我遇到的问题其实是自己的业务代码的bug导致shuffle时发生了倾斜,groupby操作时大量的key映射到了同一台机器。
我自己的bug没有多少参考价值,因为是一个弱智bug,但是由于之前没有这方面的经验,看了日志也不懂发生了什么,在群里请教了木艮同学和Jepson同学, 终于找到了问题。稍微写一下发生数据倾斜时的一些日志和监控图表吧,权当参考。
问题现象
- 任务日志显示某节点内存超过yarn的限制:xx G,被yarn杀掉。
-
打开webui(:4040/jobs),打开executor列表,会显示只有一个worker在工作,
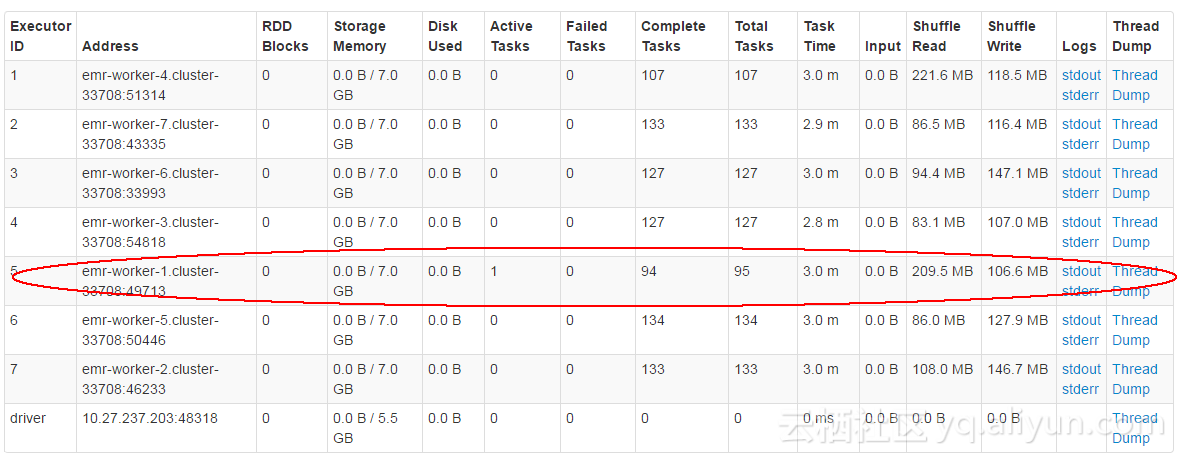
对应的报错节点的日志:
16/10/31 11:10:18 INFO storage.MemoryStore: Block broadcast_14 stored as values in memory (estimated size 337.4 KB, free 13.2 MB)
16/10/31 11:12:44 ERROR executor.Executor: Managed memory leak detected; size = 5924550044 bytes, TID = 423
16/10/31 11:12:44 ERROR executor.Executor: Exception in task 0.0 in stage 13.0 (TID 423)
java.lang.OutOfMemoryError: Java heap space
at org.apache.spark.util.collection.AppendOnlyMap.growTable(AppendOnlyMap.scala:218)
at org.apache.spark.util.collection.SizeTrackingAppendOnlyMap.growTable(SizeTrackingAppendOnlyMap.scala:38)
at org.apache.spark.util.collection.AppendOnlyMap.incrementSize(AppendOnlyMap.scala:204)
at org.apache.spark.util.collection.AppendOnlyMap.changeValue(AppendOnlyMap.scala:151)
at org.apache.spark.util.collection.SizeTrackingAppendOnlyMap.changeValue(SizeTrackingAppendOnlyMap.scala:32)
at org.apache.spark.util.collection.ExternalSorter.insertAll(ExternalSorter.scala:192)
at org.apache.spark.shuffle.sort.SortShuffleWriter.write(SortShuffleWriter.scala:64)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:73)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:41)
at org.apache.spark.scheduler.Task.run(Task.scala:89)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:214)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
16/10/31 11:12:46 ERROR util.SparkUncaughtExceptionHandler: Uncaught exception in thread Thread[Executor task launch worker-0,5,main]
java.lang.OutOfMemoryError: Java heap space
at org.apache.spark.util.collection.AppendOnlyMap.growTable(AppendOnlyMap.scala:218)
at org.apache.spark.util.collection.SizeTrackingAppendOnlyMap.growTable(SizeTrackingAppendOnlyMap.scala:38)
at org.apache.spark.util.collection.AppendOnlyMap.incrementSize(AppendOnlyMap.scala:204)
at org.apache.spark.util.collection.AppendOnlyMap
- 下图是阿里云集群监控图表中的cpu曲线,黑色的曲线是其中一台worker,靠前的两次100%就是两次问题任务执行,红色的是修改了部分问题之后重新跑了一遍,还是有部分倾斜,但是成功跑完了。最后一段是正常曲线。(因为集群已经关了,没法看大图了。。)

- 下图是对应的内存曲线

可以看到,可能是webui的显示问题,shuffle read只显示200M+的数据量,实际内存使用已经超6G了,开始的时候没想到是这个问题。木艮同学指出日志出错是在shuffle阶段,应该是数据倾斜问题,Jepson同学说数据实际占有内存比数据大小大很多,于是我大概知道了可能出错的地方,排查了一下这个stage对应的DAG里带shuffle的transformation操作,才发现了bug。
我的问题是比较弱智的bug,加了一些数据源,新写了处理代码;然后新的任务改了,之前的任务代码忘记改了,导致新的数据没有设置key,全部group到一个地方去了。


