前OpenAI安全研究VP、现Thinking Machines Lab联合创始人兼首席科学家翁荔(Lilian Weng),在停更13个月后,往她的个人技术博客Lil'Log上发表了一篇新文章,标题《Scaling Laws, Carefully》,一万多字。她自己说这篇文章"迟到了三年多"。
读完之后你会发现,这三年多没白等。
翁荔在AI圈的位置不需要多介绍——北大本科,Indiana University Bloomington博士,在OpenAI从研究员一路做到安全系统VP,去年离职后和一批前OpenAI核心成员创立了Thinking Machines Lab。她的博客Lil'Log被很多从业者形容为"比大多数论文写得更清楚",是中文AI圈最常引用的技术博客之一。
这篇新博文做了一件事:把支撑大模型行业数百亿美元投入的Scaling Laws从头到尾扒了一遍——从1992年日本人Amari推导出的第一条学习曲线,到2026年的数据墙模型。而她扒出来的结论,让很多从业者不太舒服。
最核心的一条:你现在用的模型,很可能喂错了数据量。

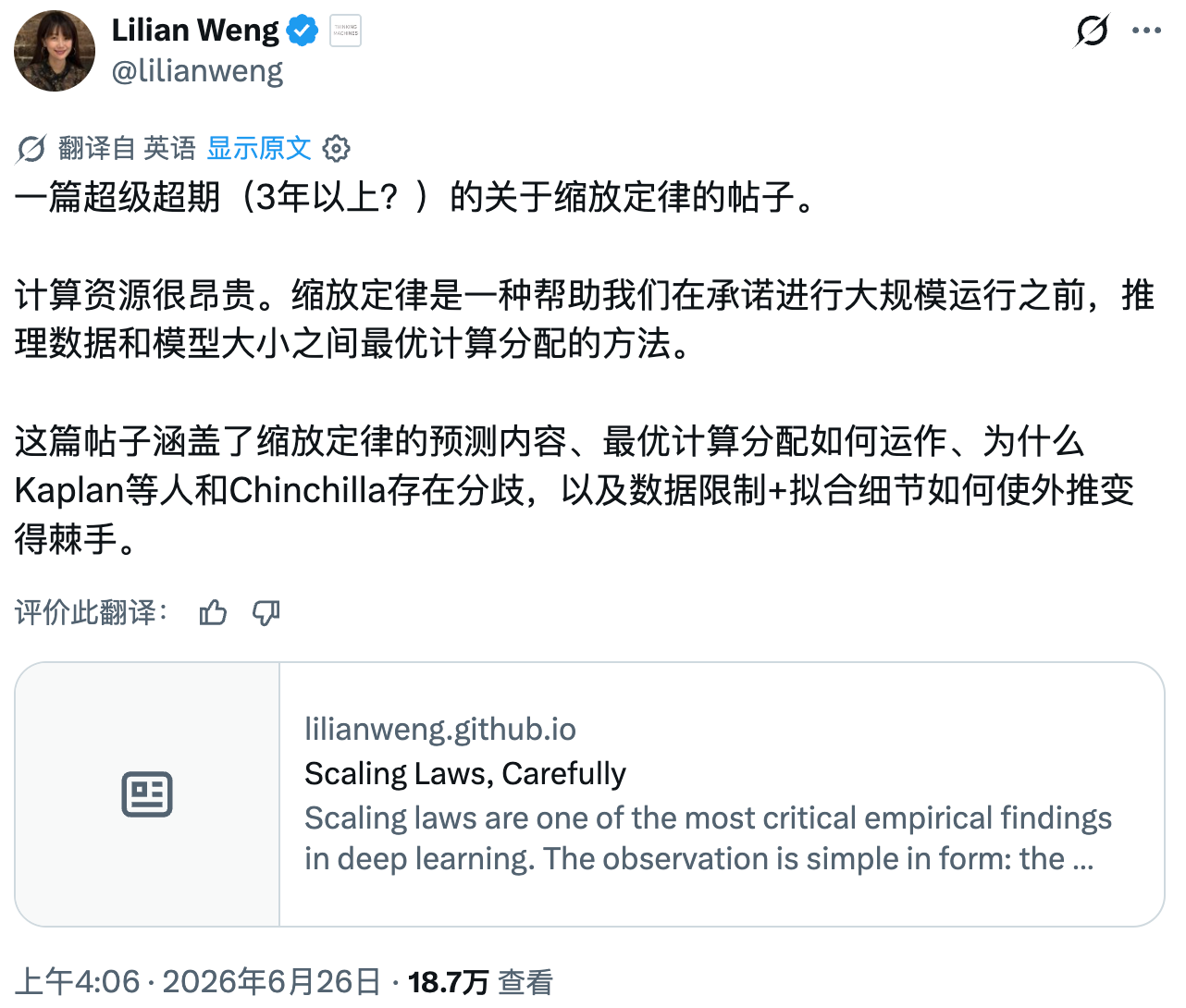
故事要从2020年说起。OpenAI研究员Jared Kaplan发表了一篇论文,提出那个后来成为行业圣经的Scaling Laws框架:在log-log坐标上,训练损失随参数量N、数据量D、算力C的增加呈直线下降——漂亮的幂律关系。Kaplan的结论是,模型规模应该比数据增长得更快:算力涨10倍,模型参数涨5.5倍,但训练数据只涨1.8倍就够了。
GPT-3就是这么练出来的:1750亿参数,只喂了3000亿token。参数量是数据量的将近6倍。
