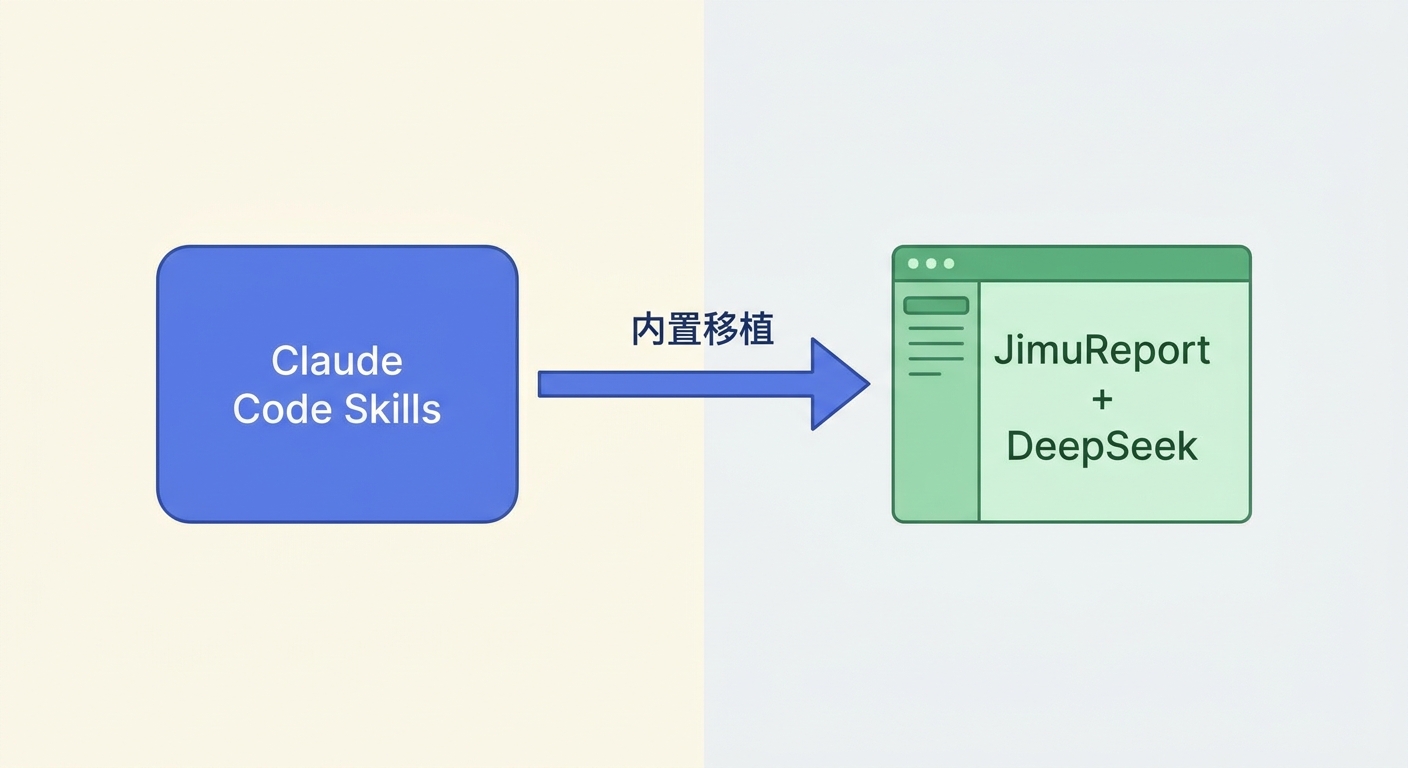
把 Claude Code Skills 装进 JAR 包 —— 积木报表的破局思路
积木报表(JimuReport)v2.5.0 做了一件在国内低代码工具里头一次的事:把 Claude Code 的 Skills 直接打包进产品 JAR,作为内置的领域知识专家,用户启动服务即可使用,完全不需要安装 Claude Code 或任何 CLI 环境。
这句话背后有一个值得说清楚的背景。过去两年,几乎所有产品都在喊 "接入大模型",但用下来,真正让人满意的没几个。症结不是模型不够强,而是接入方式太浅 —— 大多数产品只是在界面里嵌了个对话框,把用户输入丢给通用 API,返回文本展示出来。模型不知道 "这个产品是什么"、"用户在做什么任务"、"正确操作路径是哪条",面对 "帮我做一张分组交叉报表",只能泛泛给文字建议,无法真正操作设计器、生成数据集、配置字段绑定。
Claude Code 的 Skills 机制本来是解决这个问题的 —— 它让开发者把特定领域的知识和操作规范封装成 "技能包",AI 按 Skill 定义的流程执行,而不是自由发挥。但 Skills 原本是面向开发者的工具:你得先装 Claude Code CLI、配置 Skills 目录、理解触发规则,普通业务用户根本用不起来。
