Hadoop2.7实战v1.0之动态添加DataNode和NodeManager节点(不修改dfs.replication)【终极版】
0.添加大文件到hdfs系统中去,是为了后期的动态添加datanode的机器,datanode机器的数据量不均衡,为了模拟均衡实验
- [root@sht-sgmhadoopnn-01 ~]# hadoop fs -put /root/oracle-j2sdk1.7-1.7.0+update67-1.x86_64.rpm /testdir
-
- [root@sht-sgmhadoopnn-01 ~]# hadoop fs -put /root/012_HDFS.avi /testdir
-
- [root@sht-sgmhadoopnn-01 ~]# hadoop fs -put /root/016_Hadoop.avi /testdir
![]()
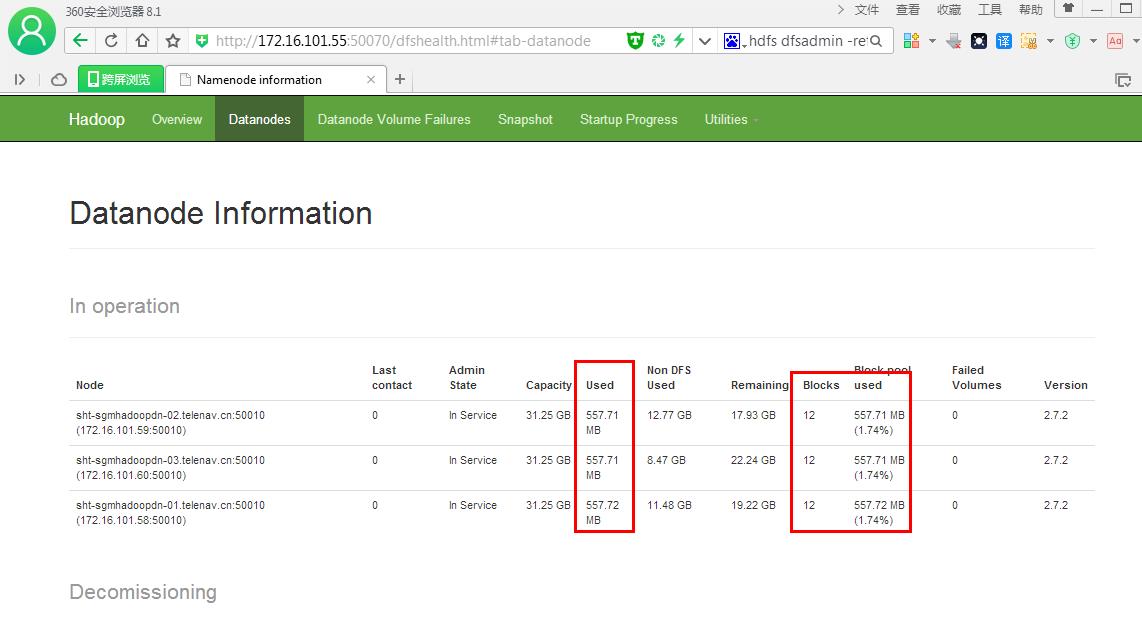
###3个datanode节点数据量和数据块相等
1.修改系统hostname(通过hostname和/etc/sysconfig/network进行修改)
- [root@sht-sgmhadoopdn-04 ~]# hostname
-
- sht-sgmhadoopdn-04.telenav.cn
-
- [root@sht-sgmhadoopdn-04 ~]# more /etc/sysconfig/network
-
- NETWORKING=yes
-
- HOSTNAME=sht-sgmhadoopdn-04.telenav.cn
-
- GATEWAY=172.16.101.1
2.修改hosts文件,将集群所有节点hosts配置进去(集群所有节点保持hosts文件统一)
- [root@sht-sgmhadoopdn-04 ~]# more /etc/hosts
- 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
- ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
-
- 172.16.101.54 sht-sgmhadoopcm-01.telenav.cn sht-sgmhadoopcm-01
- 172.16.101.55 sht-sgmhadoopnn-01.telenav.cn sht-sgmhadoopnn-01
- 172.16.101.56 sht-sgmhadoopnn-02.telenav.cn sht-sgmhadoopnn-02
- 172.16.101.58 sht-sgmhadoopdn-01.telenav.cn sht-sgmhadoopdn-01
- 172.16.101.59 sht-sgmhadoopdn-02.telenav.cn sht-sgmhadoopdn-02
- 172.16.101.60 sht-sgmhadoopdn-03.telenav.cn sht-sgmhadoopdn-03
- 172.16.101.66 sht-sgmhadoopdn-04.telenav.cn sht-sgmhadoopdn-04
- [root@sht-sgmhadoopdn-04 ~]#
##修改集群的其他节点hosts文件
3.查看是否有.ssh文件夹,删除.ssh,重新配置
- [root@sht-sgmhadoopdn-04 ~]# ls -l -a
-
- total 138948
-
- drwxr-x---. 7 root root 4096 Feb 1 17:06 .
