
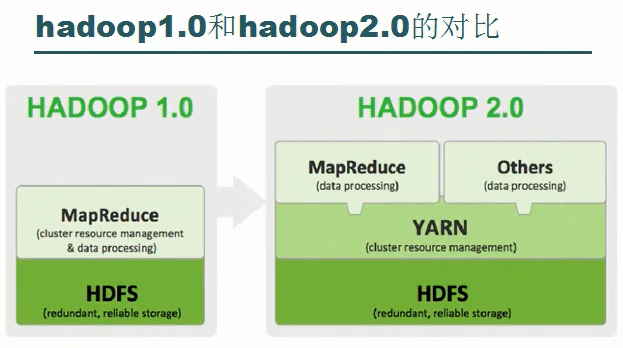
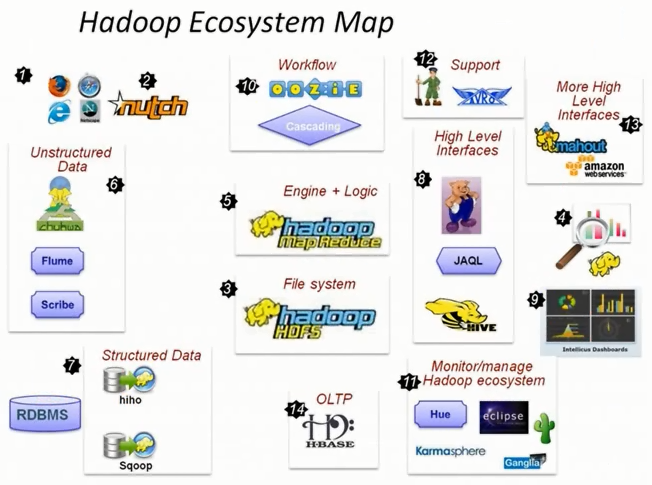

MapReduce编程实现学习
MapReduce主要包括两个阶段:一个是Map,一个是Reduce. 每一步都有key-value对作为输入和输出。 Map阶段的key-value对的格式是由输入的格式决定的,如果是默认的TextInputFormat,则每行作为一个记录进程处理,其中key为此行的开头相对文件的起始位置,value就是此行的字符文本。Map阶段的输出的key-value对的格式必须同reduce阶段的输入key-value对的格式相对应。 下面开始尝试,假设我们需要处理一批有关天气的数据,其格式如下:按照ASCII码存储,每行一条记录每一行字符从0开始计数,第15个到第18个字符为年第25个到第29个字符为温度,其中第25位是符号+/- Text文本样例: 0067011990999991950051507+0000+ 0043011990999991950051512+0022+ 0043011990999991950051518-0011+ 0043012650999991949032412+0111+ 0043012650999991949032418+0078+ 0067011990999...