两年后,DeepMind的Jordan Hoffmann带着团队重新做了同样的实验——但规模大得多,方法细得多(三种互补的拟合方法交叉验证,最大模型到了160亿参数)。然后得出了一个完全相反的结论。
在同一个算力预算下,他们把DeepMind自家的Gopher(2800亿参数,3000亿token)跟一个新模型Chinchilla(700亿参数,1.4万亿token)放在一起对比。Chinchilla参数只有Gopher的四分之一,但训练数据是四倍多。结果Chinchilla在所有评测上碾压了Gopher。
Chinchilla告诉你:参数翻一倍,训练数据也该翻一倍。参数和token的最佳比例大约是1:20。不是Kaplan说的参数飙涨、数据慢跟。
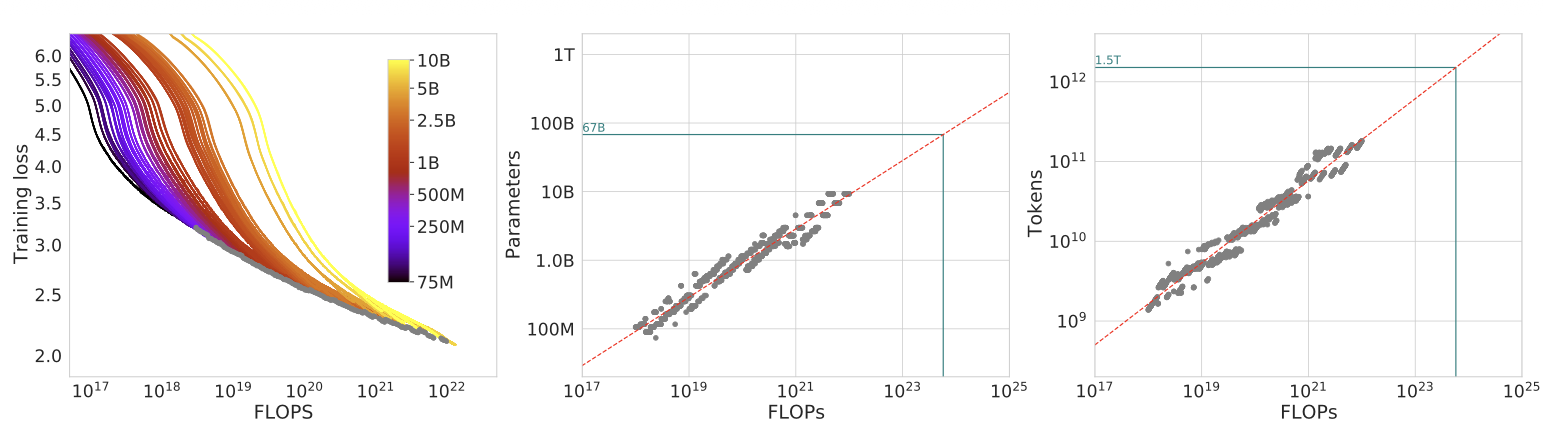
这就是为什么后来Llama、DeepSeek这些模型,参数没有GPT-3大,但性能好得多的根本原因。它们遵循了更正确的参数-数据配比。
那么Kaplan到底错在哪?翁荔写了整整一章来分析。
第一,实验规模。Kaplan实验的最大模型只有15亿参数,然后把这个结论外推到了万亿参数。在log-log空间里,小规模区间的微小拟合差异外推几个数量级后,会变成系统性预测偏差。
第二,参数的口径。Kaplan不算embedding层参数(所谓non-embedding parameters)。小模型上embedding占比很大,去掉后显著改变了N和C的关系。Pearce和Song在2024年证明:把embedding加回去,Kaplan的0.73次方自然收敛到Chinchilla的0.5。不是Kaplan错了,而是他的结论只在一个局部区间里成立——被当成全局真理用了。
