本篇介绍java基础中常用API使用,当然只是简单介绍,围绕重要知识点引入,巩固开发知识,深入了解每个API的使用,查看java API文档是必不可少的。
一、java.lang包下的API
Java常用基础包,在开发中会自动导入到代码环境中,不需要import。
1.基本数据类型/包装类
(1)基本数据类型:byte、short、int、long、float、double、char、boolean
(2)包装类:
- Byte:–提供了将字节数据转换为其他类型的方法,从Number抽象类继承过来.decode:将各种进制的数据内容的字符串,转换为十进制标识的字节类型,数字进制的标识符:无标识符:按十进制转换;ox、OX、#:按十六进制转换;o:按八进制转换.
- Short、Integer –将short、Integer装换为其数据类型的方法,从Number抽象类继承过来。decode与Byte类中的decode方法一样可进行不同进制的装换。parseShort、parseInt、parseByte一样,可以进行不同的进制装换值。
注意:Integer十进制转其他进制的方法:toBinaryString()、toHexString()、toOctalString()。
- Float、Double –isInfinite():用于判断数字是否有趋近无穷大,无法完整描述的情况。isNaN():判断浮点数据是否为有效数据(浮点类型参与运算后用于判断是否有效)
注:valueOf、parseXXX方法可以将字符串形式的值装换为数字。
(3)包装类与基本数据类型之间可以实现数据类型的自动转换,即装箱和拆箱。
装箱:自动将基本数据类型转换为其对应的包装类.
拆箱:自动将包装类型转换为基本数据类型.
2.数学运算类:Math;其重要方法有:
abs() :获取绝对值函数.
acos()、asin():反余弦、反正弦函数(以弧度为参数值PI结合运算).
cbrt():立方根函数.
cos()、sin():三角余弦、三角正弦函数(以弧度为参数值PI结合运算).
max()、min():获取两个数值中的最大值或最小值.
log()、log10():对数.
random():获取随机数.
round():四舍五入(获得整形值).
floor():得到小于该数的最小整数.
ceil():得到大于该数的最大整数.
sqrt():平方根.
3.字符串类
(1)String:不需要通过new就可以直接创建String对象;+运算符可以用来拼接String内容.
方法:
startsWith():字符串是否由指定字符开头.
endsWith():字符串是否由指定字符结尾.
indexOf():返回子串在父串中第一次出现的下标(从左起).
lastIndexOf():返回子串在父串最后一次出现的下标(从右起).
split():按特殊字符拆分字符内容
replace():用新字符串内容,替换父串中原有的字符串内容.
matches():字符验证方法。
正则表达式:由一组通用的特殊字符所组成的一套字符串内容验证规则,String通过matchs()方法来使用正则表达式验证字符串内容是否合要求.
语法-边界匹配器:
^:行的开头,代表一个正则表达式的开始.
$:行的结尾,代表一个正则表达式的结束.
\b:标识某一个单词的开头或结尾.
字符:
[abc]:a或b或c的任意一个.
[^abc]:除a、b、c以外的任意字符.
[a-zA-Z]:所有字母(大小都包括).
[a-d[m-p]]:a到d或m到p([m-p]将该内容作为整体)
[a-z&&[def]]:a-z和def两个表达式都满足.
[a-z&&[^bc]]、[a-z&&[^m-p]]
[0-9]
预定义字符:
.:代表任意字符.
\d:字符内容只能是[0-9]的数字.
\s:空白字符.
\w:所有字符大小写、下划线、数字
反向字符:\D、\S、\W
数量词:?:一次或一次也没有.
*:零次或多次.
+:一次或多次.
{n}:n代表一定要出现的次数
{n,m}:n<=出现次数<=m.
拓展:
零宽断言\捕获-是使用正则表达式来获取字符串中对应内容的所在位置.(不能结合String的matchs方法),而应该结合String的replaceAll、replaceFirst方法使用,用来找到替换需要替换的内容)。语法:
(?=exp):若字符串中有内容的结尾与exp匹配,则满足该断言.
(?<=exp):若字符串中的内容的开头与exp匹配,则满足该断言.
(?!=exp):若字符中的内容的结尾与exp不匹配,则满足该断言.
(?<!exp):若字符串的内容的开头与exp不匹配,则满足该断言.
