版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq1010885678/article/details/45973451
本文测试的Spark版本是1.3.1
Spark Streaming编程模型:
第一步:
需要一个StreamingContext对象,该对象是Spark Streaming操作的入口 ,而构建一个StreamingContext对象需要两个参数:
1、SparkConf对象:该对象是配置Spark 程序设置的,例如集群的Master节点,程序名等信息
2、Seconds对象:该对象设置了StreamingContext多久读取一次数据流
第二步:
构建好入口对象之后,直接调用该入口的方法读取各种不同方式传输过来的数据流,如:Socket,HDFS等方式。并会将数据转换成DStream对象进行统一操作
第三步:
DStream本身是一种RDD序列,Streaming接受数据流之后会进行切片,每个片都是一个RDD,而这些RDD最后都会包装到一个DStream对象中统一操作。在这个步骤中,进行对数据的业务处理
第四步:
调用入口对象的start和awaitTermination开始读取数据流
下面分别使用不同的Spark Streaming 处理方式完成WordCount单词计数
HDFS文件测试
object HDFSWordCount {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println("Usgae : <spark master> <hdfs path>")
System.exit(1)
}
val sparkConf = new SparkConf().setMaster(args(0)).setAppName("HDFSWordCount")
val streaming = new StreamingContext(sparkConf,Seconds(10))
val data = streaming.textFileStream(args(1))
val words = data.flatMap(_.split(" "))
val wordCount = words.map(x => (x,1)).reduceByKey(_+_)
wordCount.print()
streaming.start()
streaming.awaitTermination()
}
Socket数据流测试
object NetworkWordCount {
def main(args: Array[String]) {
if (args.length < 3) {
System.err.println("Usage : <spark master> <hostname> <port>")
System.exit(1)
}
val sparkConf = new SparkConf().setMaster(args(0)).setAppName("NetworkWordCount")
val streaming = new StreamingContext(sparkConf,Seconds(10))
//参数:1、主机名;2、端口号;3、存储级别
val data =
streaming.socketTextStream(args(1),args(2).toInt,StorageLevel.MEMORY_AND_DISK_SER)
val words = lines.flatMap(_.split(" "))
val wordCount = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCount.print()
streaming.start()
streaming.awaitTermination()
}
可以看到,对于同一中业务处理逻辑来说,不同的数据来源只要调用不同的方法接收即可,转换成DStream之后的处理步骤是一模一样的
下面的代码时配合测试Socket数据的,使用java命令执行jar包,传入参数:1、端口号;2、产生数据的频率(毫秒)
即可在指定的端口上产生数据提供Spark Streaming接收
package Streaming
import java.net.ServerSocket
import java.io.PrintWriter
object Logger {
def generateContent(index: Int): String = {
import scala.collection.mutable.ListBuffer
val charList = ListBuffer[Char]()
for (i <- 65 to 90) {
charList += i.toChar
}
val charArray = charList.toArray
charArray(index).toString()
}
def index = {
import java.util.Random
val ran = new Random
ran.nextInt(7)
}
def main(args: Array[String]): Unit = {
if (args.length != 2) {
System.err.println("Usage:<port> <millisecond>")
System.exit(1)
}
val listener = new ServerSocket(args(0).toInt)
while (true) {
val socket = listener.accept()
new Thread() {
override def run = {
println("Get client connected from:" + socket.getInetAddress)
val out = new PrintWriter(socket.getOutputStream(), true)
while (true) {
Thread.sleep(args(1).toLong)
val content = generateContent(index)
println(content)
out.write(content + '\n')
out.flush()
}
socket.close()
}
}.start()
}
}
}
在上述的例子中,文中使用的是Seconds(10)
也就是说每10秒钟处理一次数据
第一个10秒处理的结果是不会影响到第二个10秒的
但是有时候我们需要进行汇通统计,要用到之前几个10秒阶段的数据怎么办?
这里要用到一个updateStateByKey方法,该方法会保存上次计算数据的状态,以供下次计算使用。
上代码:
object StatefulWordCount {
def main(args: Array[String]) {
if (args.length < 3) {
System.err.println("Usage : <spark master> <hostname> <port>")
System.exit(1)
}
//定义一个匿名函数,并赋值给updateFunc
//该函数是updateStateByKey方法的参数,该方法要求传入一个匿名参数且参数格式为values:Seq[Int],state:Option[Int]
//其中values是当前的数据,state表示之前的数据
//这个匿名函数的作用就是将各个10秒阶段的结果累加汇总
val updateFunc = (values:Seq[Int],state:Option[Int]) => {
val now = values.foldLeft(0)(_+_)
val old = state.getOrElse(0)
Some(now + old)
}
val conf = new SparkConf().setAppName("StatefulWordCount").setMaster(args(0))
val streaming = new StreamingContext(conf, Seconds(10))
//checkpoint会将数据放在指定的路径上,这个操作是必须的,为了保护数据,如果不设置会报异常
streaming.checkpoint(".")
val lines = streaming.socketTextStream(args(1), args(2).toInt, StorageLevel.MEMORY_AND_DISK_SER)
val words = lines.flatMap(_.split(" "))
val wordDStream = words.map(x => (x, 1))
//在这里将updateFunc传入
val stateDStream = wordDStream.updateStateByKey(updateFunc)
stateDStream.print()
streaming.start()
streaming.awaitTermination()
}
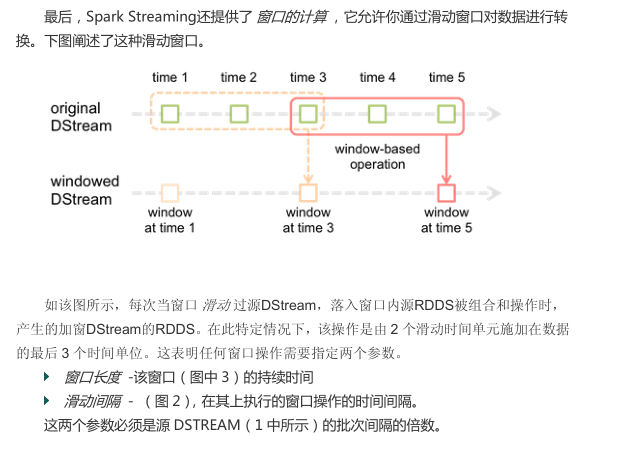
在Spark Streaming中还有一个window的概念,即滑动窗体
下图是官方文档中给出的解释:
![这里写图片描述]()
使用滑动窗体要设置两个指定参数:
1、窗体长度
2、滑动时间
例如,设置一个窗体长度为5,滑动时间为2,意味着,每2秒处理上一个5秒内的数据流
这样的处理可以应用在例如微博统计最热搜索词
每2秒钟统计一次过去5秒内的最热搜索词
统计最热搜索词实例代码:
object WindowWordCount {
def main(args: Array[String]) {
if (args.length < 3) {
System.err.println("Usage : <spark master> <hostname> <port> <Streaming Seconds> <Window Seconds> <Slide Seconds>")
System.exit(1)
}
val conf = new SparkConf().setAppName("WindowWordCount").setMaster(args(0))
val streaming = new StreamingContext(conf, Seconds(args(3).toInt))
//checkpoint会将数据放在指定的路径上,这个操作是必须的,为了保护数据,如果不设置会报异常
streaming.checkpoint(".")
val lines = streaming.socketTextStream(args(1), args(2).toInt, StorageLevel.MEMORY_ONLY)
val words = lines.flatMap(_.split(" "))
//map操作之后数据的格式为:
//(a,1)(b,1)...(n,1)格式
//调用reduceByKeyAndWindow替代普通的reduceByKey
//最后两个参数分别是窗体长度和滑动时间
val wordCount = words.map(x => (x, 1)).reduceByKeyAndWindow(_ + _, _ - _, Seconds(args(4).toInt),
Seconds(args(5).toInt))
//对结果进行降序排序
//由于DStream本身不具备RDD的一些操作,调用transform方法可以让RDD的一些操作(例如sortByKey等)作用在其之上,返回的仍然是一个DStream对象
val sorted = wordCount.map { case (char, count) => (count, char) }.transform(_.sortByKey(false)).map
{ case (count, char) => (char, count) }
sorted.print()
streaming.start()
streaming.awaitTermination()
}
}
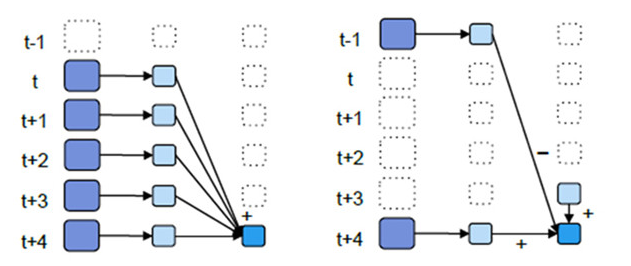
reduceByKeyAndWindow有两种使用方法:
1、educeByKeyAndWindow(_ + _, Seconds(5),seconds(1))
2、reduceByKeyAndWindow(_ + , - _, Seconds(5),seconds(1))
二者的区别见下图:
![这里写图片描述]()
第一种是简单粗暴的直接累加
而第二种方式就显得比较文雅和高效了
例如现在计算t+4的累积数据
第一种方式是,直接从t+…+(t+4)
第二种处理为,用已经计算好的(t+3)的数据加上(t+4)的数据,在减去(t-1)的数据,就可以得到和第一种方式一样的结果,但是中间复用了三个数据(t+1,t+2,t+3)
以上为Spark Streaming API的简单使用