-
- dr-xr-xr-x. 25 root root 4096 Feb 9 09:34 ..
-
- drwxr-x---. 2 root root 4096 Dec 31 15:29 .ssh
-
- [root@sht-sgmhadoopdn-04 ~]# rm -rf .ssh
-
-
-
-
- [root@sht-sgmhadoopdn-04 ~]# ssh-keygen
-
- Generating public/private rsa key pair.
-
- Enter file in which to save the key (/root/.ssh/id_rsa):
-
- Created directory '/root/.ssh'.
-
- Enter passphrase (empty for no passphrase):
-
- Enter same passphrase again:
-
- Your identification has been saved in /root/.ssh/id_rsa.
-
- Your public key has been saved in /root/.ssh/id_rsa.pub.
-
- The key fingerprint is:
-
- 2e:24:52:bf:9d:c4:b8:d8:d6:7a:45:47:7b:cc:54:d0 root@sht-sgmhadoopdn-04.telenav.cn
-
- The key
4.设置NameNode(两台HA均需要)到DataNode的免密码登录(ssh-copy-id命令实现,可以免去cp *.pub文件后的权限修改)
参考 http://blog.itpub.net/30089851/viewspace-1992210/
###其实最好将集群的每台都互相配置信任,包括新加的机器(我采取这个)
5.修改主节点slave文件,添加新增节点的ip信息,这里添加的是hostname:sht-sgmhadoopdn-04(集群重启时使用)
- [root@sht-sgmhadoopnn-01 ~]# cd /hadoop/hadoop-2.7.2/etc/hadoop
-
- [root@sht-sgmhadoopnn-01 hadoop]# vi slaves
-
- sht-sgmhadoopdn-01
-
- sht-sgmhadoopdn-02
-
- sht-sgmhadoopdn-03
-
- sht-sgmhadoopdn-04
-
-
-
-
- "slaves" 4L, 76C written
-
- [root@sht-sgmhadoopnn-01 hadoop]# scp slaves root@sht-sgmhadoopnn-02:/hadoop/hadoop-2.7.2/etc/hadoop
-
- slaves 100% 76 0.1KB/s 00:00
-
- [root@sht-sgmhadoopnn-01 hadoop]#
###我觉得这里应该将slaves文件scp到standbyNameNode即可,当然我倾向scp到其他所有节点(standbyNameNode,other DataNode);
毕竟假如集群重启了,active节点机器变为standby节点,standby节点机器变为active节点,那么假如slaves文件没有改变的话,那么执行start-dfs.sh脚本的话,那么新加的datanode节点就起不来!