(2)StringBuffer:对于内容变动较大的字符串内容处理能力较好(线程安全)
常用方法:append()、delete()、insert()
与String的区别:String类,在有新内容追加时,是结合原有字符串内容创建新的字符串对象(性能较低)
(3)StringBuilder:对于内容变动较大的的字符串内容处理能力较好(线程不安全 JDK1.5)
常用方法:append()、delete()、insert()
注意:StringBuffer和StringBuilder为可变字符串类型:其字符内容可以灵活变动(追加、删除、插入)
(4) 其他程序的调用类:
Runtime:
作用:获取java虚拟机的运行信息(可使用的CPU数量、所分配的内存大小、空闲内存).
特点:一个虚拟机环境内有且仅有一个Runtime对象.
方法:
static getRuntime():获取虚拟机对应的运行时信息.
static exec(String):启动子进程.
Process:用于描述被JVM启动的一个子进程信息,可以通过Process让java代码与子进程通信.
二、java.util包下的API
1.日期或时间类型:
(1)Date:java平台用于描述时间信息(包括用于精确描述年、月、日、小时、分钟、毫秒信息)的基类;常用方法:
after\before:日期比较方法.
getTime():获取日期信息的long格式值.
setTime(long):根据日期的long值,重新设置日期的时间点.
(2)Calendar:基于通用日历规则,提供了日期运算方法:
set(int,int):向对应的日期级别设置(第一个参数用于日期级别).
get(int):通过日期级别常量,获取当前日期的相关信息.
getDisplayName(int,int,locale):按指定格式和区域语言习惯,来返回日期的描述内容(中文只对月份、星期有效).
getFirstDayOfWeek():返回当前日期对象一周的第一天是星期几(默认1==星期天).
static getInstance():构造日历对象实例.
getTime():将日历对象转换成Date类型.
setTime():将date类型转换为日历类型.
getTimeInMillis():将日历类型转换了long格式的数据.
setTimeInMillis(long):将long格式的日期类型转换成日历类型.
add(int,int):可以在指定的日期级别上,对日期信息进行向前或者向后滚动(第二个参数正数向后增长,负数向前增长)
3.基于经典数据结构的集合框架
集合对象:弥补传统的数组在批量数据存储中和访问上的不足,提供一组基于经典数据结构,并提供了对应操作方法的API来满足编程开发中对批量数据的操作要求.
(1)Iterable(接口):JDK1.5以后加入的API,为集合框架满足foreach语句提供类型的定义.
方法:iterator()– 基于集合内容,生成迭代器(可以提供方法依次访问集合中的对象).
(2)Collection(接口):JDK平台上,所有集合框架的根接口,是用于存储多个对象(数据)的集合类型,数据可以是任何合法类型,可以有各种存储验证(是否为空,是否重复,是否有序);方法:
add(Objectobj):向集合追加新的对象
addAll(Collection colletion):将另一个集合的内容,追加到当前集合内.
contains(Object c):判断对象是否为集合的成员.
containsAll(Collections c):判断两个集合是否存在包含情况.
Iterator():将集合内的数据转换为迭代器的格式来存储,迭代器便于按顺序访问集合内的元素.
retainAll(Collection c):留下两个集合都包含的元素.
size():集合中元素的个数.
toArray():将集合对象的内容装换为对象数组.
(3)List:有序的集合
特点:通常允许重复的元素,允许null元素,有序,对应元素都有下标来标识,没有长度限制,可以自动的根据需要改变长度.
. 方法:get(intindex):通过下标获取集合列表中的某一个元素.
set(int index,E element):向列表中的指定项中设置元素(若原下标位置有值,则会替换).
subList(int fromIndex,inttoIndex):截取集合列表中的一部分生成新的列表对象.
