同时开工两本书《大话设计模式》和《HADOOP实战》
这不是最后一个知识点,但应该可以在视野方面可以补全得差不多罗。。。
说明:
本博文是人民邮电出版社《大数据分析:点“数”成金》的附录1部分,该书尚未刊发(计划于2013年6月末)。未经授权请勿直接使用,转载请注明出处,谢谢。
内容目录
概述
战略性的Hadoop
完整、先进、拥有强力支持的Hadoop发行版
易用的Hadoop
从批处理转向实时数据流
内建数据压缩机制
多集群支持
筹划、搭建和管理集群
MapR的卷
轻松的规模化管理
可靠的Hadoop
避免作业丢失
用于大规模并具有高可用性的分布式管理节点
Hadoop高可用性及直接挂载NFS
使用快照方便地恢复数据
镜像
更快的Hadoop
高性能架构
性能特色
性能测试
结论
概述
现在每天都有2百万人使用着互联网,每一次通话、每一条推特、每一封电子邮件、每一个下载或每一回购物都产生出有价值的信息。企业越来越依赖于使用Hadoop从迅猛增长的数据中发掘潜藏的价值,促进企业利润的增长。仅仅Orbitz这家旅游网站每月就有460万人次的访问量,社交网站Facebook的用户数量从4亿变为5亿只用了不到半年的时间,而社交游戏网站Zynga近来供应了750万份虚拟情人节蛋糕。这些公司有一个共同点:依靠Hadoop处理海量数据从而推动业务的发展。
Hadoop可不是只能分析点击流,诸如传感器输出数据、视频、日志文件、位置数据、基因信息、行为甚至地震分析等数据,这些只是在各种政府机关及各个层次企业中Hadoop所能够大显身手的一小部分数据源而已。不过Hadoop并不完美,用过Hadoop的人就会明白Hadoop所面临的挑战及其不足之处。目前市面上虽有6种不同的Hadoop发行版可供选择,然而这些发行版不但配置方案一样,而且都存在单点故障、数据丢失的风险及性能瓶颈这样的缺陷。
我们为您带来一个更好的新选择——Apache Hadoop的MapR发行版——最简单、最可靠、最快速的Hadoop发行版。
战略性的Hadoop
在您的组织对Hadoop发行版进行评估和选择时,应该紧密结合自身实际情况来确定评价标准。与发行版有关的重要问题包括:
能够多大程度上方便地在集群中移动数据?
集群能否被用户、工作任务和不同地理分布所便捷地共享?
集群是否既能处理大量文件,也可以使拥护轻松应对访问、保护和安全问题?
对于生产和商务的关键性数据它能否胜任?
怎样对业务的持续性给予支持?
集群能否用从用户或程序错误中恢复数据?
能否对不同集群间的数据进行镜像?
处理能力是否受到批处理应用程序的限制?
管理节点是否会成为性能瓶颈?
系统能否充分利用硬件资源?
MapR所提出的创新方案将使更多企业可以更好地利用大数据分析的能力,本发行版的诸多新特点令Hadoop更易使用、更可信赖并使其性能得以显著提升,从而极大地拓展了Hadoop的应用和适用范围。
完整、先进、拥有强力支持的Hadoop发行版
大量社区开发者已经作出了杰出的贡献,在此基础上MapR又进行了创新。这些新的重要技术进步,使得MapR将Hadoop打造成为一个处理实时数据流的可信交互系统。
MapR对Apache Hadoop API的兼容性达到100%,如兼容MapReduce、HDFS和HBase的所有API。集MapR公司与社区精英的才智于一体且已打有最新补丁,MapR完整发行版不仅经过全面测试还具有MapR公司的支持。如图1所示,MapR提供完整的Hadoop组件体系,包括:
MapR突破了其他Hadoop发行版的限制,无论一个还是几万个节点,MapR都能够轻松应对其上PB级的数据量。
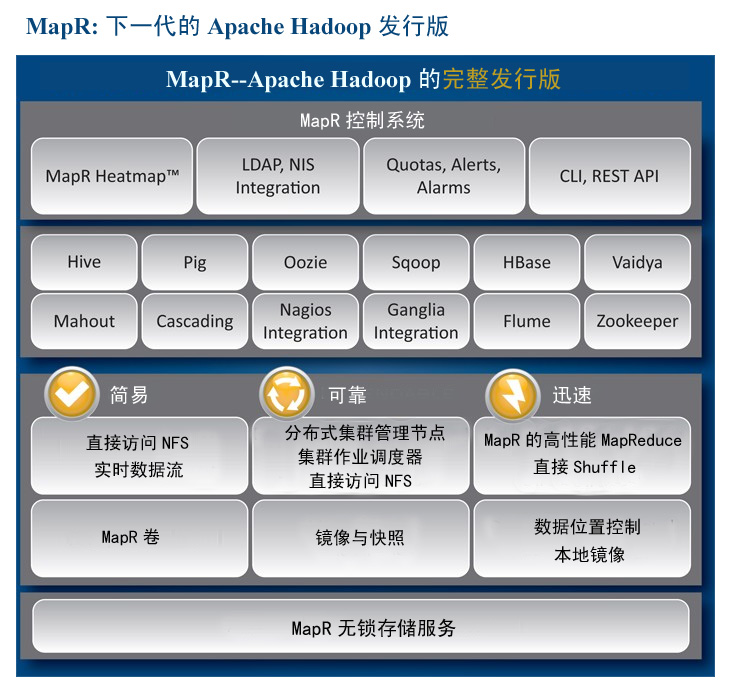
图1 MapR发行版与Apache Hadoop达到100%兼容,并新增了
多种提高易用性、可靠性和性能的创新之处
易用的Hadoop
为了让更多的用户容易地使用,也为了承载更大的任务量,Hadoop必须能让用户简单地使用、部署、运营和管理。MapR公司致力取得关键性技术突破,这些突破使得在集群中转移数据、扩展集群资源及管理大型Hadoop集群这样的任务不但变得更加容易,而且仅需很少的人力便可完成。
从批处理转向实时数据流
其他发行版采用了较为繁琐的批处理方式来管理数据,从而导致数据处理速度的降低。应用程序首先将数据转运到本地或附加的网络存储中。按照预先设定的时间间隔,数据被分批载入传统Apache Hadoop的一次性写入式文件系统中。最后,分析生成结果并将这些结果分批卸载以待进一步的分析。
标准的批处理方式使得在应用程序数据生成与Hadoop集群数据分析之间形成明显时滞。即使通过提高数据加载频率这样的手段可以最大程度地缩小这个时滞,却同时产生了数量众多的小文件,如此之多的小文件对于传统Hadoop扩展性的极限形成了巨大的挑战。此外,其他的Hadoop发行版也受到Hadoop分布式文件系统(HDFS)的限制,类似于常见的CD-ROM,HDFS也是一次性写入的文件系统,不仅不能够对已写入文件进行修改,也不允许对未关闭的文件进行读取。
与这些Hadoop发行版截然相反,MapR基于行业标准的网络文件系统(Network File System,NFS)协议,使用NFS直接存取技术对数据流进行实时读/写。利用该项技术,不但任一远程客户端都可方便地挂载集群文件系统,各个应用服务器还能够将日志或其他数据直接写入集群,而不必将数据先导入本地或网络存储之中。在MapR的无锁存储服务技术的支持下,MapR直接存取NFS技术让用户可以更快更经济地使用Hadoop:
有别与传统Hadoop一次性写入式的文件系统,MapR允许根据用户需要对文件进行修改、覆盖或读取。MapR无锁存储服务技术支持对任意文件进行多个并发的读/写操作。
用户可以使用图形化的文件浏览器访问和操作集群中的数据。使用文件浏览器,用户可以仅仅是浏览文件,也可以点击鼠标来自动打开有关应用程序,还可以拖拽文件或目录而使其移入或移出集群。
可以使用文本编辑器或集成开发环境(Integrated Development Environments,IDEs)直接编辑集群中的文件。
在MapR中,用户可以直接使用标准的命令行工具、UNIX应用程序及其他工具(如Grep、Sed、Tar、Sort和Tail)来处理集群中的数据。对其他Hadoop发行版而言,用户不是需要再进行开发,就是为了使用标准化工具而把数据从集群中拷贝出来。
如Flume之类的日志采集工具经常需要在每台应用服务器上额外运行代理程序,而MapR大大降低了对日志采集工具的依赖。MapR既允许应用服务器直接向集群中写入数据,也允许使用Rsync这样的标准化工具在本地磁盘和集群间同步数据。
应用程序的二进制代码、库及配置文件可以在直接在集群内部存储和访问,并且操作十分简单。
内建数据压缩机制
虽然一般的Hadoop发行版也可以对数据进行压缩,但实现起来既困难又低效。所以通常的做法是,先手工将数据进行压缩再将其拷入集群,而后执行指定的MapReduce任务对压缩的数据进行索引(假设应用程序需要采用并行处理)。为了达到压缩指标,还需要修改应用程序。
MapR的自动压缩功能在提升了性能的同时又能够对重要的存储进行备份。所以说,MapR压缩方案节省了网络I/O带宽和存储空间的占用。
多集群支持
不论是为了分发不同数据或应用程序,还是为了业务的持续性,亦或是出于性能考虑,企业都经常需要操作多个Hadoop集群。MapR内在的设计使其可以支持多集群作业、直接存取、远程镜像和多集群管理。
筹划、搭建和管理集群
正如数据分析需求的不断增长一样,人们对昂贵的集群资源进行有效管理和利用的需求也在不断增长。不论是定位或存取数据,还是对数据施用策略,都对大规模数据的有效管理提出了一个巨大的挑战。集群的架构必须能够支撑应用程序、用户、部门和管理者对海量文件管理的需求。集群的应用和数据必须既能满足技术需求,又得兼顾企业利益。
企业级的应用方案,通常需要对下述问题进行考察:
- 需要怎样的CPU处理能力?(现在和将来)
- 需要怎样的存储能力?(现在和将来)
- 应用程序是否具有高I/O存储需求?
- 具有哪些的数据保护需求?
- 具有哪些业务持续性需求?
- 需要采用何种安全授权和存取控制的手段?
在MapReduce的环境下,上述问题则对Hadoop发行版全面性和灵活性提出了更高的要求。其他Hadoop发行版都是在文件层面上进行策略(如所有者、复制等)管理,事实上它无法处理可能面对的数以百万计的文件。MapR是企业级发行版,具有先进的数据管理功能,正如文章标题中所称,MapR可以让企业简单、容易而又经济地实现业务层次的各项目标。
MapR的卷
MapR的卷让用户便捷地存取和管理集群中的数据。为了容易被组织、管理和确保安全,MapR采用树状结构把相关的文件和目录都分类汇集起来形成卷。MapR的卷具有如下功能:
轻松的规模化管理
管理大规模的Hadoop集群,可视化和自动化非常必要。管理员的确没有时间对服务器进行逐一排障和管理。在高级的数据管理和自我恢复功能帮助下,仅需一个管理员就能轻松管理上千个节点的MapR集群。
MapR的下述特点令管理变得更加容易:
MapR控制系统(MCS)对集群的资源和对集群的操作实现完全可视化。如图2所示,通过集群拓扑的组织(例如数据中心和机架),MCS所包含的MapR Hadoop Heatmap工具被设计用于对上千的节点进行管理,它能够以可视化的形式展现节点的健康情况、服务状态和资源使用状况。若要了解整个集群的健康情况,MapR Hadoop Heatmap让您一看便知。对于数量众多的节点、文件和卷,用户可以利用过滤器直接选取指定的部分,也可以使用群管理器直接运行管理动作。
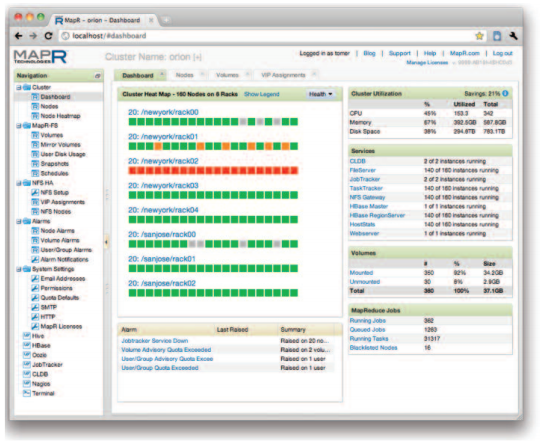
图2 MapR Hadoop Heatmap令每个集群中
所有节点的状态一目了然
可靠的Hadoop
可靠性对于业务的持续运营至关重要,企业对系统的可靠性、可用性和存储能力都有着较高要求——对于生产性数据尤其如此。与其他发行版不同,MapR采用了完全分布式的架构来满足企业级集群运行需求,并提供可信的数据存储以确保在共享环境下数据依旧安全:
避免作业丢失
Hadoop利用作业调度器(JobTracker)跟踪遍布集群不计其数的Mapper和Reduce任务。不幸的是其他发行版中的作业调度器仅在一个节点上运行,使得整个集群存在单点故障的可能性。一旦作业调度器失效,所有正在运行的作业都将失效,而且所有进程也将丢失。此外,管理员首先还必须首先能够探查到问题的根源,然后手动重启作业调度器使集群重新恢复正常。
MapR拥有高可用的作业调度器,它在缩减恢复时间的同时还支持集群自我恢复。若是某个作业调度器失效,任务控制器将自动暂停,此时集群中会有另一个节点上的MapR作业调度器自动启动,任务管理器将等待直至重新连接到新启动的作业控制器。整个过程中所有正在运行的作业或任务都将继续运行,而不会出现作业失效或丢失进程的现象。
用于大规模并具有高可用性的分布式管理节点
在Hadoop中,管理节点追踪并记录集群中数据的所在位置。其他发行版里,即使是规模很大的集群,仍然使用单台服务器来运行管理节点,这会产生很多问题。MapR采用分布式管理节点而解决了这些问题。
Hadoop高可用性及直接挂载NFS
MapR的若干创新使NFS的存取更好用也更稳定。通过使用虚拟IP地址保障集群的高可用性,令Hadoop更符合生产环境的要求。很多集群节点(乃至集群中的所有节点)都能作为NFS网关,同时MapR采用了透明的错误管理机制。用户还可以配置负载均衡使得客户端能够均匀地分布到整个NFS网关中。此外,MapR允许NFS客户端控制数据块的大小(如:64MB、128MB、256MB),并能通过隐藏在每个目录下(类似于Linux中的/proc目录)的一个伪文件进行压缩设置。
使用快照方便地恢复数据
由于每天都要收集并处理海量的数据,因此对如此之多的数据原封不动地备份通常都是不现实的。与此同时,一旦遇到应用程序崩溃或操作失误,企业要求系统必须可以还原特定时间点上的数据。数据副本是其他Hadoop发行版提供的唯一数据保护手段,然而遗憾的是,数据副本只能在磁盘和节点失效的情况起作用,却无法应对整个集群处处都可能发生的用户或应用程序出现的错误。许多Hadoop用户正是由于这些错误才导致其重要数据的丢失。
MapR的快照功能允许组织自行创建还原点对象,通过提供时间点还原镜像来保护系统免受用户或程序的错误之苦。MapR快照由MapR控制系统进行管理并对MapR卷进行操作,它可以被设定成定期计划任务也可以根据需要来随时执行。对某个快照进行恢复就如同浏览快照目录或是把目录或文件拷入当前目录中一样简单。用户可以为个别的卷单独建立快照,也可以为不同的卷设定不同的快照任务计划。
MapR同样支持制订复杂的任务计划。例如,“重要”数据的快照计划可能包括:
MapR快照具备高性能和低磁盘占用等优势:
速度极快。创建一份快照无需对数据进行拷贝,也就是说PB级别的一份快照在几秒钟内即可完成。
原子操作。快照操作都是原子性的,它具有完整的连续性。
不影响写性能。快照操作对写入操作性能没有任何影响。MapR使用的是直写操作,即系统中的每次写动作都将写入至磁盘的一个新块,直接写入操作比复制写入操作效率更高。
最小化存储占用。如果文件不被修改或删除,快照将不会占用任何磁盘空间。所有未作改动的数据块都同时被快照和卷内的即时读/写镜像所共用。因此,MapR的快照技术能够最低限度地占用磁盘空间,在目标数据块写入性能零损失的基础上还可以提供速度极快的分布式快照。
镜像
很多企业都需要对他们的数据创建时间点的物理备份,MapR的镜像功能能够满足企业的这一需求。MapR镜像有两种明显不同的使用形式:远程镜像(正如本小节所描述)应用于集群间的灾难恢复、研发与测试或是共有云与私有云的集成,本地镜像(参见性能小节)则用于同一集群内的负载均衡或性能增强。远程镜像能够支持众多的用例。
更快的Hadoop
MapR最初就被设计为一款具有十分突出的I/O和性能优势的Hadoop发行版。不论集群规模是大还是小、拥有一个还是上千节点,MapR都能提高集群的性能。
高性能架构
从一开始,为了提升性能MapR公司就已经进行了重新设计,打造出的MapR发行版具有多方面的架构特色,包括:
性能特色
不仅仅是先进的架构,MapR的数据位置控制和本地镜像功能还可以让用户对Hadoop应用进行定制,进而使性能得到再次提升。
性能测试
公司已经对MapR发行版进行了多项测试,比如流式I/O、随机I/O及MapReduce性能等,并与其他Apache Hadoop发行版进行比较来评估MapR的性能。结果参见后续小节。
流式I/O性能
作为Hadoop领域内的第一个I/O性能测试基准,DFSIO基准成为了衡量流式I/O性能的有用工具。通过运行一项多mappers和单reducer的MapReduce作业,重点考察mapper平均的转换率(用MB/s表示)。在本测试中,MapR工程师使用10个节点的集群进行测试。如图3所示。
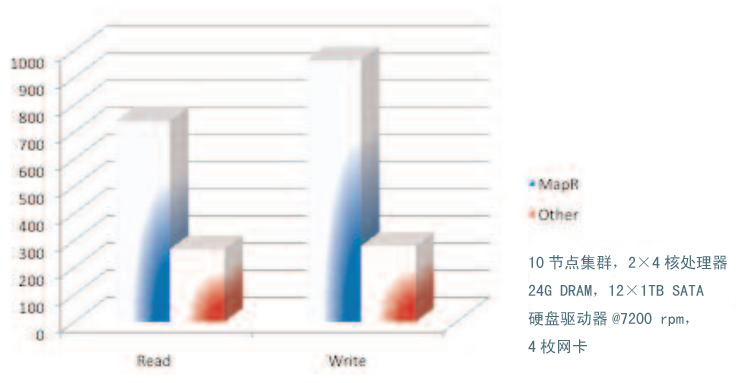
图3 DFSIO测试(数值越大越好)显示MapR比其他发行版快三倍
系统采用10节点集群进行测试,每个节点的主要硬件配置是:两颗四核处理器、24GB内存和12块1TB 7200转SATA硬盘驱动器。正如在图中所示,MapR中的I/O几乎达到硬件设备的物理极限。CPU在测试中基本上处于闲置状态,说明了数据通道是高效的。测试中的写入速度由于校验而稍微有些偏低。
随机I/O性能
有些应用程序需要创建和访问数量众多的文件。为了对这方面性能进行评估,MapR工程师基于NNBench对比测试了MapR和其他发行版的效果,本测试是通过重复如下步骤来进行的:
程序运行在10个相同节点的集群上,每个节点同时部署了传统Apache Hadoop发行版和MapR发行版。为了完成测试关闭了传统发行版中的块报告功能。测试的结果如图4所示。
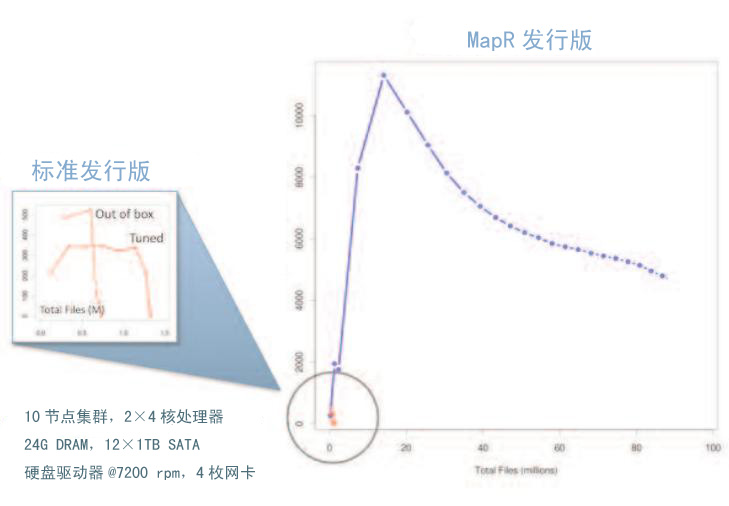
图4 MapR在随机I/O测试中完胜传统发行版
MapR不论是在速度上(纵轴)还是在容量上(横轴)都获得十分出色的结果。实际上,由于差距如此之大以至于传统发行版的结果必须经过放大才能看到。即便关闭了块报告功能,传统发行版最多只能写入150万份文件随后曲线便陡然下降。与此不同,MapR完成9000万份文件写入任务时,速度才从12000份/秒降低到4000份/秒。结果说明MapR的扩展能力是普通发行版的60倍。
MapReduce性能
除了I/O,工程师也想对MapR的数据分析性能进行评估。采用Terasort测试,测验平台仍然是10节点集群进行测试,每个节点的硬件都含有两颗四核处理器、24GB内存和12块1TB 7200转SATA硬盘驱动器。Benchmark测试的结果如图5所示。
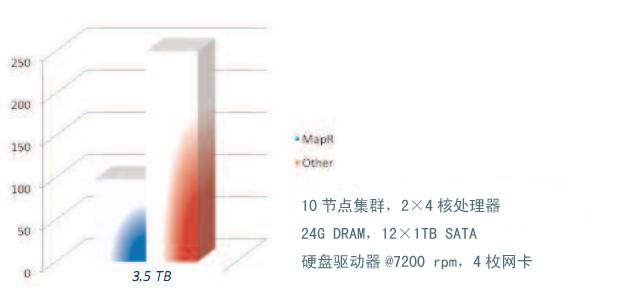
图5 在Terasort测试中(越小越好)MapR的性能几乎领先传统发行版近3倍
| 特性 |
Apache Haoop |
MapR |
| 集群大小 |
1-3,000 |
1-10,000+ |
| 集群中最大数据 |
20 PB |
1,000 PB |
| 最大文件数 |
7千万 |
1万亿 |
| 卷 |
— |
200,000 |
| 性能 |
1x |
3x to 20x |
| 基础设施占用空间 |
1x |
低于50% |
表1 MapR及其他发行版的扩展性比较
结论
MapR相信不断加深的数据处理危机需要战略性地重视Hadoop平台的选择。虽然已经有许多发行版可以拿来使用,但只有与众不同的MapR发行版才突破了其他发行版的各种不足和限制(如表2所示)。MapR具有其他发行版根本不具备的独特特色和功能,包括:
MapR的努力和创新让Hadoop变得更加简单、可靠和快速,使其能够满足现今绝大多数应用的需要,而且我们也做好了迎接未来挑战的准备。
| 项目 |
Apache Haoop |
MapR |
| 组件完整 |
否 |
是。包含通用的工具。 无需昂贵的外部备份存储 |
| 性能 |
1x |
性能提升3至20倍,数据位置控制以及乐观Shuffle |
| 硬件成本 |
1x |
仅有一半的成本,第一年的投资回报率 |
| 扩展性(文件数) |
700万 |
无文件数量限制。MapR分布式的管理节点增强了扩展性 |
| 操作简便 |
否 |
MapR热图、GUI、警告和过滤器 |
| 数据连续加载并能访问结果 |
否 |
MapR实时Hadoop平台拥有MapR直接NFS存取工具 |
| 可靠性和业务连续性 |
否 |
高可用的MapR作业调度器、MapR分布式的管理节点、用于时间点还原的MapR快照功能、用于灾难恢复的MapR镜像功能 |
| 共享集群的可信性 |
否 |
提醒、警告、配额、用户、用户组以及系统资源隔离 |
| 开通服务 & 使用监控 |
否 |
MapR卷、配额和用户 |
| 多数据中心 |
否 |
跨越集群和数据中心的MapR镜像。使用简单的GUI工具管理多个集群 |
| 服务支持 |
可用 |
是 |
表2 MapR及其他发行版的扩展性比较
MapR技术公司打造出了业内最快、最为可靠、也最易用的Aapche Hadoop发行版。本公司致力于推进Hadoop平台及其生态系统,使更多企业能够利用大数据分析的威力获得竞争优势。您可以访问公司网站www.mapr.com来获取更多信息。
© 2011. MapR. Con?denial. v1 05.11
译者:五岳之巅(刘凯)
2013年4月

微信关注我们
转载内容版权归作者及来源网站所有!
低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service 的首字母简称,一个易于构建 AI Agent 应用的动态服务发现、配置管理和AI智能体管理平台。Nacos 致力于帮助您发现、配置和管理微服务及AI智能体应用。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据、流量管理。Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。
Spring框架(Spring Framework)是由Rod Johnson于2002年提出的开源Java企业级应用框架,旨在通过使用JavaBean替代传统EJB实现方式降低企业级编程开发的复杂性。该框架基于简单性、可测试性和松耦合性设计理念,提供核心容器、应用上下文、数据访问集成等模块,支持整合Hibernate、Struts等第三方框架,其适用范围不仅限于服务器端开发,绝大多数Java应用均可从中受益。
Rocky Linux(中文名:洛基)是由Gregory Kurtzer于2020年12月发起的企业级Linux发行版,作为CentOS稳定版停止维护后与RHEL(Red Hat Enterprise Linux)完全兼容的开源替代方案,由社区拥有并管理,支持x86_64、aarch64等架构。其通过重新编译RHEL源代码提供长期稳定性,采用模块化包装和SELinux安全架构,默认包含GNOME桌面环境及XFS文件系统,支持十年生命周期更新。
Sublime Text具有漂亮的用户界面和强大的功能,例如代码缩略图,Python的插件,代码段等。还可自定义键绑定,菜单和工具栏。Sublime Text 的主要功能包括:拼写检查,书签,完整的 Python API , Goto 功能,即时项目切换,多选择,多窗口等等。Sublime Text 是一个跨平台的编辑器,同时支持Windows、Linux、Mac OS X等操作系统。
扫码在手机上查看文章
扫描二维码,手机阅读更方便
有任何问题或合作意向欢迎联系我们
Email: 99873273@qq.com
QQ: 99873273