腾讯混元团队近日联合中国人民大学高瓴人工智能学院等机构推出并开源 PlanningBench:一个面向大语言模型规划能力评测与训练的可扩展、可验证数据生成框架。
根据介绍,PlanningBench从真实规划场景出发,系统抽象任务、约束与难度因素,构建覆盖30+规划任务类型的数据生成与验证体系,既能评测模型是否真的“会规划”,也能为规划能力训练提供稳定、可迁移的奖励信号。
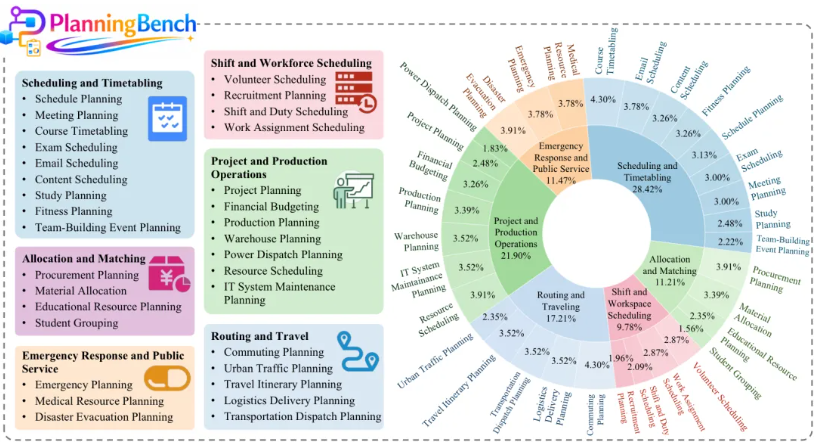
PlanningBench形成了真实场景、30+任务类型、六大规划类别、自动验证、Avg-pass / All-pass、闭环生成和训练迁移等一整套能力闭环。
- 真实场景驱动,覆盖面更广 PlanningBench从真实规划场景出发,覆盖日程排布、资源分配、人力排班、路径调度、生产运营、应急服务等六大类任务,包含30+具体规划任务类型,避免模型只在单一领域内“刷题”。
- 约束体系化,难度可控 PlanningBench将规划难度拆解为任务结构、约束层级、资源紧张度、目标冲突、依赖关系和异常处理等因素,使数据生成可以围绕真实难点进行控制,而不只是简单拉长prompt