故事还没完。2024年,Epoch AI团队做了一件科研圈罕见的事:逐行复现Chinchilla的拟合代码。然后发现了两个bug。
Bug 1:损失函数实现里取了均值而不是求和,L-BFGS-B优化器发现loss值太小,以为自己已经收敛了,提前停了。真正的全局最优解根本没找到。
Bug 2:两个核心幂律指数α和β被四舍五入到小数点后两位。从两位数反推的其他参数误差被指数级放大,置信区间窄得离谱,看起来特别"显著"——其实是假象。
Epoch AI修正后的真实值是:α ≈ 0.3478,β ≈ 0.3658。它们极度接近,再次确认了Chinchilla的方向——模型和数据应该等比增长。但原论文的具体数字需要修正。
然后是最让人不安的部分:数据墙。
以上所有讨论有一个前提:训练数据无限、不重复。人类生产的高质量文本数据预计2026到2028年就会耗尽。当数据不够,只能重复训练。
但重复数据的价值是指数衰减的。Muennighoff等人在2023年引入了一个"有效数据量"概念:同一批数据反复训练,边际价值遵循D_eff = U·(1-e^(-R))的规律,U是唯一token数,R是重复次数。每多一轮,收益递减。Lovelace等人2026年的新工作直接显式建模了过拟合惩罚项,同时发现强weight decay可以有效缓解重复训练的过拟合。
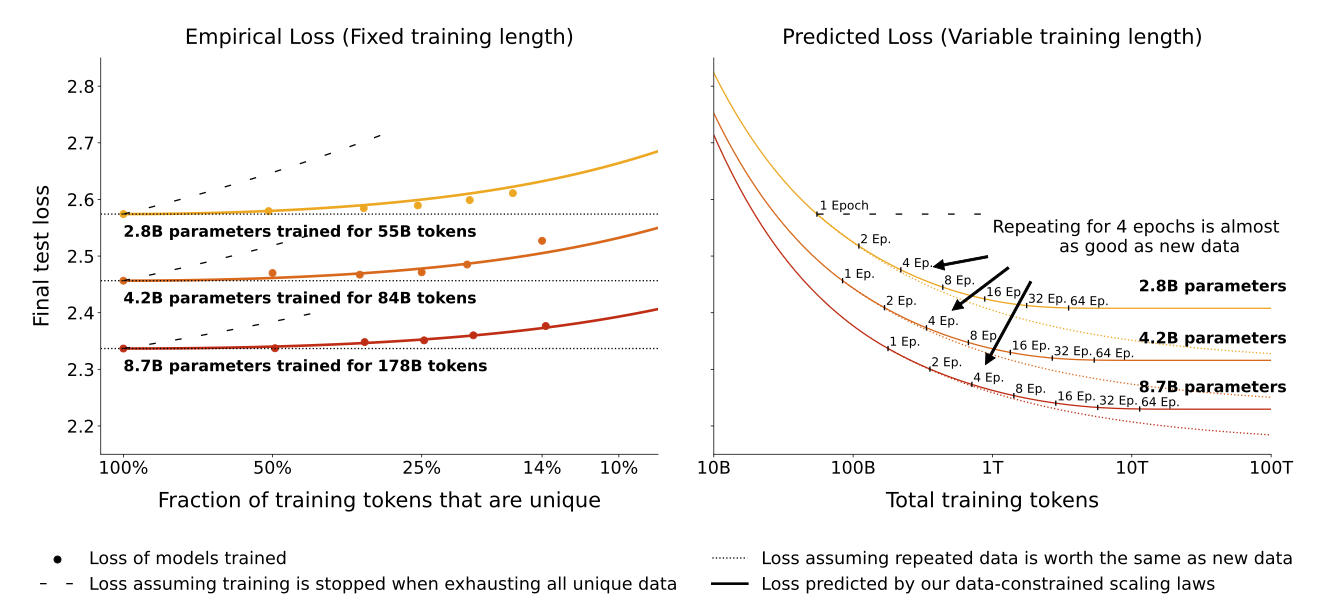
最后,翁荔在博客里嵌了一个交互式模拟器。你可以调三个参数:拟合精度、噪声水平、拟合区间。随便调一下就会直观感受到:看起来无关紧要的工程选择——loss保留几位小数、噪声在0.001量级——都能导致外推预测差出十万八千里。
Scaling Laws不是物理定律。它是对工程细节高度敏感的观测性指南。
这句话,她花了三年才讲完。
参考来源:
