新兴产业的出现和发展有两种基本模式。一种是需求导向型,实际应用中出现了明显的痛点,必须要解决,不然就有人一直痛。另一种是技术导向型,革命性的技术先出现,慢慢地新技术扩大了用户的想象空间,进而激发出新的需求。大数据从概念提出到今天形成一个完整的产业,基本上属于第二种模式。
Hadoop生态系统下的技术(包括 pig,hive,spark,storm,hbase等)是目前大数据业界中事实上的标准。但在hadoop从互联网产业走出之前,大数据本身还不能称之为一个“产业”,因为它没有形成足够大的规模。所以大数据并不是指数据量有多大,是GB,TB还是PB,这其实没有关系。真正意义上的大数据是指 hadoop体系技术从互联网行业被引入到其它行业,进而得到快速、广泛、多维度、多层次的大量普及应用。大数据之大,在于应用规模的大,而不是数据量的大。现在大数据的应用已经远远超越了互联网行业,包括公安、智慧城市、医疗、交通、教育、通信、游戏、服装、地产、旅游、保险、银行、证券、食品安全、海事、零售、气象等等--世界正快速进入全面数据服务的时代!
大数据产业发展最快的一个是美国,另一个就是中国。有关中国大数据市场容量的预测和估算有很多版本,激进者估计千亿市场的,悲观的认为国内大数据市场刚刚萌芽。判断一个行业发展趋势最好的工具现在就是求职招聘网站。我们将通过大数据相关职位空缺数,来判断国内大概有多少个企业客户在实施大数据项目。我们以51job为例做些调查分析。分析的方法非常简单,统计大数据相关职位的招聘情况。以下数据截止到2015年4月27日,来源于51job,地域覆盖北上广深杭。
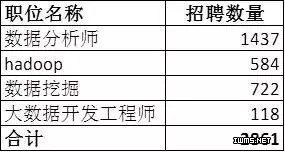
分别选取了比较热门的一些招聘职位:数据分析师、hadoop、数据挖掘、大数据开发工程师,企业招聘情况如下:
合计为2861个,对结果进行一些修正:
(1)因为职位名称,或者没覆盖到的其他大数据技术职位,乘以系数:1.2
(2)因为51job的限制,仅仅统计了5个城市,乘以系数1.3
(3)可能没在51job上发布的职位: 乘以系数1.1
这样修正后,国内大数据职位空缺数4909。根据这个数字,我们来推算客户数:
(4)考虑同一家公司可能同时有1-3个大数据相关职位发布,乘以系数:0.8
(5)假设在实施大数据项目的客户有五分之一的有招聘需求,乘以系数:5.0
最终结果:19636。
也就是说,截止2015年4月27日,国内有大概19636个大数据项目在进行。假设平均一个项目规模为50万(比较保守的估计),则国内大数据项目的规模合计为98亿人民币。考虑现在才是2015年第二季度,2015全年大数据项目规模肯定超过100亿人民币。数据服务有限公司)