背景
很多优秀的程序员和技术人员喜欢写技术文章和技术博客,通过这样的方式分享传播知识和经验,扩大自己的知名度和影响力,吸引粉丝关注,甚至有些技术博主还通过写文章来获取广告收入,很多优秀的博主还通过这种方法获得了出版书的机会以及工作机会。因此,写技术文章是一件非常值得投入的事情,帮助了自己,也让大众受益。
但是,写技术文章通常也很耗时,特别是一些优质文章,不仅需要旁征博引、构思文章结构、照顾读者受众,还需要做很多前期工作,例如搭建环境、写demo代码、测试代码等等。一篇优质技术文章通常需要3-6个小时来完成。然而,花了很多时间来写文章,最终发布出来的文章得不到很多人的关注是一件相当令人沮丧的事情。我们认为,优质文章值得获取关注和传播,让更多的技术工作者通过阅读文章获取知识获益。
每个技术博主都有自己喜欢的技术媒体平台,例如掘金、CSDN、微信公众号等等。很多技术博主也喜欢将文章发布在不同的平台上,寻求最大的关注度,同时也防止自己辛辛苦苦写的文章被别人复制粘贴盗版过去。然而,在多个平台上发文是一件麻烦的事情:博主需要同时登陆多个媒体平台,将自己的文章复制一个一个粘贴过去;更麻烦的是,有些平台只支持Markdown,有些平台只支持富文本,博主需要在这两者之间来回转换,这增加了工作量。
一文多发平台ArtiPub就解决了这样的问题。下面我们将介绍一下近日刚上线的开源一文多发平台ArtiPub。
ArtiPub简介
