MapReduce深度分析(一)
一、数据流向分析
![]()
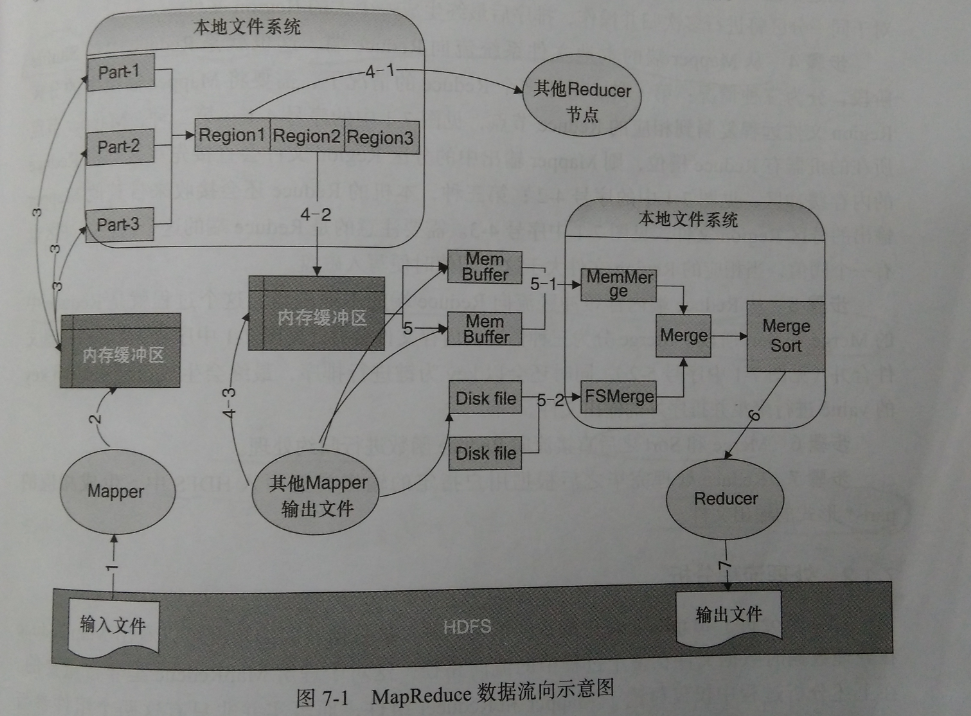
图为MapReduce数据流向示意图
步骤1、输入文件从HDFS流向到Mapper节点。在一般情况下,存储数据的节点就是Mapper运行的节点,不需要在节点之间进行数据传输,也就是尽量让存储靠近计算。
步骤2、mapper输出到内存缓冲区。Mapper的输入是解析后的键值对,输出是经过处理后新的<key,value>键值对。mapper的输出并不是直接写到本地文件系统,而是先写入一个内存缓冲区,当缓冲区达到一定的阈值后就将缓冲区中的数据以一个临时文件的形式写入本地磁盘。partitioner就是发生在这个阶段,也就是在写入内存缓冲区的同时执行了partitioner对文件进行分区,以便后续对Reduce进行处理。
步骤3、从内存缓冲区到磁盘。当缓冲区达到100M,溢写比例默认是0.8。从缓冲区写到本地磁盘的过程就是spill。溢写线程启动同时会对这80M的内存数据依据key进行排序,如果用户作业设置了Combiner,那么在写到磁盘之前,会对Map输出的键值对调用Combiner类做规约操作。目的是减少溢写到本地磁盘文件的数据量。这个过程还涉及对多次临时文件的合并,排序后最终形成Region文件。
步骤4、从Mapper端的本地文件系统流向Reduce端。也就是Shuffle阶段。复制数据阶段。
步骤5、从Reduce端内存缓冲区流向Reduce端的本地磁盘。这个过程就是Reduce中的Merge和Sort阶段。Merge分为三种情况,内存文件合并,磁盘文件合并,同时还会以key为键进行排序,最终会生成已经对相同key的value进行聚集并排序号的输出文件。
步骤6、Merge和Sort之后直接流向Reduce函数进行规约操作。
步骤7、Reduce处理完毕之后根据用户指定的输出类型写入HDFS中,生成相应的part-*形式的输出文件。
二、处理流程分析
![]()
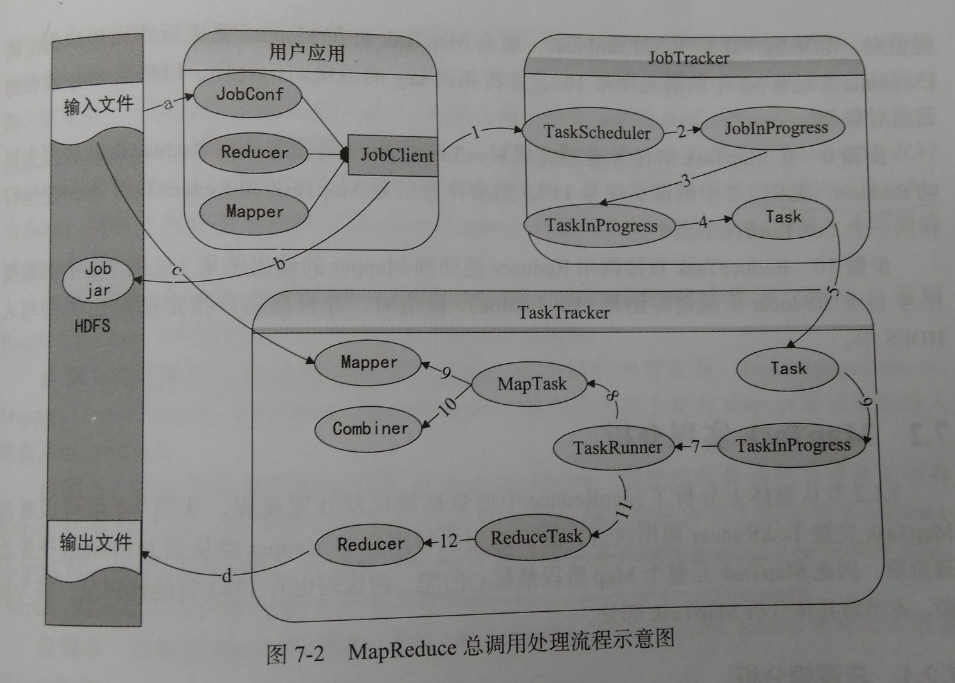
步骤1、用户的应用通过JobClient类提交到JobTracker,在JobClient类中,将用户程序的Mapper类,Reducer类以及配置JobConf打包成一个JAR文件并保存在HDFS中,需要指定JobConf的输入路径(a)、输出路径,Mapper和Reducer类名的参数。JobClient在提交作业的时候,将作业jar文件的路径一起提交到JobTracker的master服务,也就是作业调度器。见序号1
步骤2、在JobClient提交Job后,JobTracker会创建一个JobInProgress来跟踪和调度这个作业,并将其添加到调度器的作业队列中,见序号2
步骤3、JobInProgress会根据提交作业jar文件中定义的输入数据集创建相应数量的TaskInProcess用于监控和调度MapTask和ReduceTask,序号3
步骤4、JobTracker启动任务时通过TaskInProgress来启动作业任务序号4,这时会把Task对象(MapTask和ReduceTask)序列化写入相应的TaskTracker服务中。序号5
步骤5、TaskTracker收到后创建相应的TaskInProgress用于监控和调度运行该Task,序号6
步骤6、启动具体的Task进程,TaskTracker通过TaskInProgress管理的TaskRunner对象运行具体的Task,序号7
步骤7、TaskRunner自动装载作业jar文件,并设置好环境变量后启动一个独立的Java子进程来执行Task,TaskRunner会首先调用执行MapTask,序号8
步骤8、MapTask先调用Mapper,进行Mapper的相关操作。
步骤9、MapTask的任务完成之后,TaskRunner调用ReduceTask进程来启动Reducer,需要注意的是MapTask和ReduceTask不一定会运行在同一个TaskTracker中。
步骤10、ReduceTask直接调用Reducer类处理Mapper的输出结果,Reducer生成最终的结果键值对,写到HDFS中。
三、MapTask实现分析
MapTask先被TaskRunner调用执行,然后调用执行用户的Mapper类从而开始Map任务处理阶段,因此MapTask是整个Map阶段最核心的类。
![]()
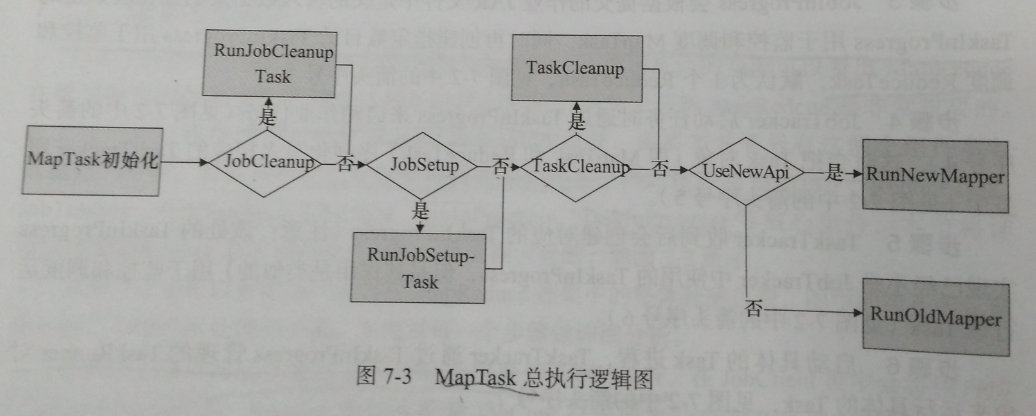
图为MapTask总执行逻辑图。通过调用initialize()方法执行初始化工作。Map的初始化任务包括JobContext、TaskContext、输出路径等,调用Task.initialize()方法。初始化完成之后会依次判断作业类型,MapTask中三种特殊的作业:cleanupJobTask(清理Map任务)、setupJobTask(初始化Map任务)和TaskCleanupTask(清理作业任务),这三种类型的作业会根据需要进行判断调用。
处理流程:
步骤1、创建执行Mapper所需要的对象。首先创建的对象有:TaskAttemptContext、Mapper、InputFormat、InputSplit、RecordReader。这些类的对象主要为Mapper要读取的输入数据及切分准备。
步骤2、创建所需要的输出收集器OutputCollector。
步骤3、初始化RecordReader,通过input.initialize(split,mapperContext)来对输入数据进行初始化。
步骤4、执行Mapper,通过mapper.run(mapperContext)最终调用用户指定的Mapper类对数据进行Map操作。
以上就是RunNewMapper总的处理步骤。
![]()
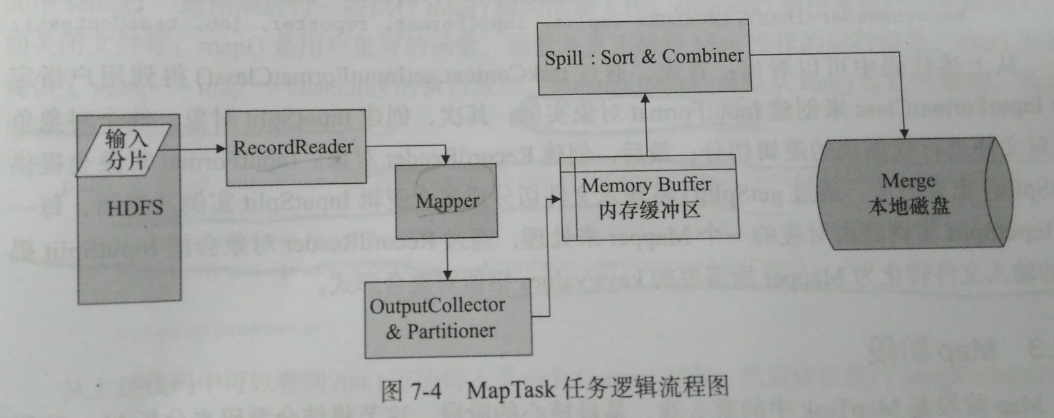
对于以上步骤可以分为以下几个阶段:
Read阶段:通过RecordReader对象,对HDFS上的文件进行split切分,调用用户指定的输入文件格式类解析每一个split文件,输出<key,value>键值对。
Map阶段:对输入的键值对调用用户编写的Map函数进行处理,并输出<key,value>键值对
Collector和Partitioner阶段:收集Mapper的输出,并在OutputCollector函数内部对键值对进行Partitioner分区,以便确定相应的Reducer处理,这个阶段将最终的键值对集合输出到内存缓冲区。
Spill阶段:包含Sort和Combiner阶段,从内存缓冲区写到磁盘的过程。
Merge阶段:对Spill阶段在本地磁盘生成的小文件进行多次合并,生成一个大文件。
下面具体分析每个阶段的具体任务:
Read阶段:首先通过taskContext.getInputFormatClass()得到用户指定的InputFormatClass来创建InputFormat对象实例;其次创建InputSplit对象,这个对象负责对文件进行数据块的逻辑切分;最后,创建RecordReader对象。InputFormat对象会提供getSplit()重要方法,通过getSplit将输入文件切分成多个逻辑InputSplit实例并返回,每一个InputSplit实例就由对应的一个Mapper处理,通过RecordReader对象把InputSplit提供的输入文件转化为Mapper所需要的keys/values键值对集合。