- 自动验证,支持评测与训练闭环 每条实例都配套checklist,可用于评估模型输出是否满足输入条件、资源限制、时间窗口、输出格式和目标最优性,也可为强化学习提供奖励信号。
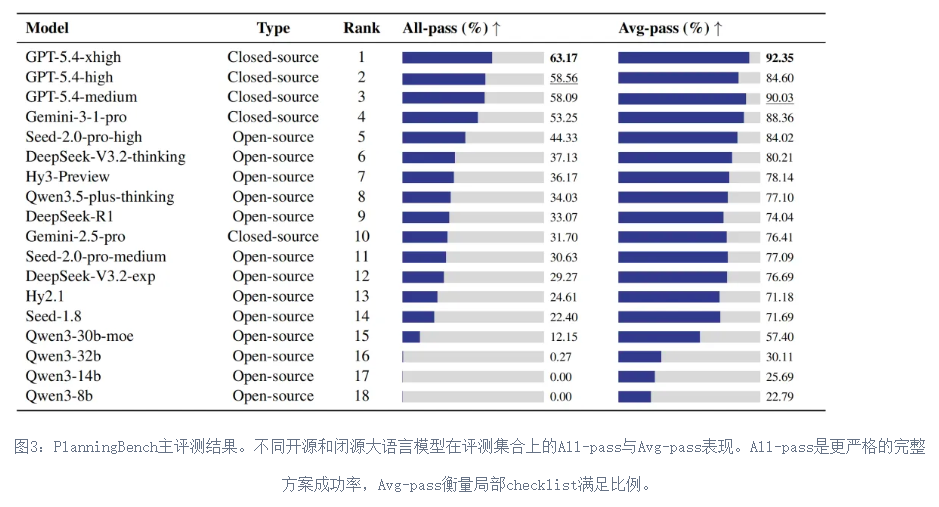
- 区分局部合规与全局成功 PlanningBench同时关注Avg-pass和All-pass,能够识别“看似大部分正确但整体不可执行”的计划,尤其适合诊断大模型在复杂约束下的真实规划能力。
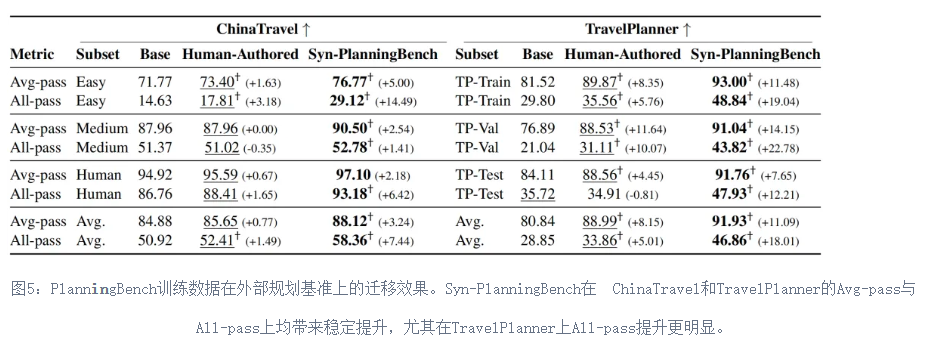
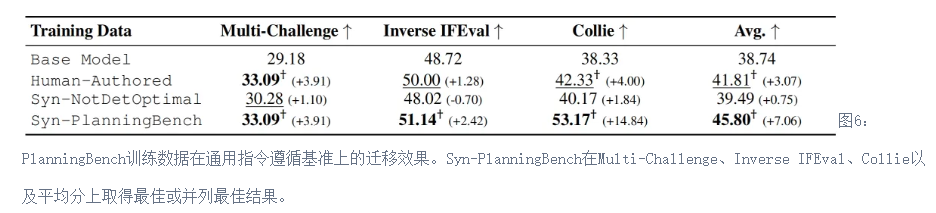
- 训练有效,具备跨基准迁移能力 基于PlanningBench的可验证数据进行训练,可以提升模型在未见过规划基准和通用指令跟随任务上的表现,说明其学习信号具有一定通用性。
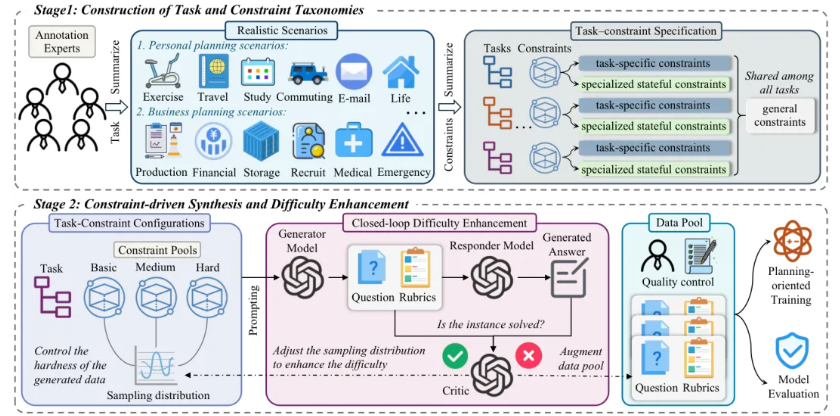
PlanningBench 的核心,是一个约束驱动的闭环合成流程。
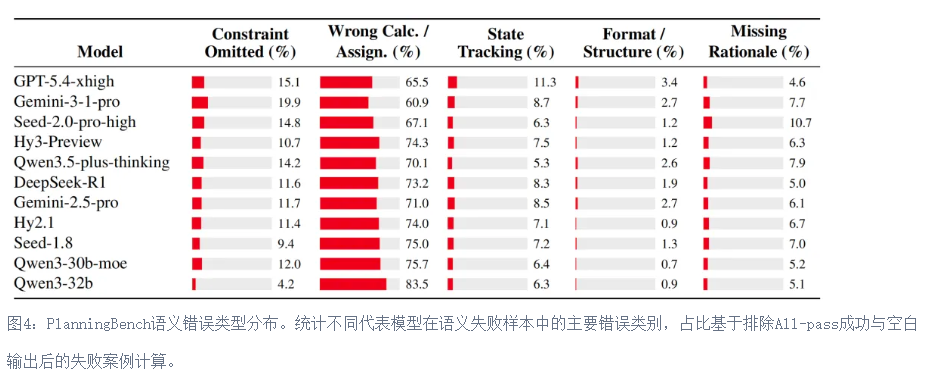
一些测评结果如下: