Anthropic 在 GitHub 上开源了名为"Defending Code Reference Harness"的项目,提供了一套基于 Claude 的自主化漏洞发现与修复的参考实现。这不是一款面向普通用户的商业产品,而是一套与安全团队合作后的技术复盘与经验沉淀——它以代码和文档的形式开放,供安全研究者和 AI Agent 开发者参考和定制。
项目的核心是一套自主扫描管线(Autonomous Reference Pipeline),设计思路是将漏洞挖掘拆解为七个阶段:Recon(侦察)、Find(发现)、Verify(验证)、Report(报告)、Patch(修复),形成一个完整的闭环。Recon 阶段由一个轻量级 Agent 完成,它对输入解析子系统提出划分建议;Find 阶段由 N 个 Agent 并行运行,各自构造畸形输入;Verify 阶段由 grader Agent 在新容器中复现崩溃;Dedupe 阶段由 judge Agent 将新发现与已有报告进行比对去重;最后 Report 和 Patch 阶段输出结构化的漏洞分析和修复建议。
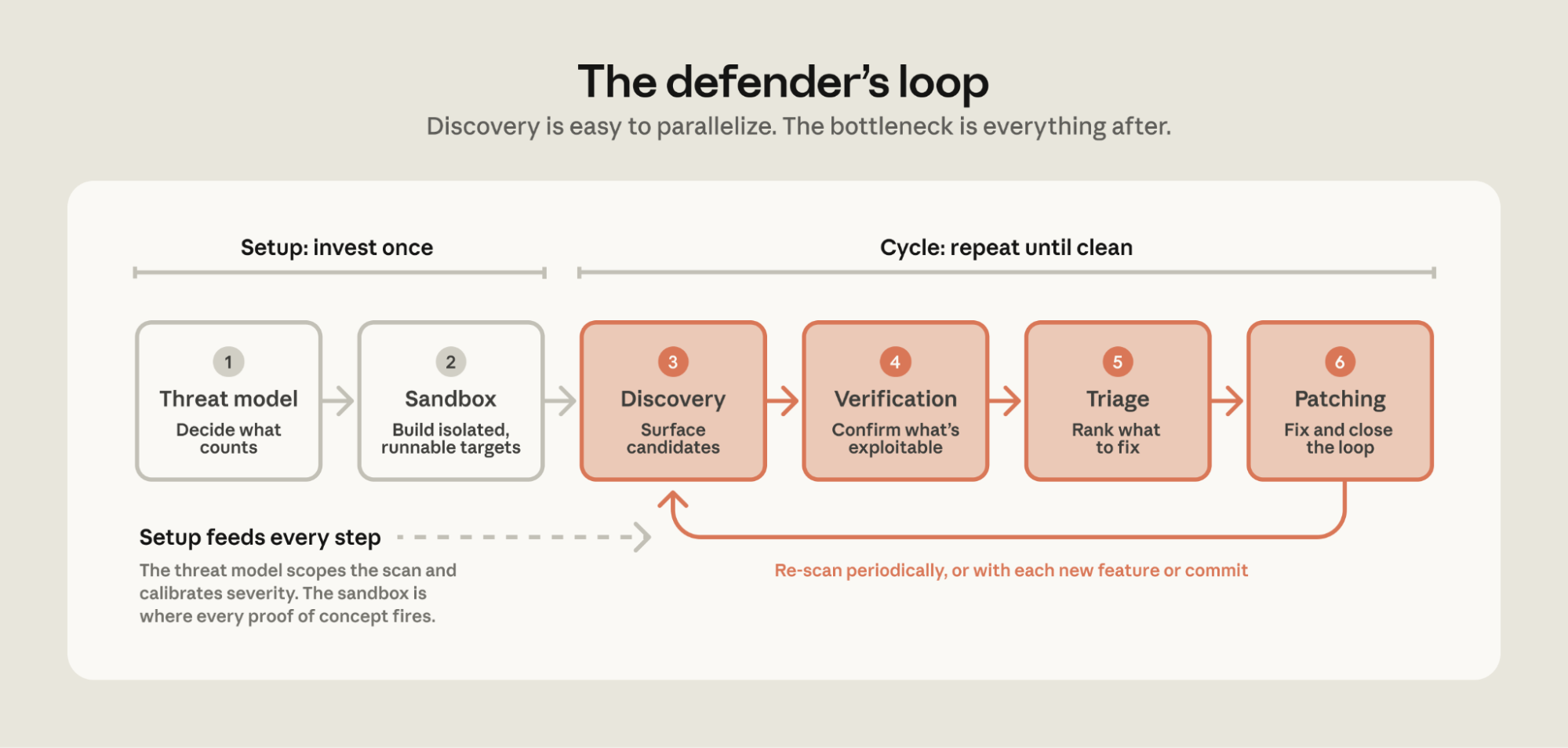
这个管线使用 Docker 和 ASAN(AddressSanitizer)作为基础环境,主要参考实现针对 C/C++ 内存漏洞。ASAN 能在运行时检测出内存安全问题(如堆溢出、空指针解引用、使用后释放等),是安全研究中的标准工具。项目把 ASAN 集成到 Docker 构建流程中,确保每次测试都在隔离且可复现的环境中运行。对于 C/C++ 这类需要编译的静态类型语言,ASAN 的集成方式通常是在编译时添加 -fsanitize=address 标志,让编译器在生成的代码中插入安全检测逻辑。
项目内置了多个 Claude Code Skills,封装了不同阶段的操作指令:/quickstart 用于快速入门,/threat-model 用于构建威胁模型,/vuln-scan 用于漏洞扫描,/triage 用于优先级排序,/patch 用于生成修复补丁,/customize 用于针对不同代码库定制管线。这些 Skills 以交互式方式工作,仅读写文件,不执行目标代码。对于需要实际运行目标代码的自主扫描,则必须通过 vp-sandboxed 命令在 gVisor 沙箱中执行——安全设计要求自主管线拒绝在沙箱外运行,除非明确覆盖。
