当AI编程模型的代码正确性已不再是一个问题,如何衡量代码"质量"就成了新的焦点。Cognition日前发布了FrontierCode,这是一个专门衡量AI模型能否写出达到生产合并标准的代码的评测基准。与现有编程评测基准不同,FrontierCode不去评估"代码对不对",而是"维护者会不会真的合并这个PR"。
当前主流编程评测基准如SWE-Bench Verified和Pro,设计时针对的是能力较弱阶段的模型。这些基准存在明显的局限性:它们只验证代码的功能正确性,不验证代码质量;此外误分类错误率较高——即通过测试的代码补丁未必能被人类维护者真正接受。METR的实验进一步证实,许多在现有基准上高分的模型,生成的补丁在实际代码审核中会被拒绝。
FrontierCode的解决思路是与开源社区顶级维护者合作。36个旗舰开源项目的维护者参与了任务构建,每人花在每个任务上的时间超过40小时。他们定义了各自代码仓库中"可合并"的具体标准,并将这些标准转化为评分规则。
评分维度包括:行为正确性(补丁是否有效解决问题)、回归安全性(是否破坏现有功能)、机械清洁度(构建/检查是否通过)、测试质量(AI Agent编写的测试是否真正捕捉到目标行为)、代码范围(是否只修改了必要的部分)以及代码质量(是否符合代码库规范和设计模式)。
为解决测试覆盖不足导致的问题,FrontierCode引入了"反向经典测试"机制:Agent提交的测试在原始有缺陷的代码库上运行时必须失败,这确保了测试的有效性。此外还引入了"自适应经典评分"方法,使用LLM将参考测试或应用代码适配到Agent的实现细节上,从而在开放性任务中对多样化解法进行严格而确定的测试。
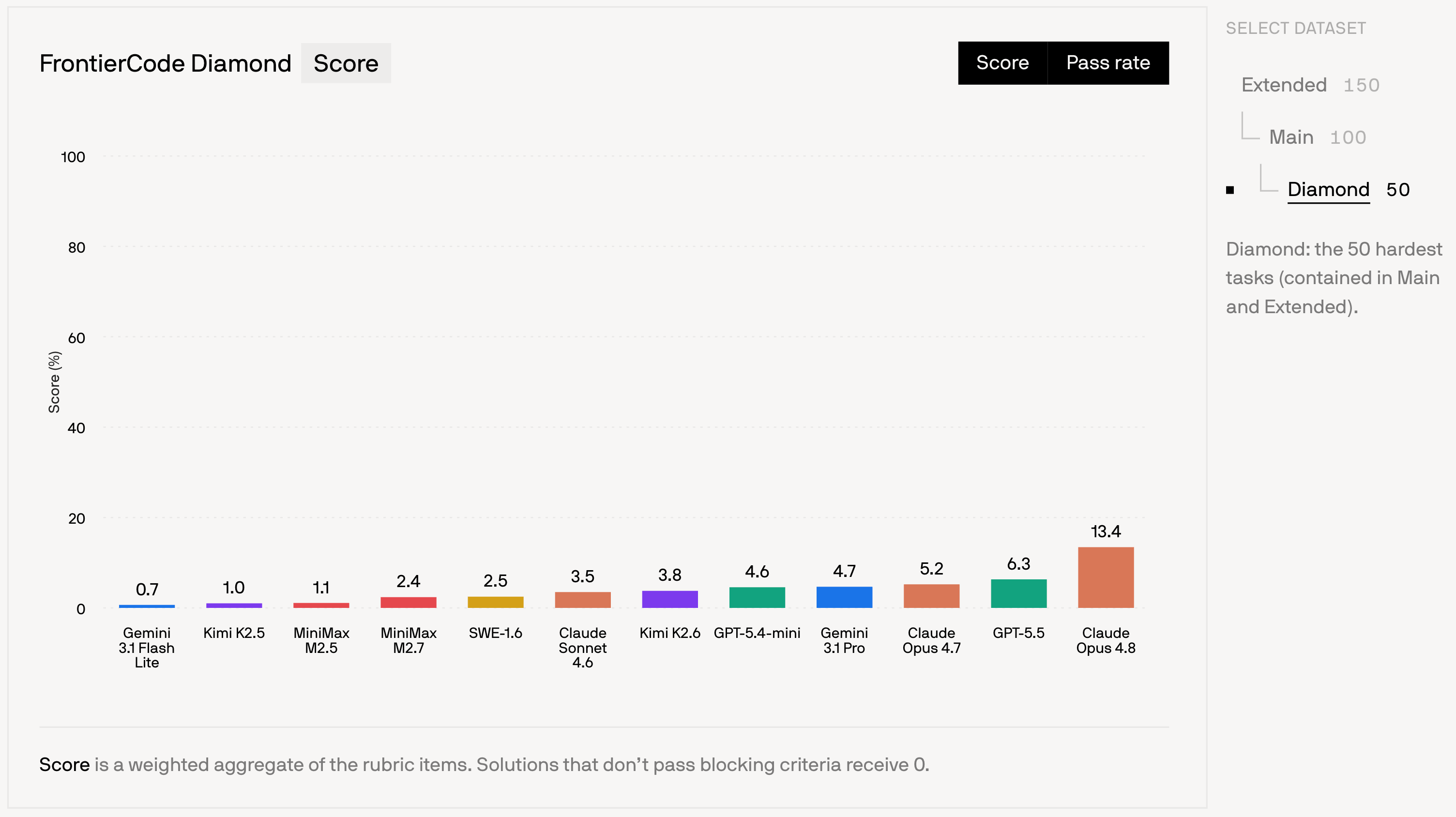
FrontierCode共包含150个任务,分为三个难度子集:Diamond(50个最难)、Main(100个)和Extended(全部150个)。目前最佳模型Claude Opus 4.8在Diamond上仅得分13.4%,GPT-5.5得6.3%,Gemini 3.1 Pro得4.7%——即使是当前最强大的模型,在这项新标准下仍有巨大提升空间。开源模型中表现最好的Kimi K2.6在Diamond上仅得3.8%。
Cognition表示,FrontierCode的评分误差比SWE-Bench Pro低81%,是目前最准确模型能力排名。但为防止任务污染,Cognition不打算公开任务内容,而是向所有模型开发者开放评测服务,希望推动前沿编程能力的进一步突破。
参考来源: https://cognition.ai/blog/frontier-code