6.新增的datanode 节点安装hadoop软件
- [root@sht-sgmhadoopdn-04 ~]# cd /tmp
-
- [root@sht-sgmhadoopdn-04 tmp]# wget https://www.apache.org/dist/hadoop/core/hadoop-2.7.2/hadoop-2.7.2.tar.gz --no-check-certificate
-
- [root@sht-sgmhadoopnn-04 tmp]# tar -xvf hadoop-2.7.2.tar.gz
-
- [root@sht-sgmhadoopdn-04 tmp]# mv hadoop-2.7.2 /hadoop/hadoop-2.7.2
-
- [root@sht-sgmhadoopdn-04 tmp]# cd /hadoop/hadoop-2.7.2/
-
- [root@sht-sgmhadoopdn-04 hadoop-2.7.2]# ll
-
- total 52
-
- drwxr-xr-x 2 10011 10011 4096 Jan 26 08:20 bin
-
- drwxr-xr-x 3 10011 10011 4096 Jan 26 08:20 etc
-
- drwxr-xr-x 2 10011 10011 4096 Jan 26 08:20 include
-
- drwxr-xr-x 3 10011 10011 4096 Jan 26 08:20 lib
-
- drwxr-xr-x 2 10011 10011 4096 Jan 26 08:20 libexec
-
- -rw-r--r-- 1 10011 10011 15429 Jan 26 08:20 LICENSE.txt
-
- -rw-r--r-- 1 10011 10011 101 Jan 26 08:20 NOTICE.txt
-
- -rw-r--r-- 1 10011 10011 1366 Jan 26 08:20 README.txt
-
- drwxr-xr-x 2 10011 10011 4096 Jan 26 08:20 sbin
-
- drwxr-xr-x 4 10011 10011 4096 Jan 26 08:20 share
-
- [root@sht-sgmhadoopdn-04 hadoop-2.7.2]#
7.将hadoop的配置文件scp到新的节点上
- [root@sht-sgmhadoopnn-01 ~]# cd /hadoop/hadoop-2.7.2/etc/hadoop/
-
- [root@sht-sgmhadoopnn-01 hadoop]# scp * root@sht-sgmhadoopdn-04:/hadoop/hadoop-2.7.2/etc/hadoop/
8.在新节点上启动datanode进程和nodemanager进程之前,必须检查$HADOOP_HOME/data/目录是否存在?假如存在,就直接先删除该目录的所有的文件
原因是机器有可能第二次添加为数据节点,清除数据文件等
- [root@sht-sgmhadoopnn-04 ~]# cd /hadoop/hadoop-2.7.2/data/
-
- [root@sht-sgmhadoopnn-04 data]# rm -rf *
【启动datanode进程】
9.在新增的节点上,启动datanode进程
- [root@sht-sgmhadoopdn-04 hadoop]# cd ../../sbin
-
- [root@sht-sgmhadoopdn-04 sbin]# ./hadoop-daemon.sh start datanode
-
- starting datanode, logging to /hadoop/hadoop-2.7.2/logs/hadoop-root-datanode-sht-sgmhadoopdn-04.telenav.cn.out
然后在namenode通过hdfs dfsadmin -report或者web
v [root@sht-sgmhadoopdn-01 bin]# ./hdfs dfsadmin –report
v http://172.16.101.55:50070/dfshealth.html#tab-datanode
![]()
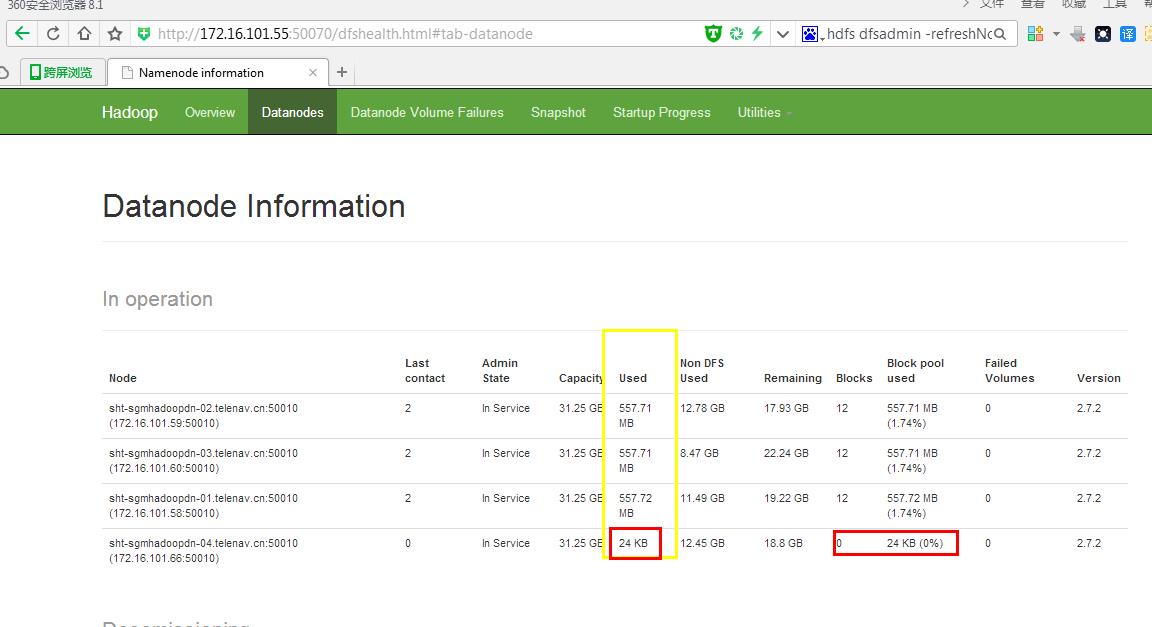
###负载不均衡, sht-sgmhadoopdn-04的数据块0,Used的24kb
@假如sht-sgmhadoopdn-04的datanode进程已经起来了,那么web界面datanode就是不显示sht-sgmhadoopdn-04这一行数据,先执行./hadoop-daemon.sh stop datanode命令关闭当前进程;
@然后再要检查是否设置了dfs.hosts,dfs.hosts.exclude参数,那么就注释这两个参数,然后执行hdfs dfsadmin -refreshNodes,刷新一下配置,然后有可能出现下面这幅图1,Dead状态;
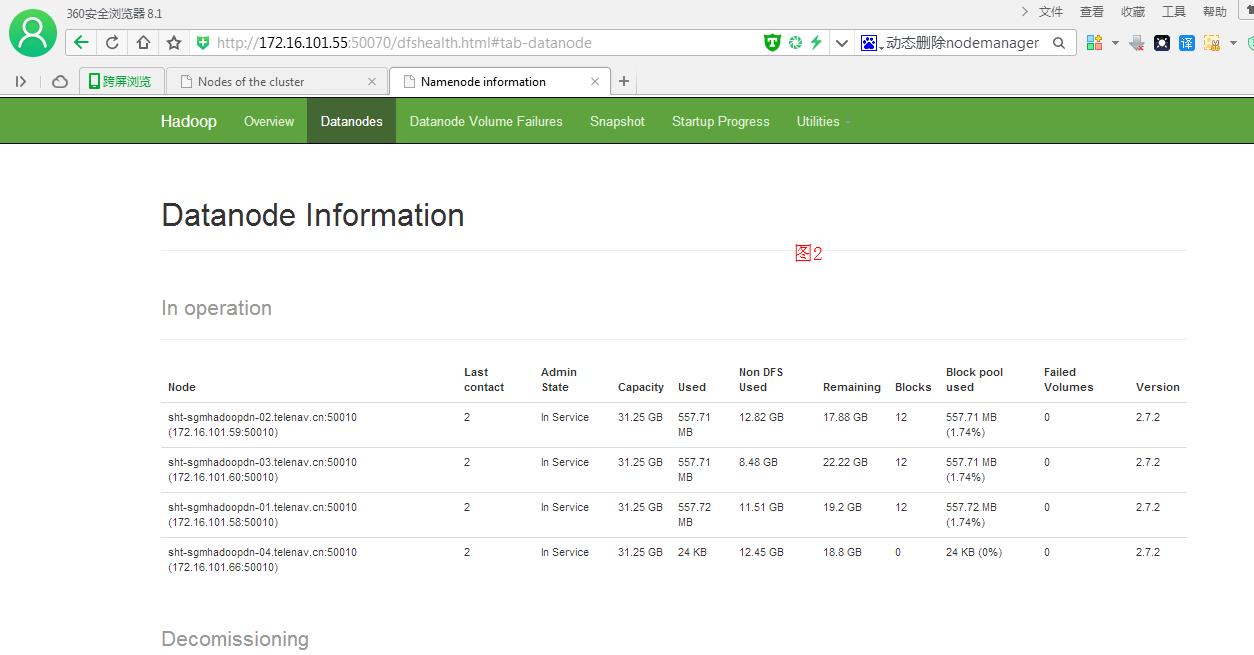
@最后只要再执行./hadoop-daemon.sh start datanode,刷新web就行,图2, 继续执行。
![]()
![]()
【启动nodemanager进程】
10.在新增的节点上,启动nodemanager进程
由于Hadoop 2.X引入了YARN框架,所以对于每个计算节点都可以通过NodeManager进行管理,同理启动NodeManager进程后,即可将其加入集群
在新增节点,运行sbin/yarn-daemon.sh start nodemanager即可
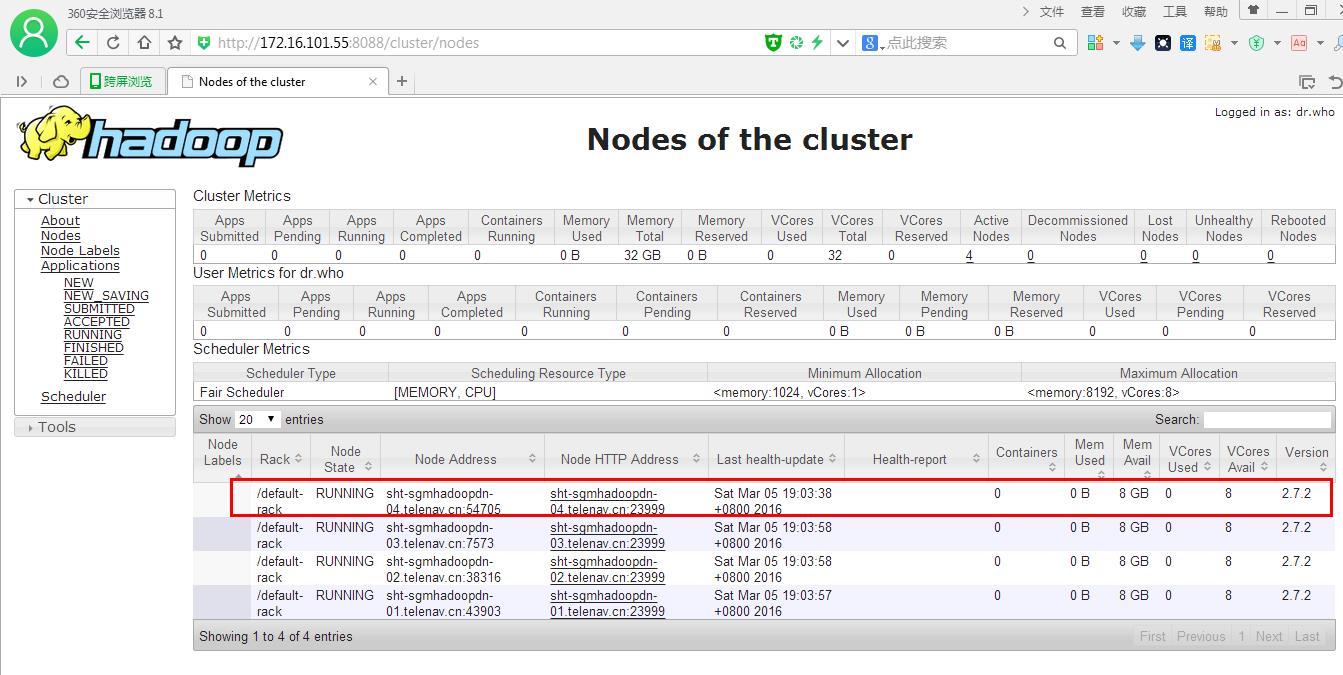
在ResourceManager,通过yarn node -list查看集群情况
- [root@sht-sgmhadoopdn-04 sbin]# ./yarn-daemon.sh start nodemanager
-
- starting nodemanager, logging to /hadoop/hadoop-2.7.2/logs/yarn-root-nodemanager-sht-sgmhadoopdn-04.telenav.cn.out
-
-
-
-
- [root@sht-sgmhadoopdn-04 sbin]# jps
-
- 14508 DataNode
-
- 15578 Jps
-
- 15517 NodeManager
-
- [root@sht-sgmhadoopdn-04 sbin]# cd ../bin
-
- [root@sht-sgmhadoopdn-04 bin]# ./yarn node -list
-
- 16/03/05 19:00:04 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
-
- Total Nodes:4
-
- Node-Id Node-State Node-Http-Address Number-of-Running-Containers
-
- sht-sgmhadoopdn-04.telenav.cn:54705 RUNNING sht-sgmhadoopdn-04.telenav.cn:23999 0
-
- sht-sgmhadoopdn-03.telenav.cn:7573 RUNNING sht-sgmhadoopdn-03.telenav.cn:23999 0
-
- sht-sgmhadoopdn-02.telenav.cn:38316 RUNNING sht-sgmhadoopdn-02.telenav.cn:23999 0
-
- sht-sgmhadoopdn-01.telenav.cn:43903 RUNNING sht-sgmhadoopdn-01.telenav.cn:23999 0
![]()
11.最后还需要对hdfs负载设置均衡,因为默认的数据传输带宽比较低,可以设置为64M,即hdfs dfsadmin -setBalancerBandwidth 67108864即可
- [root@sht-sgmhadoopnn-01 ~]# cd /hadoop/hadoop-2.7.2/bin
-
- [root@sht-sgmhadoopdn-01 bin]# ./hdfs dfsadmin -setBalancerBandwidth 67108864
-
- Balancer bandwidth is set to 67108864 for sht-sgmhadoopnn-01/172.16.101.55:8020
-
- Balancer bandwidth is set to 67108864 for sht-sgmhadoopnn-02/172.16.101.56:8020
12.默认balancer的threshold为10%,即各个节点与集群总的存储使用率相差不超过10%,我们可将其设置为5%;然后启动Balancer,sbin/start-balancer.sh -threshold 5,等待集群自均衡完成即可。
- [root@sht-sgmhadoopdn-01 bin]# cd ../sbin
-
- starting balancer, logging to /hadoop/hadoop-2.7.2/logs/hadoop-root-balancer-sht-sgmhadoopnn-01.telenav.cn.out
-