实现类:
特点:底层基于数组来实现列表的功能,内部用于存储数据的结构是一个Object[](Object[]数组的默认大小为10)。
建议:其ArrayList的初始化大小,尽可能根据实际操作数据的大小来设定(避免因数组增长导致效率低下的问题).不善于对内容变动较大的集合数据提供存储。
特点:底层基于链表的结构来实现存储功能.(链表是非常灵活的顺序存储结构,基于指针,将数据相互串联起来)。
建议:在数据经常需要进行修改的情况下使用.若只需要对数据进行查询、获取等操作,则效率比不上ArrayList。
特点:是线程安全的API(让多个同时执行线程有序的访问Vector中的数据,但会消耗相对应的内存)。
(4)Set:不包含重复元素的集合
特点:不允许有重复元素,最多包含一个null元素,不一定是有序存储。
方法:Collection接口上定义的方法、add()、addAll()、iterator()、remove()
实现类:
- HashSet – 实现基于Hash表来维护数据,不保证数据的顺序不变,但可以保证数据的唯一性。(保存数据:通过Hash表来保存数据,但不会保存重复的数据)
- TreeSet –按照二叉树的结果来存放数据,保证数据的顺序;采用红黑树(二叉树):小的值放在左节点,大的值放在右节点.获取数据时,采用中序访问节点,将数据内容按大小排列比大小:会使用对象的compareTo()方法比较两个对象的大小由TreeSet保存的对象,最好能提供对Compareble接口的实现,并给出compareTo方法的实现。
- LinkedHashSet
特点:基于Hash表来存放数据,但会对数据的插入顺序进行维护,按照数据放入Set集合的顺序给输出来,将对象在hash表中的hash值,按插入顺序保存在链表中,在生成的Iterator时,根据链表的结构一次访问获取对象,操作性能较低,在大数据量的集合操作上不建议使用。
(5)Iterator :将数据有序的组织在一起,并提供按序访问的方法:
hasNext():判断迭代器是否还有遍历到的元素
next():可以得到向下遍历的对象.
(6)Map :基于键-值映射的关系来搭建存储结构,在整个结构中使用key值来唯一标识对象.(在JDK1.2之后出现用于替换原有API中的Dictionary类的作用)。常用方法: put(key,value)
get(key)
remove()
values():将结构中存储的所有值都以对象的形式返回
keySet():将结构中的所有key值,以set结构返回.
实现类:
HashMap
TreeMap: –底层基于二叉树结构来存储数据,会根据key来作为二叉树的节点关键属性来进行排序操作,按key值的从小到大进行排列
(7)Dictionary –也是基于键-值结构,但已经过期。
实现类:
HashTable:基于哈希表实现键值对应,是一个线程安全的API。
Properties:提供一个属性信息的键值对存储结果,可以与*.properties文件使用(key:属性名;value:属性值).
(8)Collections:定义了多种操作集合对象的方法(查找、插入、排序等方法)
sort()、binarySearch()、copy()、max()、min()、reverse()
三、java.io包下的API
这个包下的api即java输入输出操作API,什么是
输入输出操作?即向程序输入信息,向程序外部输出信息,数据被输入或者是输出的基础单位是字节byte,输入输出流按流的功能分可分为:
低级流(节点流):自己具有流的写入或者读取能力的流.
高级流(功能流):基于低级流的功能,实现流操作功能的扩张.
1.字节流
(1)InputStream(输入流) :表示字节输入流的所有类的超类,常用方法有:
available() :获取总字节数,获取缓存区中的字节个数
close():负责释放IO资源,关闭流操作.
mark():在输入输出流的字节位置上设标记,为后面reset反复读取该段字节做准备.
reset():将流的操作重新定位
markSupported():用于判断mark方法或reset方法是否可用.
int read():用于读取一个字节信息:返回值是读取到的字节,若读到文件末尾,则返回-1.
int read(byte[] b):将字节读入到byte[]数组中:返回值是读取到的字节数,若读到文件末尾,则返回-1.(将字节读取到byte[]数组中第off位开始之后的位置,读取长度为len个字节)
(2)OutputStream:表示输出字节流的所有类的超类,常用方法有:
close():关闭流
flush():将缓存中的字节,清空输出.
write(byte[] b):将字节数组中的内容输出
write(int b):将单个字节输出.
write(byte[] b,intoff,int len):将字节数组中从off开始的信息输出,共输出len个字节.
(3)FileInputStream extends InputStream –(文件输入流)
(4)FileOutputStreamextends OutputStream –(文件输出流),构造方法:FileOutputStream(Stringname,boolean append),其中append为ture时:追加内容到文件尾部.
(5)FilterInputStream:输入过滤流,负责在其他流基础上扩展新的功能
(6)FilterOutputStream:输出过滤流,负责在其他基础上扩展新的功能.
