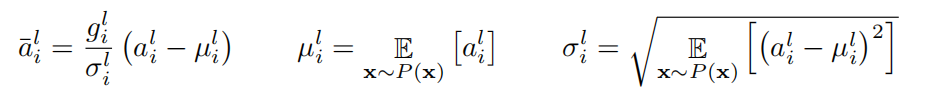一、Normalization是什么
Normalization一句话概括来说就是用一种办法,将一组数据压到均值为0,方差为1的正态分布上去,具体做法是数据集的每一个元素减去均值再除以标准差。公式如下:(请忽略参数g,g的问题很诡异,后面说)
![]()
这个公式说的更直白一点就是,把每一个a,经过平移和缩放,得到一个新值。而这样做的一个理由是,平移缩放并不会改变原始数据的分布情况,原来最大的还是最大,原来最小的还是最小。
Deeplearning中有很多Normalization的方法,有BN、LN、IN、GN等等,每一种Normalization公式都一样,只是沿着的轴不一样,BN就是沿着minibatch方向,LN就是沿着影藏层的output vector维方向,举个例子,对于四维张量[minibatch,depth、height、width],那就是沿着depth方向,把height、width维约简掉。
二、说说Layer Normalization
论文地址:https://arxiv.org/pdf/1607.06450.pdf
Layer Normalization对于时间序列数据有奇效,下面截一段论文的原文。这是在RNN上用Layer Normalization
![]()
简短的话说一下论文的变量含义,a表示t时刻点rnn的预输出值(还没有经过激活函数哦),h表示rnn某一个隐层t时刻点的输出。
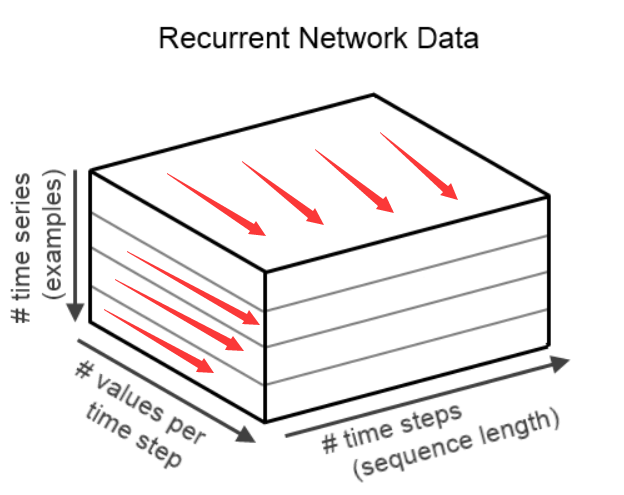
那么,这里Normalization是哪一个维度呢?假设RNN的输入张量为[minibatch、layerSize、timesteps],这么这里Normalization的就是layerSize这一维。这样可能还是太抽象,请看下图:
![]()
这里Normalization的就是红色箭头指向的每一个维度的向量,对于一条数据的每个time step而言,就求出一个均值和方差,进行变换,下一个time step类推下去。那么多个time step就有多个均值和方差。
三、重点说说参数g和b
这里g和b的维度要和h的维度相同,也就是上图的values per time step这一维度,也就是layer size的大小,这里g和b是跟随着网络参数学出来的。开始实现时,g的所有值一般会初始化为1,b的所有值会被初始化为0,随着训练的进行,g和b就会被修改为任意值了。那么Normalization也就没有了正态分布的效果,相当于layer size维乘以了一个随机向量,注意这里是向量点积,那么就等同于给一个随机的噪声,居然也能起作用,也是一个不能解释的问题。有点没有道理,但就是这么难以置信,居然是work的。
四、deeplearning4j的自动微分实现Layer Normalization
import java.util.Map;
import org.deeplearning4j.nn.conf.inputs.InputType;
import org.deeplearning4j.nn.conf.layers.samediff.SDLayerParams;
import org.deeplearning4j.nn.conf.layers.samediff.SameDiffLayer;
import org.nd4j.autodiff.samediff.SDVariable;
import org.nd4j.autodiff.samediff.SameDiff;
import org.nd4j.linalg.api.ndarray.INDArray;
public class LayerNormaliztion extends SameDiffLayer {
// gain * standardize(x) + bias
private double eps = 1e-5;
private static String GAIN = "gain";
private static String BIAS = "bias";
private int nOut;
private int timeStep;
public LayerNormaliztion(int nOut, int timeStep) {
this.timeStep = timeStep;
this.nOut = nOut;
}
protected LayerNormaliztion() {
}
@Override
public InputType getOutputType(int layerIndex, InputType inputType) {
return InputType.recurrent(nOut);
}
@Override
public void defineParameters(SDLayerParams params) {
params.addWeightParam(GAIN, 1, nOut, 1);
params.addWeightParam(BIAS, 1, nOut, 1);
}
@Override
public SDVariable defineLayer(SameDiff sd, SDVariable layerInput, Map<String, SDVariable> paramTable,
SDVariable mask) {
SDVariable gain = paramTable.get(GAIN);//论文中的g
SDVariable bias = paramTable.get(BIAS);//论文中的b
SDVariable mean = layerInput.mean("mean", true, 1);//均值
SDVariable variance = sd.math().square(layerInput.sub(mean)).sum(true, 1).div(layerInput.getShape()[1]);//平方差
SDVariable standardDeviation = sd.math().sqrt("standardDeviation", variance.add(eps));//标准差,加上eps 防止分母为0
long[] maskShape = mask.getShape();
return gain.mul(layerInput.sub(mean).div(standardDeviation)).add(bias)
.mul(mask.reshape(maskShape[0], 1, timeStep));//掩码掩掉多余长度
}
@Override
public void initializeParameters(Map<String, INDArray> params) {
params.get(GAIN).assign(1);
params.get(BIAS).assign(0);
}
public int getNOut() {
return nOut;
}
public void setNOut(int nOut) {
this.nOut = nOut;
}
public int getTimeStep() {
return timeStep;
}
public void setTimeStep(int timeStep) {
this.timeStep = timeStep;
}
}
五、实战的结果
就用RNN做文本分类而言,加上LN,收敛会更平稳,但准确率大大下降了。
在deeplearning的世界里,任何一种方法被提出来,只是在解当前的问题,对于每一种具体的问题,肯定是case by case。
快乐源于分享。
此博客乃作者原创, 转载请注明出处