- [root@sht-sgmhadoopnn-01 sbin]# ./start-balancer.sh -threshold 5
-
- starting balancer, logging to /hadoop/hadoop-2.7.2/logs/hadoop-root-balancer-sht-sgmhadoopnn-01.telenav.cn.out
###运行这个命令start-balancer.sh -threshold 5和使用hdfs balancer是一样的
#### Usage: hdfs balancer
- [root@sht-sgmhadoopnn-01 bin]# ./hdfs balancer -threshold 5
-
- 16/03/05 18:57:33 INFO balancer.Balancer: Using a threshold of 1.0
-
- 16/03/05 18:57:33 INFO balancer.Balancer: namenodes = [hdfs://mycluster]
-
- 16/03/05 18:57:33 INFO balancer.Balancer: parameters = Balancer.Parameters[BalancingPolicy.Node, threshold=1.0, max idle iteration = 5, number of nodes to be excluded = 0, number of nodes to be included = 0]
-
- Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved
-
- 16/03/05 18:57:34 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
-
- 16/03/05 18:57:35 INFO net.NetworkTopology: Adding a new node: /default-rack/172.16.101.58:50010
-
- 16/03/05 18:57:35 INFO net.NetworkTopology: Adding a new node: /default-rack/172.16.101.60:50010
-
- 16/03/05 18:57:35 INFO net.NetworkTopology: Adding a new node: /default-rack/172.16.101.66:50010
-
- 16/03/05 18:57:35 INFO net.NetworkTopology: Adding a new node: /default-rack/172.16.101.59:50010
-
- 16/03/05 18:57:35 INFO balancer.Balancer: 0 over-utilized: []
-
- 16/03/05 18:57:35 INFO balancer.Balancer: 0 underutilized: []
-
- The cluster is balanced. Exiting...