(7)BufferedInputStream:为流操作提供字节缓存,减少直接申请的IO读取的次数;实现原理是在内存中创建了字节数组,缓存字节信息.
(8)BufferedOutputStream :为流操作提供字节缓存,减少直接申请IO写出的次数.
(9)DataInputStream:以java基本数据类型的格式读取信息.
(10)DataOutputStream :以java基本数据类型的格式输出信息.
(11)ObectInputStream:对象流输入,可以将对象信息整体读入.(注意:对象必须实现java.io.Serializable可序列化)
(12)ObjectOutputStream:对象流输出,可以将对象信息整体输出(注意:对象必须实现java.io.Serializable可序列化).
注意:对象流使用的场景是大型数据的缓存,缓存一般会放在内存中。把数据量较大,且交互次数较低的数据放到文件中保存,再从文件中将数据还原内存;或者放在分布式系统(通过网络通信);如:发送远程调用的请求信息,远程调用的处理结果.
(13)压缩流(基于字节流),API:java.util.zip.*包下的类,是封装基于ZIP标准进行无损压缩的API
ZipOutputStream:基于zip格式生成压缩文件,方法:putNextEntry(),closeEntry()
ZipInputStream:读取ZIP文件内容.可以理解wie解压缩.
ZipEntry:在压缩内容中代表一项压缩条目(压缩条目是一个独立的信息存储单元,一般用于将某一个文件的内容单独存储起来).
2.字符流
(1)Reader:表示字符输入流的所有类的超类,常用方法有:read()、close()。
(2)Writer:表示字符输出流的所有类的超类,常用方法有:write()、flush()、close()。
(3)BufferedReader/BufferedWriter:为流操作提供字符缓存,减少直接申请的IO读取/写入的次数。
拓展:File :系统上一个文件资源,包括文件(*.txt、*.exe、*.doc等)和文件夹(用于组织和存放其他文件信息);作用:
- 获取文件夹的子文件信息—listFile()
- 获取文件的属性,如getName() –获取文件的名字.
- 判断是否为文件目录—isDirectory()返回结果是ture为目录,false为其他内容.
- 判断是否为文件—isFile()返回结果是ture为文件,false为其他内容.还可以修改文件和删除文件.
拓展:设计模式,是指在编程的开发过程中,被反复论证所总结出来的编程经验.这些经验被认定为解决具体问题的最佳方案.
eg:装饰模式—面向对象的常用模式之一.符合开关原则:原有代码不发生任何改变,而对原有代码进行扩展,结构:
目标类(FileInputStream、FileOutputStream等)。
装饰类(BufferdInputStream、BufferedOutStream等),与目标类都有相同的父类或接口。
用途:改进原有API的功能—修改原有的方法,丰富原有API的实现—能实现的功能更多。
最纯的装饰模式:目标类和装饰类从结构上一模一样(BufferedInputStream\BufferedOutputStream)。
装饰的”另类”:对类的结构做出调整,如ObjectInputStream\ObjectOutputStream(readObject()\writeObject() )和DataInputStream\DataOutputStream( readXXX()\writeXXX() )。
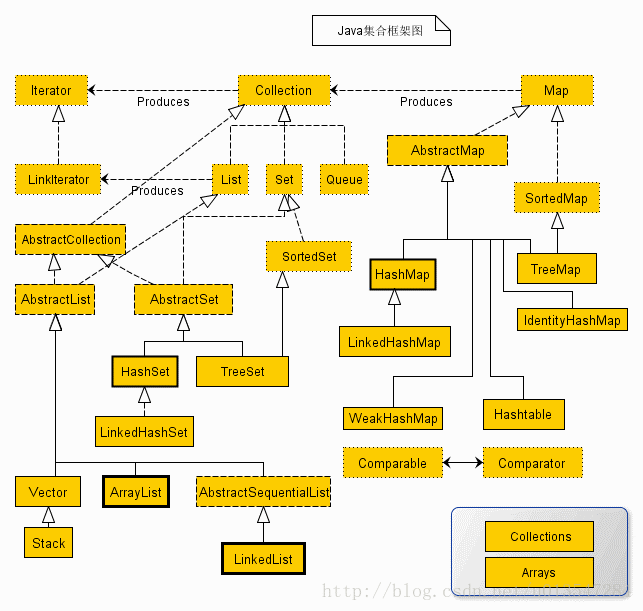
二、JAVA集合框架
Java集合类库将接口和实现分离。当程序使用集合时,一旦构建了集合就不需要知道究竟使用了哪种实现。因此,只有在构建集合对象时,使用具体的类才有意义。可以使用接口类型存放集合的引用。利用这种方法,一旦改变想法,可以轻松使用另外一种不同的实现,只需在对象创建处修改即可。
![]()
java.util.Collection<E>
| Iterator<E> iterator() |
返回一个用于访问集合中每个元素的迭代器 |
| int size() |
返回当前存储在集合中的元素个数 |
| boolean isEmpty() |
如果集合中没有元素,返回true |
boolean contains(Object obj)
boolean containAll(Collection<? extend E> other) |
如果集合中包含相等对象,返回true |
boolean add(Object element)
boolean addAll(Collection<? extend E> other)
|
将一个元素添加到集合中,集合改变返回true |
boolean remove(Object element)
boolean removeAll(Collection<?> other)
|
删除相等元素,成功删除返回true |
java.util.Iterator<E>
| boolean hasNext() |
如果存在可访问的元素,返回true |
| E next() |
返回将要访问的下一个对象 |
| void remove() |
删除上次访问的元素 |
Java库中具体集合
| ArrayList |
一种可以动态增长和缩减的索引序列 |
| LinkedList |
一种可以在任何位置进行高效插入和删除操作的有序序列 |
| ArrayDeque |
一种用循环数组实现的双端队列 |
| HashSet |
一种没有重复元素的无序集合 |
| TreeSet |
一种有序集 |
| EnumSet |
一种包含枚举类型值的集合 |
| LinkedHashSet |
一种可以记住元素插入次序的集 |
| PriorityQueue |
一种允许高效删除最小元素的集合 |
| HashMap |
一种存储键/值关联的数据结构 |
| TreeMap |
一种键值有序排列的映射表 |
| EnumMap |
一种键值属于枚举类型的映射表 |
| LinkedHashMap |
一种可以记住键/值项添加次序的映射表 |
| WeakHashMap |
一种其值无用武之地后可以被垃圾回收期回收的映射表 |
| IdentityHashMap |
一种用==而不是用equals比较键值的映射表 |
1、List
List接口扩展自Collection,它可以定义一个允许重复的有序集合,从List接口中的方法来看,List接口主要是增加了面向位置的操作,允许在指定位置上操作元素,同时增加了一个能够双向遍历线性表的新列表迭代器ListIterator。List接口有动态数组(ArrayList类)和双端链表(LinkedList类)两种实现方式。
java.util.List<E>
ListIterator<E> listIterator()
ListIterator<E> listIterator(int index)
|
返回一个列表迭代器
迭代器第一次调用next返回给定位置元素 |
void add(int i, E element)
void addAll(int i, Colletion<? extend E> elements) |
向集合指定位置添加元素 |
| E remove(int i) |
删除给定位置元素并返回 |
| E get(int i) |
获得给定位置元素并返回
|
E set(int i, E element)
|
设置给定位置元素并返回原来的元素 |
int indexOf(Object element)
int lastIndexOf(Object element) |
返回与指定元素相等元素在列表中第一次出现的位置
返回与指定元素相等元素在列表中最后一次出现的位置
|
java.util.ListIterator<E>
| void add(E Element) |
在当前位置添加一个元素 |
| void set(E Element) |
用新元素代替next或previous上次访问的元素 |
| boolean havaPrevious() |
反向迭代列表时是否还有可供访问的值 |
| E previous() |
返回前一个对象 |
| int nextIndex() |
返回下一次调用next时返回的元素索引 |
| int previousIndex() |
返回下一次调用previous时返回的元素索引 |
java.util.ArrayList<E>
ArrayList<E>()
|
构造一个空数组列表 |
| boolean add(E obj) |
在数组列表尾端添加一个元素,永远返回true |
| int size() |
返回存储在数组中的当前元素数量 |
| void set(int index, E obj) |
设置数组列表指定位置的值 |
| E get(int index) |
获的指定位置的元素值 |
| void add(int index, E obj) |
向后移动元素,插入元素 |
| E remove(int index) |
删除一个元素,并将后面元素前移 |
java.util.LinkedList<E>
LinkedList()
LinkedList(Colletion<? extend E> elements) |
构造一个链表 |
void addFirst(E element)
void addLast(E element) |
添加元素到表头或表尾 |
E getFirst()
E getLast() |
返回表头或表尾的元素
|
E removeFirst()
E removeLast() |
删除表头或表尾的元素并返回 |
2、Set
Set接口扩展自Collection,它与List的不同之处在于,规定Set的实例不包含重复的元素。在一个规则集内,一定不存在两个相等的元素。AbstractSet是一个实现Set接口的抽象类,Set接口有三个具体实现类,分别是散列集HashSet、链式散列集LinkedHashSet和树形集TreeSet。
java.util.HashSet<E>
HashSet()
HashSet(Colletion<? extend E> elements)
HashSet(int initialCapacity) |
构造散列表 |
java.util.Linked
HashSet<E>
LinkedHashSet是用一个链表实现来扩展HashSet类,它支持对规则集内的元素排序。HashSet中的元素是没有被排序的,而LinkedHashSet中的元素可以按照它们插入规则集的顺序提取。
java.util.TreeSet<E>
TreeSet扩展自AbstractSet,并实现了NavigableSet,AbstractSet扩展自AbstractCollection,树形集是一个有序的Set,其底层是一颗树,用红黑树实现,这样就能从Set里面提取一个有序序列了。在实例化TreeSet时,我们可以给TreeSet指定一个比较器Comparator来指定树形集中的元素顺序。树形集中提供了很多便捷的方法。
3、队列
java.util.Queue<E>(接口)
boolean add(E element)
boolean offer(E element) |
如果队列没有满,将元素添加到队列尾部 |
E remove()
E poll() |
如果队列不为空,删除并返回这个队列头部元素 |
E element()
E peek() |
如果队列不为空,返回这个队列头部元素 |
java.util.Deque<E>
接口Deque,是一个扩展自Queue的双端队列,它支持在两端插入和删除元素,Deque接口由ArrayDeque和LinkedList这两个类实现,所以通常我们可以使用LinkedList来创建一个队列。PriorityQueue类实现了一个优先队列,优先队列中元素被赋予优先级,拥有高优先级的先被删除。
java.util.ProrityQueue<E>
优先级队列中的元素可以按任意顺序插入,却总是按照排序的顺序进行检索。优先级队列由堆实现。堆是一个可以自我调整的二叉树,对树执行添加和删除操作,可以让最小元素移动到根(最小堆),而不必花费时间对元素进行排序
4、Map接口
Map,图,是一种存储键值对映射的容器类,在Map中键可以是任意类型的对象,但不能有重复的键,每个键都对应一个值,真正存储在图中的是键值构成的条目。
java.util.Map<K,V>
V get(Object key)
|
获得与键对应的值 |
V put(K key, V value)
V putAll(Map<? extends K, ? extends V> entries) |
将键与对应的值关系插入到映射中 |
boolean containKey(Object key)
boolean containValue(Object value) |
查询 |
java.util.HashMap<K,V>
HashMap是基于哈希表的Map接口的非同步实现,继承自AbstractMap,AbstractMap是部分实现Map接口的抽象类。在之前的版本中,HashMap采用数组+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。但是当链表中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,HashMap采用数组+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
java.util.LinkedHashMap<K,V>
LinkedHashMap继承自HashMap,它主要是用链表实现来扩展HashMap类,HashMap中条目是没有顺序的,但是在LinkedHashMap中元素既可以按照它们插入图的顺序排序,也可以按它们最后一次被访问的顺序排序。
java.util.TreeHashMap<K,V>
TreeMap基于红黑树数据结构的实现,键值可以使用Comparable或Comparator接口来排序。TreeMap继承自AbstractMap,同时实现了接口NavigableMap,而接口NavigableMap则继承自SortedMap。SortedMap是Map的子接口,使用它可以确保图中的条目是排好序的。在实际使用中,如果更新图时不需要保持图中元素的顺序,就使用HashMap,如果需要保持图中元素的插入顺序或者访问顺序,就使用LinkedHashMap,如果需要使图按照键值排序,就使用TreeMap。
5、其他集合类
下面主要介绍一下其它几个特殊的集合类,Vector、Stack、HashTable、ConcurrentHashMap以及CopyOnWriteArrayList。
java.util.Vector<E>
用法上,Vector与ArrayList基本一致,不同之处在于Vector使用了关键字synchronized将访问和修改向量的方法都变成同步的了,所以对于不需要同步的应用程序来说,类ArrayList比类Vector更高效。
java.util.Stack<E>
Stack,栈类,是Java2之前引入的,继承自类Vector。
java.util.HashTable
HashTable和前面介绍的HashMap很类似,它也是一个散列表,存储的内容是键值对映射,不同之处在于,HashTable是继承自Dictionary的,HashTable中的函数都是同步的,这意味着它也是线程安全的,另外,HashTable中key和value都不可以为null。
java.util.ConcurrentHashMap
ConcurrentHashMap是HashMap的线程安全版。同HashMap相比,ConcurrentHashMap不仅保证了访问的线程安全性,而且在效率上与HashTable相比,也有较大的提高。