积木报表的做法是跨越这道门槛:把积木报表的操作规范、API 调用流程、字段绑定规则全部封装成产品内置的 Skills,随产品 JAR 一起分发。用户只需配置 DeepSeek API Key,不需要了解任何 Skills 工作原理,就能获得与 Claude Code Skills 等效的领域 AI 智能。这是一次从 "开发者工具" 到 "产品能力" 的跨越。
Claude Code Skills 是一套什么机制?
要理解 "内置 Skills",得先搞清楚 Claude Code 的 Skills 是什么。

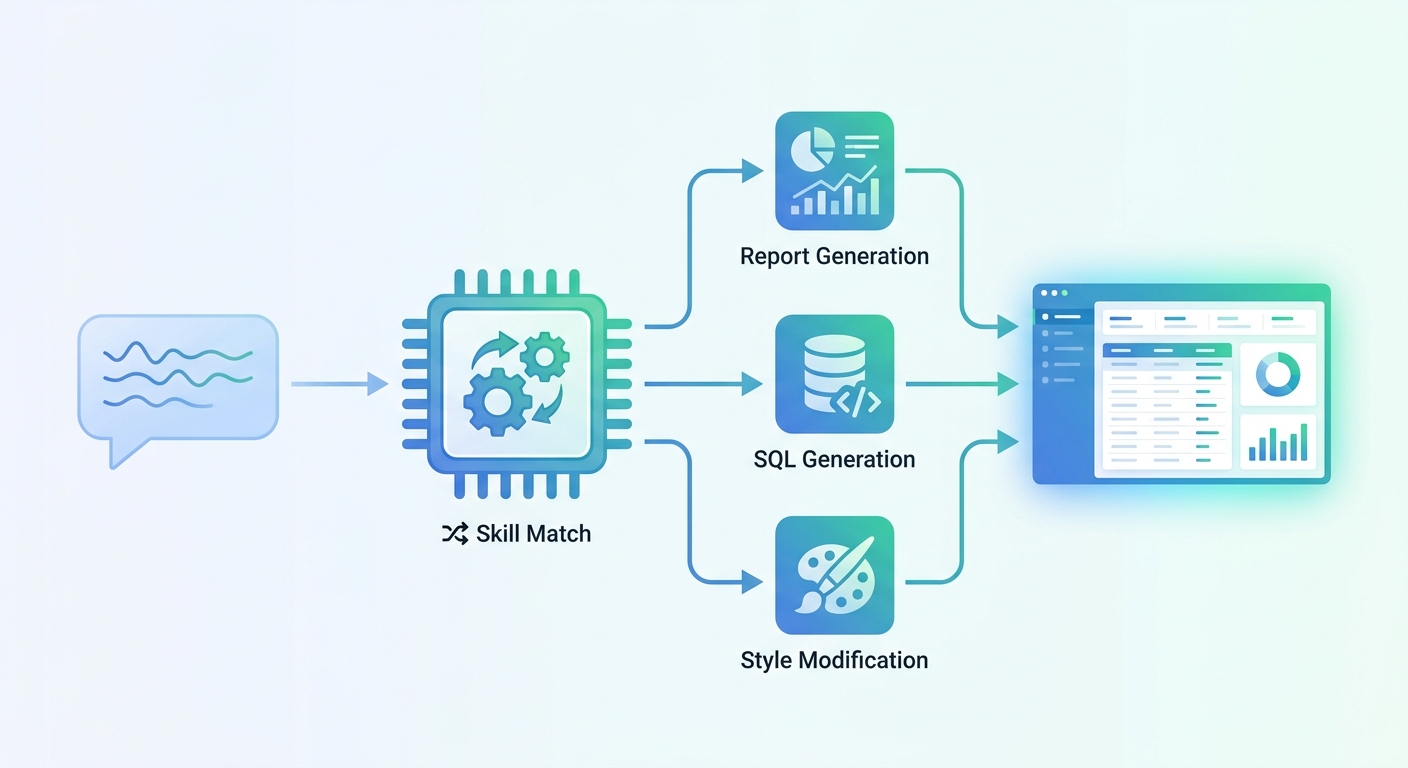
Claude Code 是 Anthropic 推出的 AI 编程工具。它的 Skills 系统,简单说是这样运转的:开发者可以把特定领域的知识、操作规范、执行步骤打包成一个 "技能包",AI 在收到任务时会先匹配是否有相关 Skill,有的话就按照 Skill 里预定义的流程执行,而不是完全靠模型自由发挥。
这带来三个关键变化:
- 可预期:AI 的行为不再是 "看心情",每次执行路径是确定的
- 可控制:域外的操作 Skill 不会涉及,越界风险显著降低
- 领域专精:Skill 里封装了大量产品知识,AI 理解 "什么是分组"" 如何绑定数据集 ",而不需要从头推理
用一个类比:通用大模型是一个什么都懂一点的全科医生,而带有 Skills 的 AI 是一个经过系统培训、熟悉你家医院系统、知道你的病历规范的专科医生 —— 同样是接诊,深度完全不同。
问题在于,Claude Code 是一个独立工具,普通用户不会去安装它、配置它。如果产品的 AI 能力强依赖 Claude Code,推广门槛极高,等于把产品智能化建立在用户环境配置的不确定性上。
内置 Skills:把专家认知 "焊进" 产品
积木报表 v2.5.0 走的路子是:不依赖 Claude Code 工具,把 Claude Code 的 Skills 的设计思想直接内化到产品里。
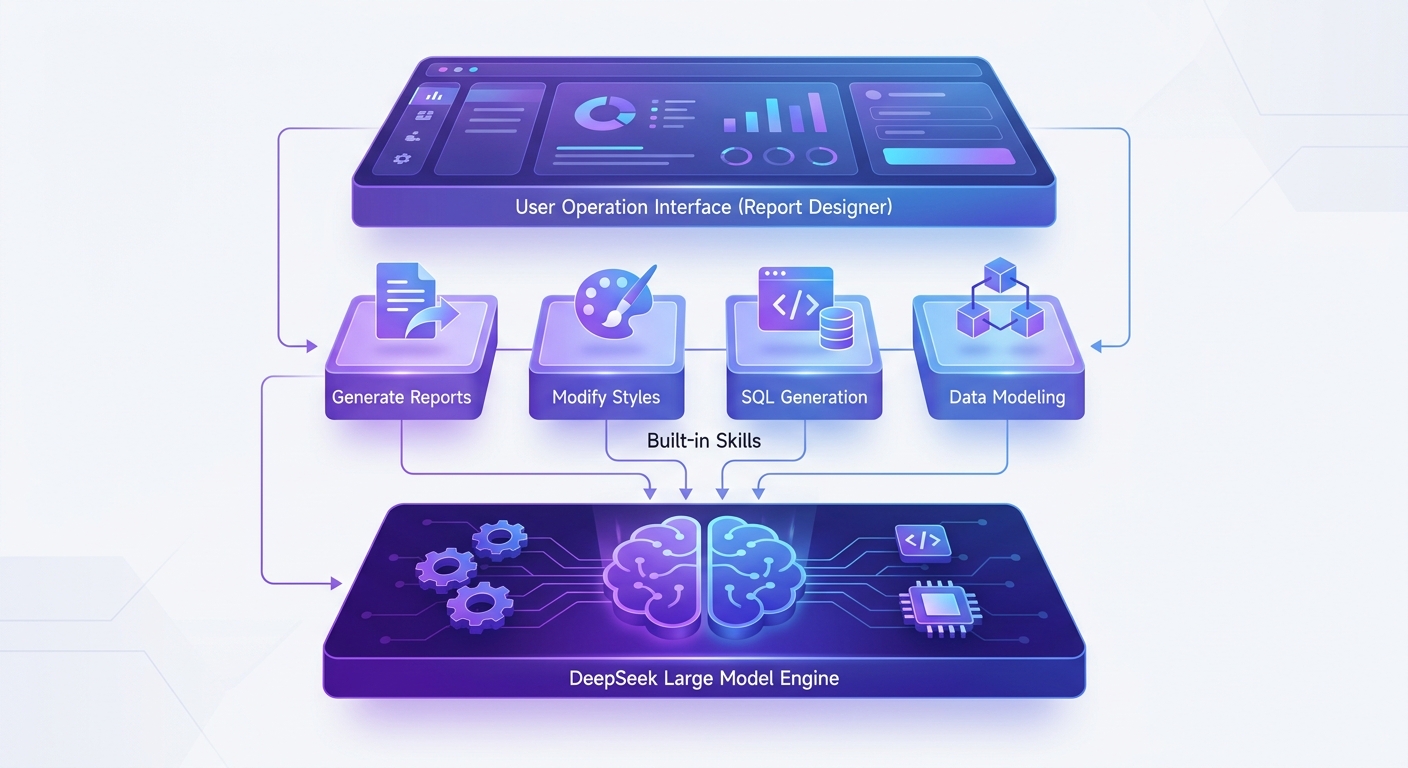
具体来说,产品团队把积木报表产品的知识 —— 什么是分组报表、什么是交叉报表、数据集如何绑定、图表如何配置、SQL 如何生成 —— 全部封装成产品内置的 Skill,底层模型换成 DeepSeek。用户只需要在配置文件里填几行 API Key,无需安装 Claude Code,无需了解 Skills 的工作原理,开箱即可使用与 Skills 等效的领域 AI 能力。
jeecg:
jmreport:
ai:
base-url: https://api.deepseek.com
api-key: sk-xxxxxxxx
model: deepseek-v4-pro
temperature: 0
max-tokens: 16384
autoTableEnabled: false # 生产环境建议关闭自动建表
集成积木的 Maven 依赖:
<!-- 积木报表 SpringBoot3 -->
<dependency>
<groupId>org.jeecgframework.jimureport</groupId>
