要使用storm首先要安装以下工具:JDK、Python、zookeeper、zeromq、jzmq、storm
(注:各个模块都是独立的,如果安装失败或者卡顿可以单独百度某个模块的安装,都是可以的。)
JDK1.7安装 参见上篇《Ubuntu下安装配置JDK1.7》http://www.cnblogs.com/stone_w/p/4469548.html
第一步,安装Python2.7.2(ubuntu)
wget http://www.python.org/ftp/python/2.7.2/Python-2.7.2.tgz
tar zxvf Python-2.7.2.tgz
cd Python-2.7.2
./configure
make
make install
vi /etc/ld.so.conf
追加/usr/local/lib/
sudo ldconfig
第二步,安装zookeeper
下载zookeeper
解压,安装:http://pan.baidu.com/s/1jGjA90M
tar -zxvf zookeeper-3.3.5.tar.gz
cp -R zookeeper-3.3.5 /usr/local/
ln -s /usr/local/zookeeper-3.3.5/ /usr/local/zookeeper
gedit /etc/profile (设置ZOOKEEPER_HOME和ZOOKEEPER_HOME/bin)
export ZOOKEEPER_HOME="/path/to/zookeeper"
export PATH=$PATH:$ZOOKEEPER_HOME/bin
cp /usr/local/zookeeper/conf/zoo_sample.cfg /usr/local/zookeeper/conf/zoo.cfg (用zoo_sample.cfg制作$ZOOKEEPER_HOME/conf/zoo.cfg)
mkdir /tmp/zookeeper
mkdir /var/log/zookeeper
zookeeper的单机安装已经完成了。
第三步,安装zeromq以及jzmq
jzmq的安装貌似是依赖zeromq的,所以应该先装zeromq,再装jzmq。
1)安装zeromq:
wget http://download.zeromq.org/zeromq-2.2.0.tar.gz
tar zxf zeromq-2.2.0.tar.gz
cd zeromq-2.2.0
./configure
make
make install
sudo ldconfig (更新LD_LIBRARY_PATH)
zeromq安装完成。
注意:如有有依赖报错,需要安装:
jzmq dependencies 依赖包
sudo yum install uuid*
sudo yum install libtool
sudo yum install libuuid
sudo yum install libuuid-devel
2)安装jzmq
yum install git
git clone git://github.com/nathanmarz/jzmq.git
cd jzmq
./autogen.sh
./configure
make
make install
然后,jzmq就装好了.
注意:在./autogen.sh这步如果报错:autogen.sh:error:could not find libtool is required to run autogen.sh,这是因为缺少了libtool,可以用#yum install libtool*来解决。
第四步,安装Storm
我使用的Storm版本是最新的稳定版0.8.2,下载,解压,修改/conf/storm.yaml配置文件:
Storm 0.8.2 下载 http://pan.baidu.com/s/1sjODKPB
unzip storm-0.8.2.zip
mv storm-0.8.2 /usr/local/
ln -s /usr/local/storm-0.8.2/ /usr/local/storm
gedit /etc/profile
export STORM_HOME=/usr/local/storm-0.8.2
export PATH=$PATH:$STORM_HOME/bin
到此为止单机版的Storm就安装完毕了。
启动Storm
/usr/local/zookeeper/bin/zkServer.sh start
cd /usr/local/storm-0.8.2
bin/storm nimbus &
bin/storm supervisor &
bin/storm ui &
如果我们没有为storm添加环境变量,那么在启动的时候,我们就需要使用绝对路径或相对路径来定位/chenny/Storm/storm-0.8.2/bin/storm这个程序。启动完成后,我们可以使用jps来查看进程状态: >>jps 在没有运行任务时,我们必须应该要看到5个进程:QuorumPeerMain、nimbus、core、Jps、supervisor。否则 就需要检查是否正确地启动,如果启动之后没有过多久就停止了,我们就需要查看~/storm-0.8.2/logs下面的对应的log文件,查看引起异常 的原因是什么,然后解决后再次启动。 同时,我们可以在浏览器中输入http://127.0.0.1:8080来进入Storm UI的界面,可以查看Storm运行期间的相关信息。
第五步,测试一下本地模式的WordCount
网上别的资料介绍了许多方式来编译可执行的Topology程序,我们这里提供一个简单的办法,只需要使用Eclipse和相关的Jar包即 可,Ubuntu或者Windows环境下均可。我们需要从github上下载下来一个供初学者学习的storm-starter,同时,我们还需要有 commons-collections-3.2.1-bin.tar.gz、twitter4j-2.2.6.zip和storm-0.8.2.zip 等软件包,如果没有的话,需要去下载。以Windows XP下的Eclipse为例。首先我们将所有需要的包解压放到桌面,打开Eclipse,新建Java Project,名字任意取,我取名叫做MyFirstStormApp,然后点击Finish。
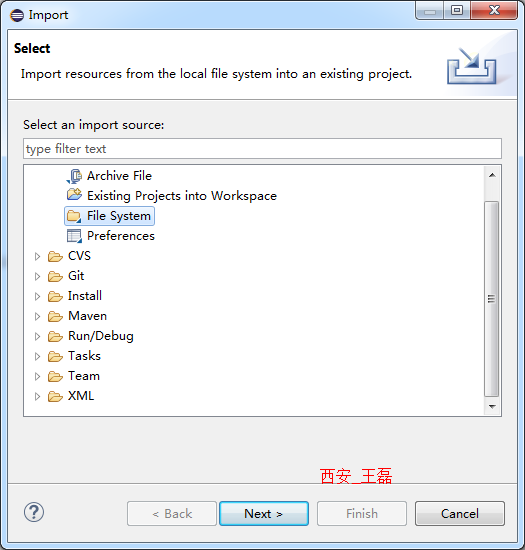
在MyFirstStormApp上右键,选择Import,然后选择File System:
![]()
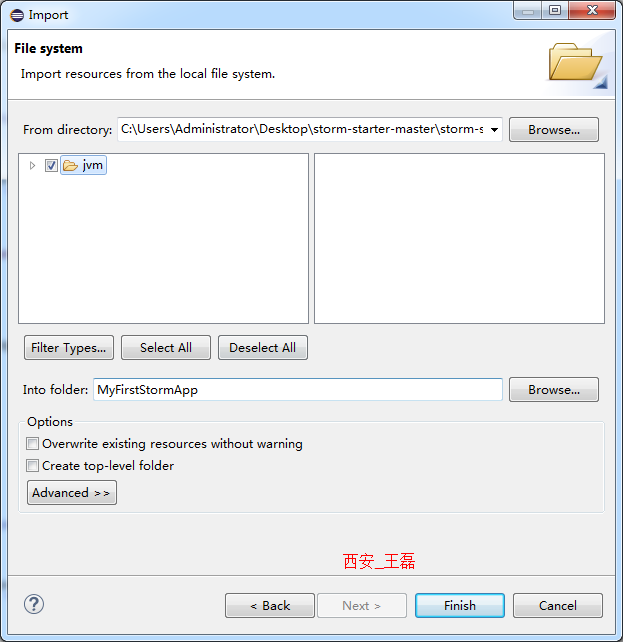
在From Directory中输入相应的路径或者点击Browse,选择路径:
![]()
我们依次展开storm-starter-master/src/jvm/storm,选中jvm文件夹,点击确定,然后勾选jvm,点击finish:
![]()
这样,我们就在左侧看到Project的结构:
![]()
拖动storm到src中,然后安装同样的方式将 storm-starter-master/storm-starter-master/multilang导入到项目中,然后我们就在左侧看到如下图所示的结构:
![]()
可以看到上面有很多红叉,此时,我们就需要导入项目所依赖的jar包,在项目上右键,选择Properties,然后Java Build Path,切换到Libraries选项夹下,点击Add External JARs:
![]()
将storm-0.8.2/lib目录下的所有jar包都加入到项目中,将
commons-collections-3.2.1.jar添加到 项目中,将twitter4j-2.2.6/lib中的所有jar包加入到项目中,将storm-0.8.2/storm-0.8.2.jar加入到项目 中,然后点击OK,这个时候,可以看到项目中的所有错误都消失了。接下来,我们将PrintSampleStream.java和 TwitterSampleSpout.java中的注释取消,或者将这两个文件删除
![]()
在项目上选择Export,然后选择JAR file,在下一页,我们将项目导出,勾选如下图所示:
![]()
点击finish后,如果没有错误,只有warning的话,就不用管了,否则我们需要检查错误,然后重新打包。打包后的jar包是MyFirstStormApp.jar,将它拷贝到部署有Storm的机器上(/usr/local/storm-0.8.2目录下),然后在终端中输入:
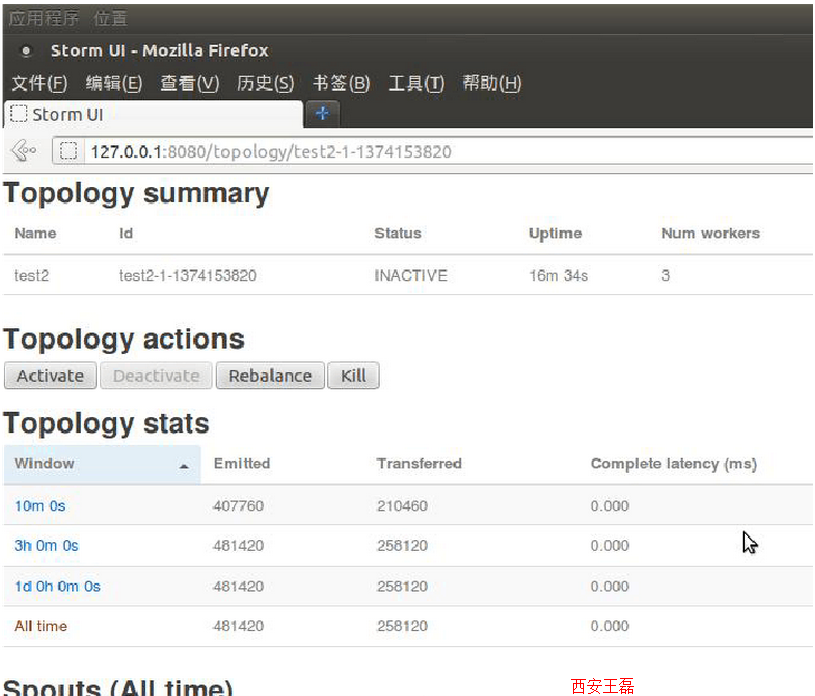
>>bin/storm jar MyFirstStormApp.jar storm.starter.WordCountTopology test2 如果没有错误,就成功提交了,在浏览器中输入http://127.0.0.1:8080,可以看到这个Topology已经在运行了,点击它的名字,可以进入Topology summary:
![]()
如果看到这些数据,就说明我们正确地完成了配置。