1.概述
Apache Kylin是一个开源的分布式分析引擎,提供SQL接口并且用于OLAP业务于Hadoop的大数据集上,该项目由eBay贡献于Apache。
2.What is Kylin
在使用一种模型,我们得知道她是干什么的,那么首先来看看Kylin的特性,其内容如下所示:
- 可扩展超快的OLAP引擎:Kylin是为减少在Hadoop上百亿级别数据查询延迟而设计的。
- Hadoop ANSI SQL接口:Kylin为Hadoop提供标准的SQL,其支持大部分查询功能。
- 出色的交互式查询能力:通过Kylin,使用者可以于Hadoop数据进行亚秒级交互,在同样的数据集上提供比Hive更好的性能。
- 多维度Cube:用户能够在Kylin里为百亿以上的数据集定义数据模型并构建Cube。
- 和BI工具无缝整合:Kylin提供与BI工具,如商业化的Tableau。另外,根据官方提供的信息也在后续逐步提供对其他工具的支持。
- 其他特性:
- 对Job的管理和监控
- 压缩和编码的支持
- 增量更新Cube
- 利用HBase Coprocessor去查询
- 基于HyperLogLog的Distinct Count近似算法
- 友好的Web界面用于管理、监控和使用Cube
- 项目及Cube级别的访问控制安全
- 支持LDAP
3.ECOSYSTEM
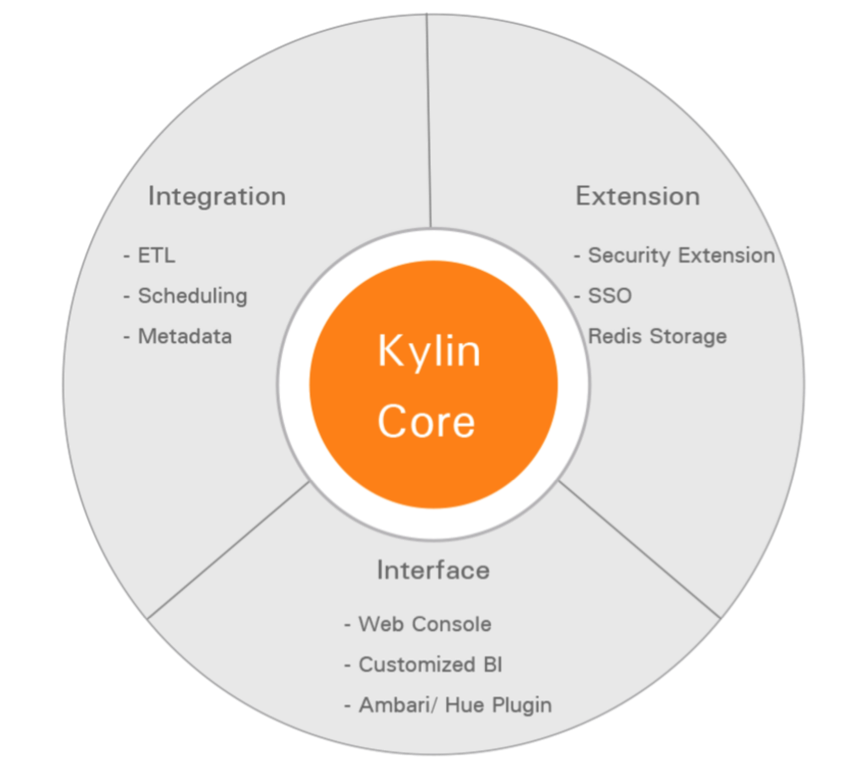
Kylin有其自己的生态圈,如下图所示:
![]()
从上图中,我们可以看到,Kylin的核心包含:Kylin OLAP引擎基础框架,Metadata引擎,查询引擎,Job引擎以及存储引擎等等,同时还包括REST服务器以响应客户端请求。另外,还扩展支持额外 功能和特性的插件,同时整合与调度系统、ETL、监控等生命周期管理系统。在Kylin核心之上扩展的第三方用户界面,ODBC和JDBC驱动用以支持不 同的工具和产品,如:Tableau。
4.Architecture
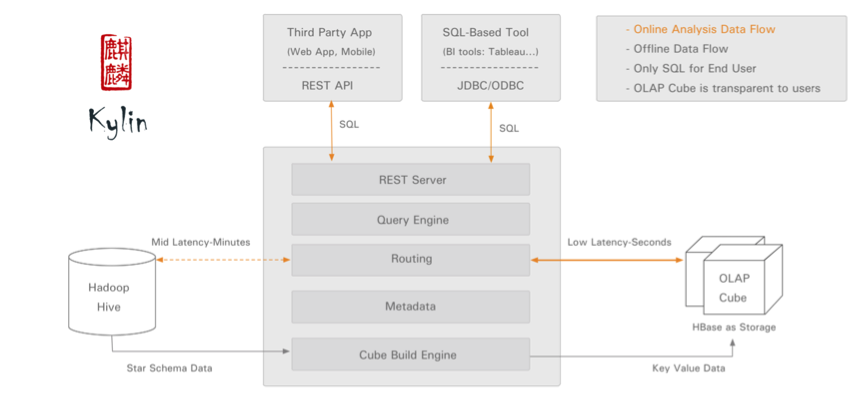
Kylin的架构概述图如下所示:
![]()
图中的执行流程很清楚,客户端(REST API或JDBC/ODBC)发送SQL请求,将其交给Kylin的执行引擎去处理,Kylin去拉去对应的数据来做处理,并返回处理结果,这里 Kylin需要依赖HBase。复杂的事情,Kylin的引擎都给我们处理了,我们只需要负责去编写我们的业务SQL。
5.How TO Works
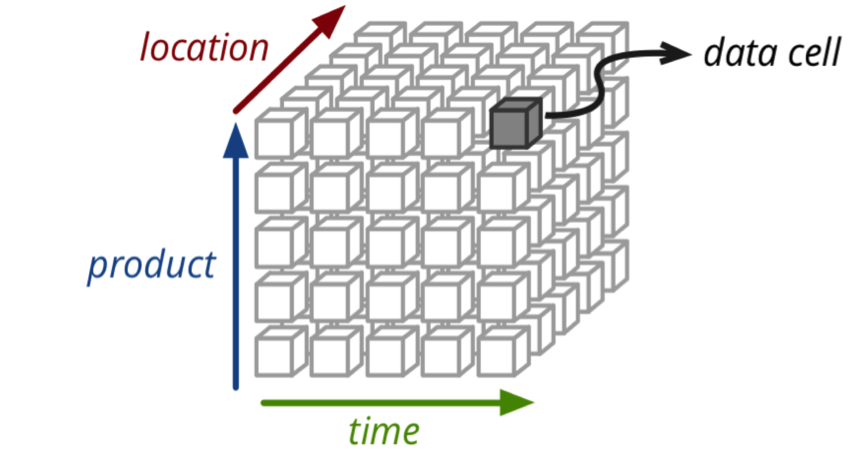
在Kylin中,我们可以处理三维的业务查询,如下图所示:
![]()
在明白了业务处理方向,其生态群和架构。我们要如何去集成该系统到Hadoop集群?关于Kylin的集成过程是比较方便的,Kylin需要Hadoop、Hive、HBase、JDK,另外,对版本也是有要求的。本版要求如下:
- Hadoop:2.4 - 2.7
- Hive:0.13 - 0.14
- HBase:0.98(这里若是选择Kylin-1.2,需要用到HBase-1.1+以上)
- JDK1.7+
另外,安装Kylin步骤也是比较简单的,步骤如下所示:
- 下载最新的安装包,地址如下:[Kylin.tar.gz]
- 设置KYLIN_HOME环境变量
- 确保用户有权限去访问Hadoop、Hive和HBase,如果不确定的话,我们可以在安装包的bin目录下运行check-env.sh脚本,如果我们有问题的话,她会打印详细的信息。
- 最后,我们可以通过kylin.sh start去启动Kylin,或者使用kylin.sh stop去停止Kylin
在Kylin启动之后,我们可以通过输入http://node_hostname:7070/kylin去访问Kylin,登录默认用户名和密码为:ADMIN/KYLIN
预览截图如下所示:
![]()
另外,我们可以通过JDBC去操作,代码片段如下所示:
Driver driver = (Driver) Class.forName("org.apache.kylin.jdbc.Driver").newInstance();
Properties info = new Properties();
info.put("user", "ADMIN");
info.put("password", "KYLIN");
Connection conn = driver.connect("jdbc:kylin://dn1:7070/kylin_project_name", info);
Statement state = conn.createStatement();
ResultSet resultSet = state.executeQuery("select * from test_table");
while (resultSet.next()) {
assertEquals("foo", resultSet.getString(1));
assertEquals("bar", resultSet.getString(2));
assertEquals("tool", resultSet.getString(3));
}
6.总结
在使用Kylin时,我们有必要去首先熟悉其架构,这能让我们更加熟悉其应用场景和业务场景。在集成和使用的过程当中会遇到一些问题,我们可以分析其异常日志,然后利用搜索引擎得到解决。关于Kylin的详细使用,大家可以参考官方撰写的文档。
7.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!