Map阶段:Mapper类中有setup、map、cleanup、run四个核心方法,通过调用run方法,依次执行setup(context)-->map()-->cleanup(context)
Collector和Partitioner阶段:map函数处理的结果不直接写到内存缓冲区,而有一个Collector对象进行收集。partition是对应的Reduce分区号,是Partitioner的返回值,也就是传到Reduce节点处理。自定义的MapperOutputCollector接口,并实现collect、close、flush方法。
Spill阶段:首先创建spill文件,2、按照partition的顺序对内存缓冲区中的数据进行排序。3、循环依次将每个partition写入磁盘文件。4、创建spill index文件。
Merge阶段:经过spill阶段会生成多个spill.out文件和相应的索引文件spill.out.index,MapTask最终需要将这些形式的临时文件经过多次合并成一个大的输出文件。
四、ReduceTask实现分析
和MapTask类似,ReduceTask也继承了Task类,重写了run方法,ReduceTask就是调用run方法来执行Reduce任务的。
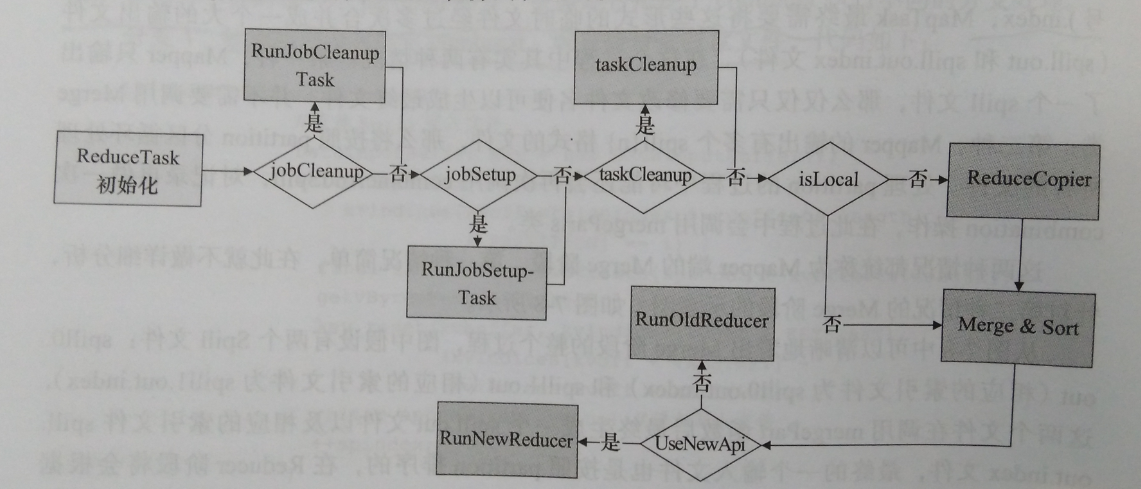
![]()
图为ReduceTask整体的处理逻辑,首先是ReduceTask的初始化工作,包括添加Reduce过程需要经过的copy、sort和Reduce阶段,以便通知JobTracker目前运行的情况,设置并启动reporter进程以便和JobTracker进行交流,最后进行一些和任务输出相关的设置。比如创建commiter,设置工作目录等。ReduceTask阶段分为四个阶段:
shuffle阶段:这个阶段就是Reduce中的copy阶段,运行Reduce的TaskTracker需要从各个Mapper节点远程复制属于自己处理的一段数据。
Merge阶段:进行多次合并。
sort阶段:虽然每个Mapper的输出是按照key排序好的,但是经过Shuffle和Merge阶段后并不是统一有序的。
Reduce阶段:在Sort阶段完成后,执行Reduce类进行规约。
当神已无能为力,那便是魔渡众生