-
- Mar 5, 2016 6:57:35 PM 0 0 B 0 B -1 B
-
- Mar 5, 2016 6:57:35 PM Balancing took 2.66 seconds
A. 为什么我执行该命令hdfs balancer -threshold 5平衡数据命令没有反应呢?
5表示5%,
群总存储使用率: 1.74%
sht-sgmhadoopdn-01: 1.74%
sht-sgmhadoopdn-02: 1.74%
sht-sgmhadoopdn-03: 1.74%
sht-sgmhadoopdn-04: 0%
执行-threshold 5, 表示每一个 datanode 存储使用率和集群总存储使用率的差值都应该小于这个阀值5%;
假如超过5%,会执行数据平衡操作。
B. 怎样判断执行命令是否会生效,数据平衡操作?
if (群总存储使用率 — 每一台datanode 存储使用率) > -threshold 5
#会执行数据平衡
else
#该命令不生效
end if
C. the threshold range of [1.0, 100.0],所以最小只能设置 -threshold 1
13. 执行命令hdfs balancer -threshold 1
[root@sht-sgmhadoopnn-01 hadoop]# hdfs balancer -threshold 1
……………..
……………..
16/03/08 16:08:09 INFO net.NetworkTopology: Adding a new node: /default-rack/172.16.101.59:50010
16/03/08 16:08:09 INFO net.NetworkTopology: Adding a new node: /default-rack/172.16.101.58:50010
16/03/08 16:08:09 INFO net.NetworkTopology: Adding a new node: /default-rack/172.16.101.66:50010
16/03/08 16:08:09 INFO net.NetworkTopology: Adding a new node: /default-rack/172.16.101.60:50010
16/03/08 16:08:09 INFO balancer.Balancer: 0 over-utilized: []
16/03/08 16:08:09 INFO balancer.Balancer: 0 underutilized: []
The cluster is balanced. Exiting...
Mar 8, 2016 4:08:09 PM 1 382.22 MB 0 B -1 B
Mar 8, 2016 4:08:09 PM Balancing took 6.7001 minutes
![]()
###新增数据节点的411.7M
14.问题:在active namenode上成功执行数据平衡命令,namenode的状态发生的failover
问题描述:
sht-sgmhadoopnn-01 :active—>standby
sht-sgmhadoopnn-02 :standby—>active,发生了failover操作.
揣测:在active节点上操作数据平衡命令,可能cpu等资源不够用了,就发生了failover,建议在新的数据节点datanode上操作.
修正:
- [root@sht-sgmhadoopnn-01 hadoop]# hdfs haadmin -failover nn2 nn1
- Failover to NameNode at sht-sgmhadoopnn-01/172.16.101.55:8020 successful
- [root@sht-sgmhadoopnn-01 hadoop]# hdfs haadmin -getServiceState nn1
- active
- [root@sht-sgmhadoopnn-01 hadoop]# hdfs haadmin -getServiceState nn2
- standby
- [root@sht-sgmhadoopnn-01 hadoop]#