gVisor 是 Google 推出的容器沙箱运行时,相比传统容器提供了更强的隔离能力。项目中 docs/agent-sandbox.md 详细描述了隔离架构,docs/security.md 阐述了沙箱安全机制。对于需要用 AI Agent 自动扫描外部代码库的场景,沙箱隔离是必要的安全护栏——没有隔离的情况下,Agent 执行的畸形输入可能诱发恶意代码或系统级副作用。这是一个被反复验证的安全原则:让不确定的代码在隔离环境中运行,是防止 Agent 本身被攻击或被滥用的最后一道防线。
项目的文档结构值得注意。docs/blog-post.md 记录了经验总结和最佳实践,docs/pipeline.md 描述管线架构和 CLI 参数,docs/customizing.md 说明了如何将管线移植到其他编程语言、检测器或漏洞类别,docs/patching.md 阐述了修复生成与验证流程。这些文档对于希望基于此框架二次开发的团队来说,是除了代码之外最重要的输入。其中 customing.md 的移植指南尤为关键——它描述了将参考实现从 C/C++ 扩展到其他语言或漏洞类别时需要注意的检测器差异、环境配置和评估指标,这是将参考实现变成可用的生产工具的必经之路。
上线路径设计为五天:第一天构建威胁模型加静态扫描加优先级排序,第二天在 C/C++ 库上运行参考管线,第三到五天针对目标代码库定制管线,第二周起开始自主扫描、排序和修复工作。这个节奏说明项目面向的是有安全研究背景、且愿意投入时间定制的技术团队,而非即开即用的安全产品。对于安全团队而言,这个投入是值得的——每一个被 AI 自动发现且修复的漏洞,都可能是在人工审计中需要数周才能发现的未知问题。
当前项目标记为不再维护且不接受贡献。这是一个有些令人意外但可以理解的决策——参考实现的价值在于提供思路而非维护一个通用产品,每个安全团队的代码库、工具链和需求都有太大差异,照搬框架无法解决实际问题。项目更大的价值是作为一份经过验证的设计文档,帮助安全团队理解"用 AI Agent 做漏洞发现"这件事的分阶段架构、隔离要求和效果评估方式。
开源地址:https://github.com/anthropics/defending-code-reference-harness