java.util.CopyOnWriteArrayList
CopyOnWriteArrayList,是一个线程安全的List接口的实现,它使用了ReentrantLock锁来保证在并发情况下提供高性能的并发读取。
java.util.CopyOnWriteArraySet
CopyOnWriteArraySet,是一个线程安全的set接口的实现,它使用了ReentrantLock锁来保证在并发情况下提供高性能的并发读取。
ConcurrentLinkedQuerue是一个先进先出的队列。它是非阻塞队列。
ConcurrentSkipListMap可以在高效并发中替代SoredMap(例如用Collections.synchronzedMap包装的TreeMap)。
ConcurrentSkipListSet可以在高效并发中替代SoredSet(例如用Collections.synchronzedSet包装的TreeMap)。
6、泛型集合算法
6.1 排序
| static <T extends Comparable<? super T>> void java.util.Collections.sort(List<T> elements,[new Comparator<T>(){ public int compare(T o1, T o2){return …} } ]) |
对列表元素排序 |
6.2 查找
| static <T extends Comparable<? super T>> int java.util.Collections.binarySearch(List<T> elements, T key) |
二分查找key,返回对象索引 |
6.3 其他
static <T> java.util.Collections.min(Collection<T> elements, Comparator<? super T> c)
static <T> java.util.Collections.max(Collection<T> elements, Comparator<? super T> c)
|
查找最小值/最大值 |
三、并发部分API
java.lang.Runnable
java.lang.Thread
Thread()
Thread(Runnable target) |
构造器 |
| void start() |
启动线程 |
| void run() |
如果没有重写,调用关联Runnable的run方法 |
| void interupt() |
中断线程(中止阻塞状态,对运行线程无作用) |
| void setPriority(int newPriority) |
设置优先级(1-10,默认5) |
static void yield()
static void sleep(long millis) |
使当前线程处于让步状态(让步于同优先级或高优先级线程)
休眠 |
| void setDaemon() |
设置为守护线程 |
| Thread.State getState() |
获得线程当前状态 |
锁对象
ReentrantLock myLock = new ReentrantLock();
mylock.lock();
try{
critical section
}finally{
mylock.unlock();
}
条件对象
private ReetranLock mylock = new ReetranLock();
private Condition sufficientFunds = mylock.newCondition()
public void transfer(int from, int amount)
{
mylock.lock();
try{
while(account[from] < amount){
sufficientFunds.await();
}
...
sufficientFunds.singalAll();
}finally{
mylock.unlock();
}
}
synchronized关键字(内置锁)
格式1:synchronized 方法
格式2:synchronized(obj){}
使用synchronized如何设置条件变量
| void notifyAll() |
解除在对象上调用wait方法的线程的阻塞状态 |
| void wait() |
导致线程进入等待状态 |
volatile域
volatile只提供可见性(在线程工作内存中被修改后立即写入到主存中),不提供原子性。
使用final变量可以保证可见性:构造函数完成时即不变,未完成构造期间对其他线程不可见。
java.lang.ThreadLocal<T>
作用:将内存共享变量变为线程拷贝变量
Executor类执行器
1)调用Executors类(工厂类)中静态工厂方法newCacherThreadPool
2)调用submit提交Runnable或Callable对象
3)当不再提交任何任务时,调用shutdown
![]()
转载自:
https://blog.csdn.net/u013547284/article/details/71158100
https://blog.csdn.net/chenchaoqingtian/article/details/50771142