14 12:08:51 INFO mapreduce.Job: Counters: 20 File System Counters FILE: Number of bytes read=22247784 FILE: Number of bytes written=22732836 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=0 HDFS: Number of bytes written=3710 HDFS: Number of read operations=4 HDFS: Number of large read operations=0 HDFS: Number of write operations=3 Map-Reduce Framework Map input records=111 Map output records=111 Input split bytes=87 Spilled Records=0 Failed Shuffles=0 Merged Map outputs=0 GC time elapsed (ms)=0 Total committed heap usage (bytes)=245366784 File Input Format Counters Bytes Read=0 File Output Format Counters Bytes Written=371016/11/14 12:08:51 INFO mapreduce.ImportJobBase: Transferred 3.623 KB in 2.5726 seconds (1.4083 KB/sec)16/11/14 12:08:51 INFO mapreduce.ImportJobBase: Retrieved 111 records.
我们可以查看HDFS由参数--target-dir指定的路径查看导入的数据:
hadoop fs -text /user/xiaosi/data/order_info/* | less358574046793404,2016-04-05,flight358574046794733,2016-08-03,hotel358574050631177,2016-05-08,vacation358574050634213,2015-04-28,train358574050634692,2016-04-05,tuan358574050650524,2015-07-26,hotel358574050654773,2015-01-23,flight358574050668658,2015-01-23,hotel358574050730771,2016-11-06,train358574050731241,2016-05-08,car358574050743865,2015-01-23,vacation358574050767666,2015-04-28,train358574050767971,2015-07-26,flight358574050808288,2016-05-08,hotel358574050816828,2015-01-23,hotel358574050818220,2015-04-28,car358574050821877,2013-08-03,flight
再看一个例子:
sqoop import --connect jdbc:mysql://localhost:3306/test --table order_info --columns "business,id,order_time" -m 1 --username root -P
HDFS上会在/user/xiaosi/目录下新增一个目录order_info,与关系性数据库的表名一致,内容如下:
flight,358574046793404,2016-04-05hotel,358574046794733,2016-08-03vacation,358574050631177,2016-05-08train,358574050634213,2015-04-28tuan,358574050634692,2016-04-05
6. import-all-tables
将数据库里的所有表导入HDFS中,每个表在HDFS中对应一个独立的目录。该命令选项的参数如下图所示:
![]()
7. list-databases
该命令选项可以列出关系性数据库的所有数据库名,命令如下:
sqoop list-databases --connect jdbc:mysql://localhost:3306 --username root -P
运行结果信息如下:
16/11/14 14:30:11 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6Enter password: 16/11/14 14:30:14 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.information_schemahive_dbmysqlperformance_schemaphpmyadmintest
8. list-tables
该命令选项可以列出关系性数据库的某一个数据库的所有表名,命令如下:
sqoop list-tables --connect jdbc:mysql://localhost:3306/test --username root -P
运行结果信息如下:
16/11/14 14:32:08 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6Enter password: 16/11/14 14:32:10 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.PageViewbookbookIDcccity_clickcountrycountry2cupemployeeflightOrderhotel_book_infohotel_infoorder_infostustu2stu3stuInfostudent
9. merge
该命令选项的作用是将HDFS上的两份数据进行合并,在合并的同时进行数据去重。该命令选项的参数如下图所示:
![]()
![]()
例如,在HDFS的路径/user/xiaosi/old下由一份导入数据,如下:
id name1 a2 b3 c
在HDFS的路径/user/xiaosi/new下也有一份数据,但是在导入时间在第一份之后,如下:
id name1 a22 b3 c
那么合并的结果为:
id name1 a22 b3 c
运行如下命令:
sqoop merge -new-data /user/xiaosi/new/part-m-00000 -onto /user/xiaosi/old/part-m-00000 -target-dir /user/xiaosi/final -jar-file /home/xiaosi/test/testmerge.jar -class-name testmerge -merge-key id
备注:
在一份数据集中,多行不应具有相同的主键,否则会发生数据丢失。
10. metastore
记录Sqoop作业的元数据信息,如果不启动Metastore实例,则默认的元数据存储目录为~/.sqoop。如果要更改存储目录,可以在配置文件sqoop-site.xml中进行更改。
启动Metastore实例:
sqoop metastore
运行结果信息如下:
16/11/14 14:44:40 INFO sqoop.Sqoop: Running Sqoop version: 1.4.616/11/14 14:44:40 WARN hsqldb.HsqldbMetaStore: The location for metastore data has not been explicitly set. Placing shared metastore files in /home/xiaosi/.sqoop/shared-metastore.db[Server@52308be6]: [Thread[main,5,main]]: checkRunning(false) entered[Server@52308be6]: [Thread[main,5,main]]: checkRunning(false) exited[Server@52308be6]: [Thread[main,5,main]]: setDatabasePath(0,file:/home/xiaosi/.sqoop/shared-metastore.db)[Server@52308be6]: [Thread[main,5,main]]: checkRunning(false) entered[Server@52308be6]: [Thread[main,5,main]]: checkRunning(false) exited[Server@52308be6]: [Thread[main,5,main]]: setDatabaseName(0,sqoop)[Server@52308be6]: [Thread[main,5,main]]: putPropertiesFromString(): [hsqldb.write_delay=false][Server@52308be6]: [Thread[main,5,main]]: checkRunning(false) entered[Server@52308be6]: [Thread[main,5,main]]: checkRunning(false) exited[Server@52308be6]: Initiating startup sequence...[Server@52308be6]: Server socket opened successfully in 3 ms.[Server@52308be6]: Database [index=0, id=0, db=file:/home/xiaosi/.sqoop/shared-metastore.db, alias=sqoop] opened sucessfully in 153 ms.[Server@52308be6]: Startup sequence completed in 157 ms.[Server@52308be6]: 2016-11-14 14:44:40.414 HSQLDB server 1.8.0 is online[Server@52308be6]: To close normally, connect and execute SHUTDOWN SQL[Server@52308be6]: From command line, use [Ctrl]+[C] to abort abruptly16/11/14 14:44:40 INFO hsqldb.HsqldbMetaStore: Server started on port 16000 with protocol HSQL
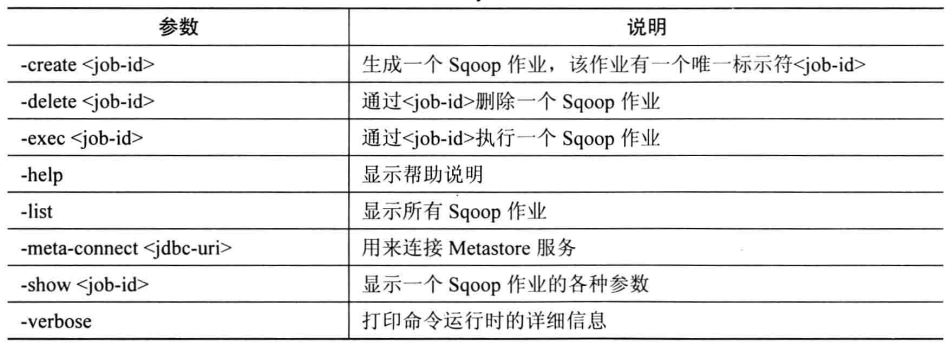
11. job
该命令选项可以生产一个Sqoop的作业,但是不会立即执行,需要手动执行,该命令选项目的在于尽可能的服用Sqoop命令。该命令选项的参数如下图所示:
![]()
举例:
sqoop job -create listTablesJob -- list-tables --connect jdbc:mysql://localhost:3306/test --username root -P
上面代码实现一个job,显示关系性数据库test数据库中所有的表。
sqoop job -exec listTablesJob
上面代码执行我们已经定义好的Job,输出结果信息如下:
16/11/14 19:51:44 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6Enter password: 16/11/14 19:51:47 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.PageViewbookbookIDcccity_clickcountrycountry2cupemployeeflightOrderhotel_book_infohotel_infoorder_infostustu2stu3stuInfostudent
备注:
-- 和 list-tables(Job 所要执行的Sqoop命令) 不能挨着。
来自于《Hadoop海量数据处理 技术详解与项目实战》