ArtiPub (Article Publisher的简称,意为"文章发布者")是一款开源的一文多发平台,可以帮助文章作者将编写好的文章自动发布到掘金、SegmentFault、CSDN、知乎、开源中国等技术媒体平台,传播优质知识,获取最大的曝光度。ArtiPub安装简单,提供了多种安装方式(Docker、NPM、源码),可以一键安装使用,安装一般只要5分钟。
ArtiPub首发版目前支持文章编辑、文章发布、数据统计的功能,后期我们会加入存量文章导入、数据分析的功能,让您更好的管理、优化您的技术文章。此外,我们还会接入更多媒体渠道,真正做到让文章随处可阅。
用户使用ArtiPub也很简单,只需要在浏览器上打开ArtiPub的Web界面,将文章以Markdown的形式输入到编辑器,然后点击一键发布,等待不到1分钟,文章就自动同步到各大技术媒体平台了。此外,文章的阅读、点赞、评论数据还将周期性的被同步回来,让作者可以近实时看到文章的传播情况。
平台一览
下面是平台的Web界面截屏,当然我们更推荐您去实际安装体验ArtiPub。
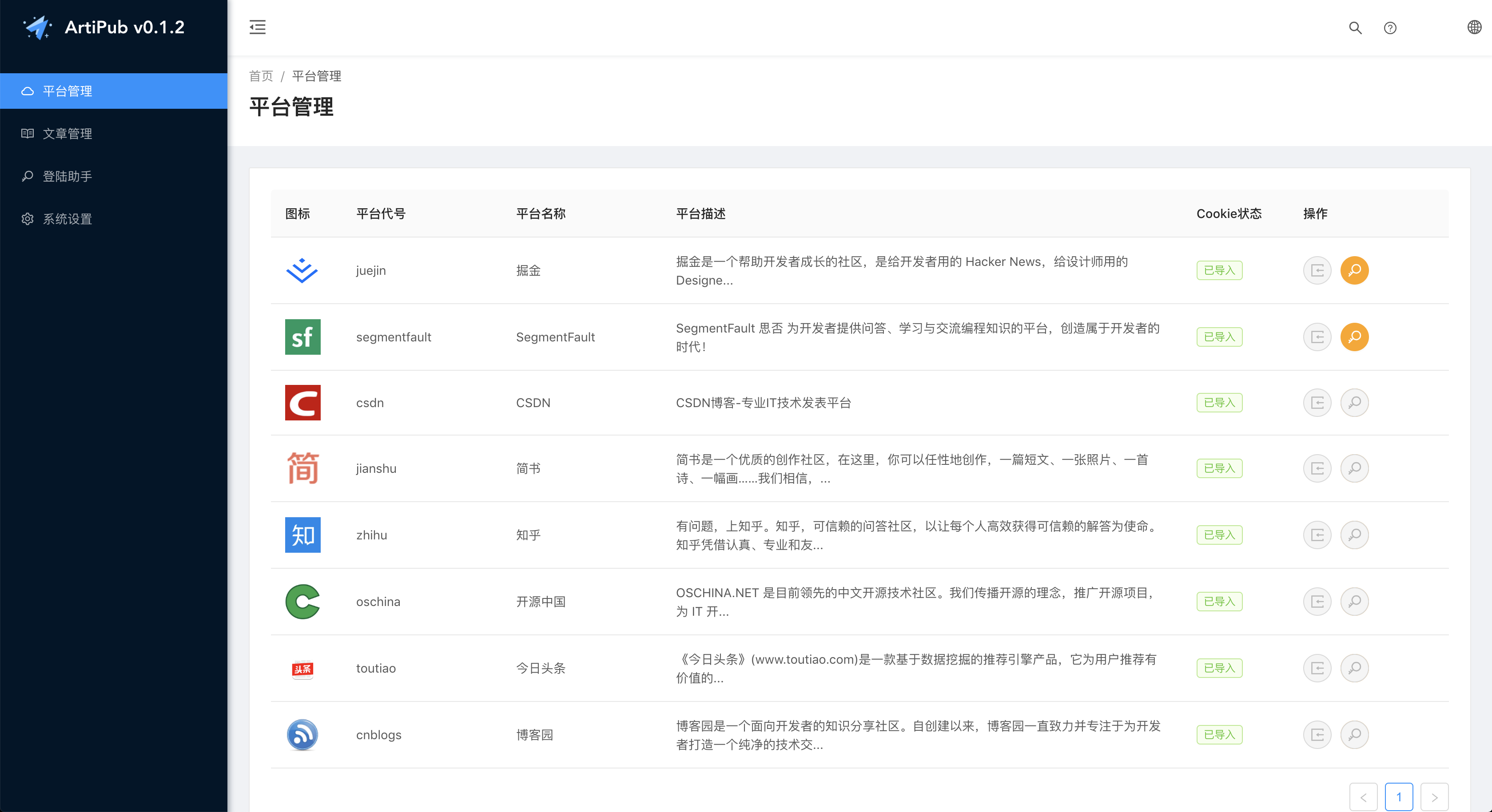
平台管理
![]()
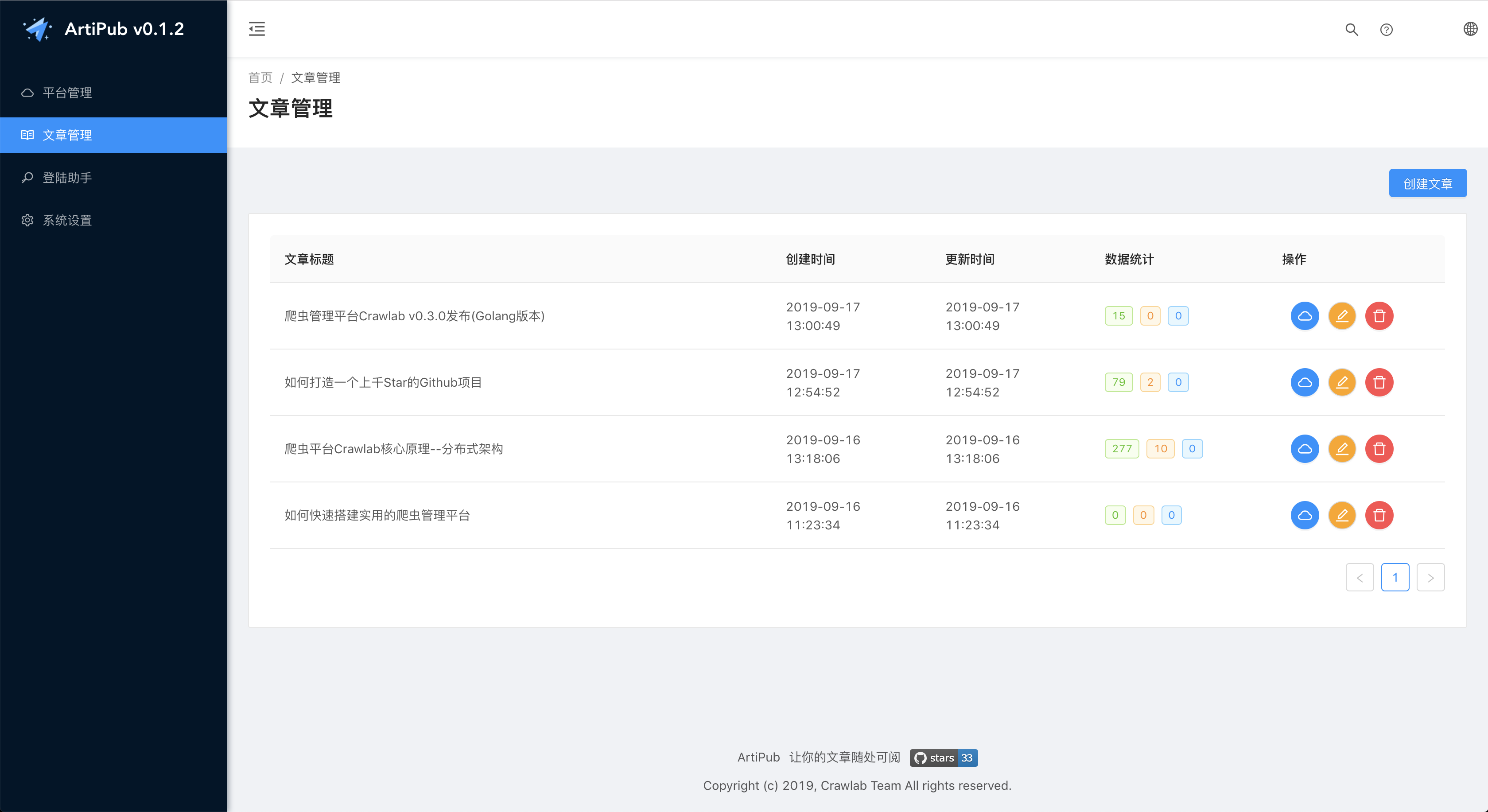
文章管理
![]()
文章编辑
![]()
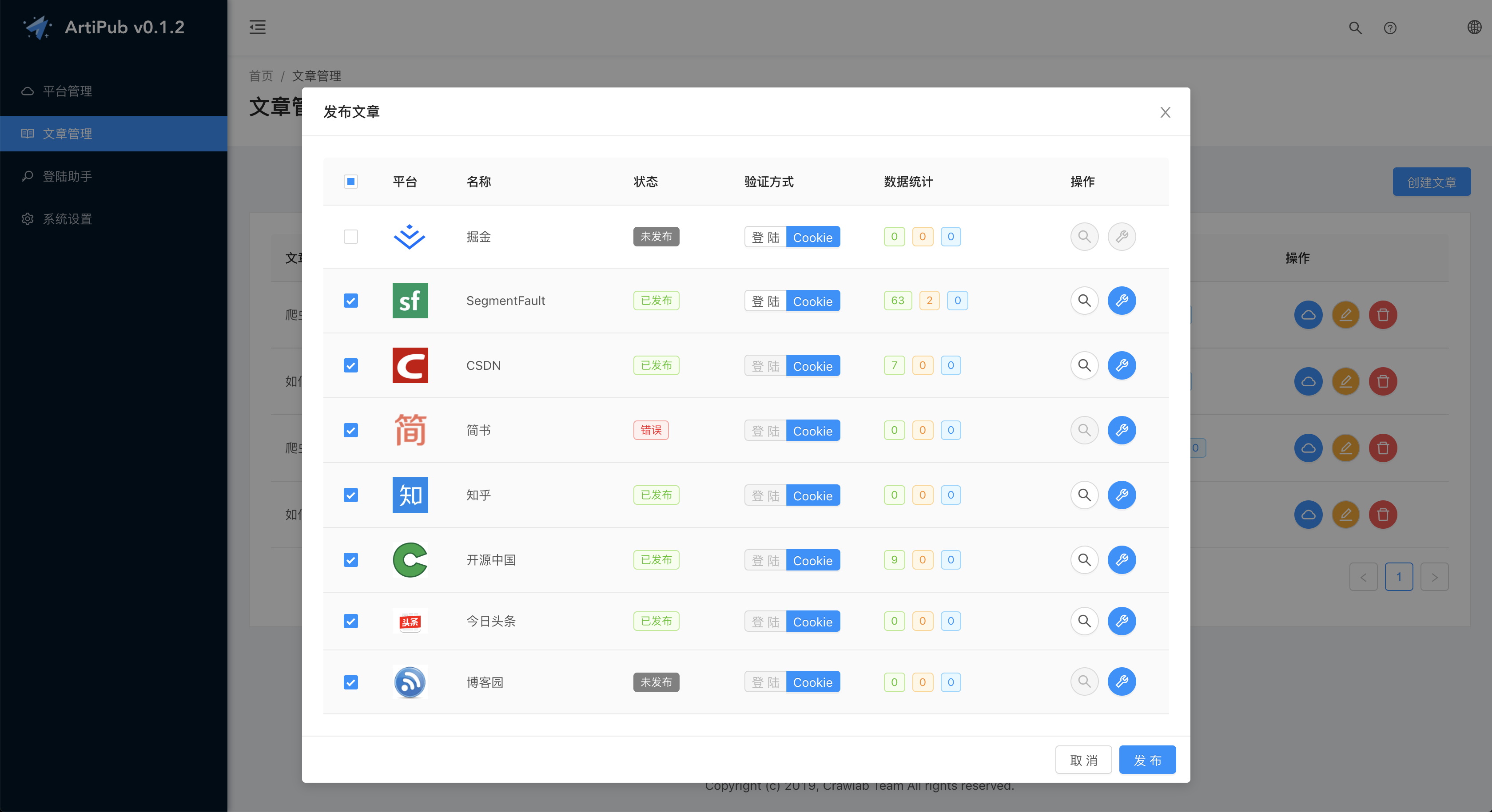
文章发布
![]()