<artifactId>jimureport-spring-boot3-starter</artifactId>
<version>2.5.0</version>
</dependency>
<!-- 积木大屏 SpringBoot3 -->
<dependency>
<groupId>org.jeecgframework.jimureport</groupId>
<artifactId>jimubi-spring-boot3-starter</artifactId>
<version>2.5.0</version>
</dependency>
这几行配置背后,是产品内置的完整报表 Skill 体系:支持 18 类报表类型的自然语言生成、对话式样式修改、一键回滚、AI 数据建模…… 用户感知到的是 "一句话生成报表",但 AI 之所以能做到,是因为它已经知道报表设计器的每一个操作节点该如何处理。
这和 "直接调用通用 LLM API" 有本质区别:
| 对比维度 |
通用 API 接入 |
内置 Skills |
| AI 对产品的理解 |
无,靠 Prompt 临时描述 |
深度,封装在 Skill 内 |
| 执行路径 |
每次都不确定 |
固定、可预期 |
| 领域深度 |
浅,受 Prompt 质量影响 |
深,Skill 里有完整操作规范 |
| 用户门槛 |
需要懂 Prompt Engineering |
自然语言即可 |
| 稳定性 |
高度依赖模型状态 |
Skill 兜底,稳定性更高 |
为什么 AI 产品都需要内置 Skills?
