Google于6月3日正式发布了Gemma 4 12B,这是一款统一的多模态模型,在不需要传统多模态编码器的情况下实现了视觉和音频的直接处理。这个参数量的模型被设计为在消费级硬件上运行——仅需16GB显存或统一内存即可在本地运行,这意味着它可以直接部署在高端笔记本电脑上,无需云端算力支持。

从架构角度看,Gemma 4 12B的核心创新在于取消了传统多模态模型中的编码器组件。通常多模态模型需要独立的视觉编码器和音频编码器将图像和声音转换为与文本token维度匹配的表示,但Gemma 4 12B采用了一种轻量级的嵌入层来处理视觉输入——仅包含单次矩阵乘法、位置嵌入和归一化操作,大幅降低了计算复杂度。音频信号则直接投影到文本token维度空间,无需专门的音频编码器。这种"无编码器"设计使得整个模型的体积得以精简,同时也减少了推理时的计算步骤。
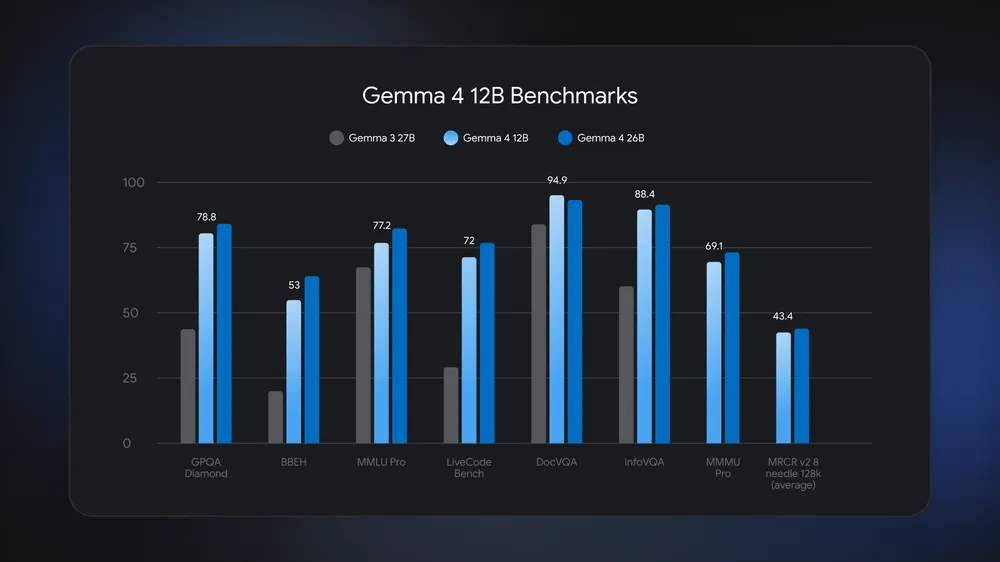
在性能方面,Gemma 4 12B的表现接近Google更大的26B MoE模型,在多项基准测试中展现出强大的多步推理和代理工作流能力。模型配备了Multi-Token Prediction(MTP)drafters,可以同时预测多个token来加速推理过程。截至发布时,Gemma 4系列模型的累计下载量已突破1.5亿次,显示出开发者社区对Google开源模型系列的高度认可。
这款模型采用Apache 2.0许可证开源发布,权重已在Hugging Face和Kaggle平台上架。支持的推理框架包括LM Studio、Ollama、MLX、SGLang和vLLM等,Google自家的AI Edge Gallery也提供了端侧部署支持。在生产环境方面,开发者可以通过Google Cloud的Model Garden、Cloud Run和GKE进行大规模部署。
参考来源:https://blog.google/innovation-and-ai/technology/developers-tools/introducing-gemma-4-12b/