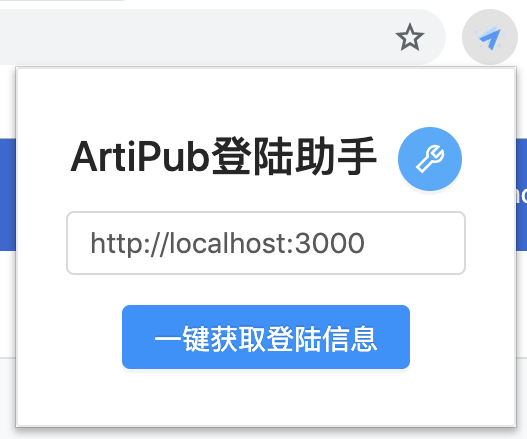
Chrome插件
![]()
与其他平台比较
市面上已经存在一文多发平台了,例如OpenWrite,为何还要创建ArtiPub呢?或许其他一文多发平台也是一个替代方案,但它们要求用户将自己的账户信息例如Cookie或账号密码上传到对方服务器,这很不安全,一旦平台发生问题,自己的账户信息会遭到泄漏。虽然我相信一般平台不会恶意操作用户的账户,但如果出现误操作,您的账户隐私将遭到泄漏,平台上的财产也可能遭到损坏,有这样的风险需要考虑。ArtiPub不要求用户上传账户信息,所有账户信息全部保存在用户自己的数据库里,因此规避了这个安全风险。
另外,由于ArtiPub是开源的,JS源码也比较易于理解,可扩展性很强,用户如果有其他平台的接入需求,完全可以通过更改源码来实现自己的需求,不用等待平台更新。开发组也将持续开发ArtiPub,将其打造得更实用和易用。
ArtiPub原理简介
其实ArtiPub的原理不复杂,简单来说就是利用了爬虫技术将文章发布到各大平台。ArtiPub的爬虫是用了Google开发的自动化测试工具Puppeteer,这个工具不仅可以获取需要有ajax动态内容的数据,还可以来做一些模拟操作,类似于Selenium,但更强大。如何进行登陆操作呢?其实ArtiPub是通过Chrome插件获取了用户登陆信息(Cookie),将Cookie注入到Puppeteer操作的Chromium浏览器中,然后浏览器就可以正常登陆网站进行发文操作了。Cookie是保存在用户自己搭建的MongoDB数据库里,不对外暴露,因此很安全。
下图是ArtiPub的架构示意图。
![]()
架构原理简介如下:
- 后端(Backend)是整个架构的中枢,负责给前端交换数据、储存读取数据库、控制爬虫、收集Cookie等;
- Chrome插件(Chrome Extension)只负责从网站(Sites)获取Cookie;
- 爬虫(Spiders)被后端控制,负责在网站上发布文章和抓取数据;
- 数据库(MongoDB)负责储存数据;
- 前端(Frontend)是一个React应用,是Ant Design Pro改造而来的。
总结
总的来说,ArtiPub解决了用户需要多平台发布文章、又不想泄漏账户信息的痛点。用户完全可以免费的使用ArtiPub,因为它是开源的,架构原理也很透明,开发者也可以自己去贡献该开源项目。ArtiPub很实用,作者已经将一些存量文章都发布到各个可用平台上了,效果还不错。甚至,本篇文章也是用ArtiPub编写和发布的,想要尝试的话,请到Github、Docker、NPM主页上安装体验。
如果您觉得 ArtiPub 对您有帮助,请扫描下方群二维码,如果群满,请加作者微信 tikazyq1 并注明"ArtiPub",作者会将你拉入群。
![]()
![]()
本篇文章由一文多发平台ArtiPub自动发布