这不是积木报表一个产品的问题,而是所有 AI 垂直产品都会面临的选择。
根本原因是:通用大模型的泛化能力和垂直产品的专业深度,是两个不同维度的目标。
大模型在泛化上已经足够强 —— 理解意图、生成内容、推理逻辑,这些基础能力模型都有。但 "在这个具体产品里应该怎么操作"" 这个业务术语对应的配置路径是哪条 "—— 这些产品级别的知识,不可能靠通用预训练获得,必须由产品方自己注入。
Skills 机制正是解决这个问题的标准化方式。它不是 Prompt Engineering 的升级版,而是把产品知识和操作规范系统化地注入 AI 决策链路,让模型在特定产品场景里的表现,从 "有点能用" 变成 "真的好用"。
实测中,积木报表的 AI 修改报表能力(对话式改样式、加合计、改图表)稳定性极高,这正是内置 Skill 的体现 —— 修改操作是有明确步骤和边界的,Skill 规范了 AI 的行为,而不是让模型自由发挥。
Skills 的趋势:从工具脚本到认知基础设施
向前看,Skills 机制的演化方向值得关注。
趋势一:Skills 成为垂直 AI 产品的标准配置
积木报表是国内低代码 / 报表工具中第一个将 Claude Code Skills 能力产品化落地的案例,但它不会是最后一个。随着更多产品团队意识到 "接入大模型" 和 "拥有领域 AI 智能" 是两件不同的事,Skills 体系将从先发者的竞争优势,逐渐变成行业标准配置。
未来两年,不带内置 Skills 的 AI 垂直产品,可能就像今天没有搜索功能的应用 —— 不是不能用,但用户会觉得缺了什么。
趋势二:Skills 粒度越来越细,可组合性越来越强
早期的 Skills 是粗粒度的,比如 "生成报表" 是一个 Skill。随着实践积累,Skills 会拆分为更细粒度的单元:解析用户意图、选择报表类型、生成 SQL、绑定数据集…… 每个单元独立可测、可替换,组合起来完成复杂任务。
这种细粒度化让 Skills 的维护和迭代变得更工程化,也让不同产品的 Skills 之间出现复用空间。
趋势三:底层模型与 Skills 体系解耦
积木报表用 DeepSeek 驱动内置 Skills,但 Skills 本身是模型无关的。未来的成熟产品会把 Skills 体系做成可以对接任意模型的中间层 —— 今天用 DeepSeek,明天换成更好的模型,Skills 体系不需要重写,只需换底层模型接口。
这让产品不再被某一家模型厂商绑定,也让 Skills 真正成为产品的核心资产,而不是模型的附属品。
总结
"内置 Skills" 这个词背后,代表的是 AI 产品化的一次认知升级:从 "接入大模型" 到 "拥有领域智能"。
通用大模型是原材料,Skills 是加工工艺,产品才是最终交付物。只有把产品知识、操作规范、边界约束系统化地封装进 AI 的决策链路,大模型的能力才能在具体产品场景里稳定落地,而不是停留在 Demo 演示的水平。
积木报表 v2.5.0 的这次尝试,是一个有价值的行业先例 —— 它证明了 Skills 机制可以脱离 Claude Code 工具独立存在,可以用更轻量的方式内化到任何产品里,让任何用户都能享受到领域专精 AI 的价值。
这条路值得更多产品团队认真研究和跟进。
