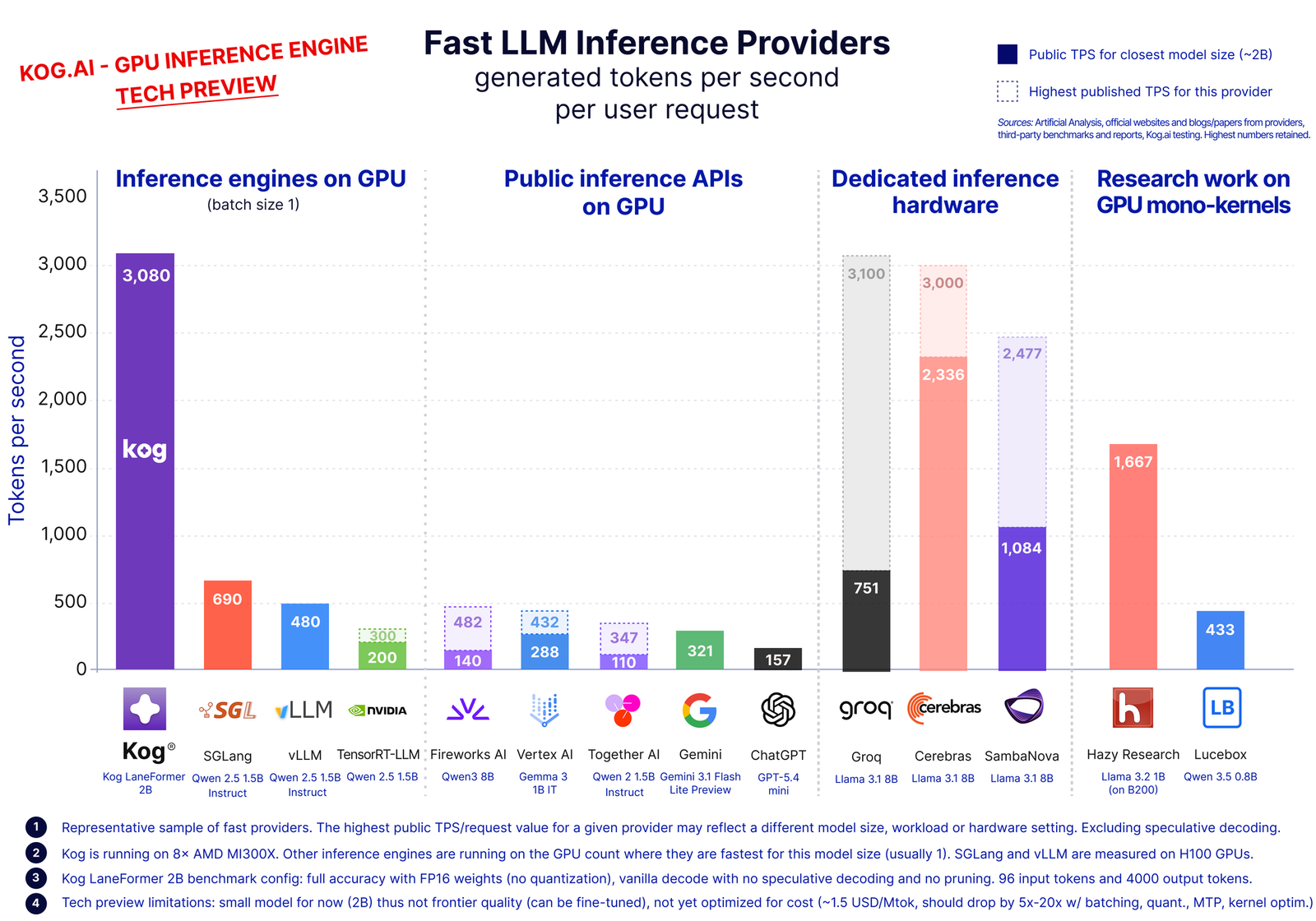
Kog AI 日前发布了 Kog Inference Engine(KIE)技术预览版,在 8× AMD MI300X GPU 上实现单请求 3000 tokens/s 的生成速度,8× NVIDIA H200 上达到 2100 tokens/s。更关键的是,这一成绩在未使用量化、投机解码、剪枝或 KV Cache 压缩的前提下达成。
为什么单请求速度突然重要了
传统推理基准测试通常关注聚合吞吐量和首 token 延迟,但这两个指标都不能准确反映 AI Agent 的实际需求。Agentic 软件工程本质是一个顺序循环:检查、规划、编辑、测试、修订——每一步都依赖前一步的结果。如果一个 Agent 需要在单个工作流中生成 50000 个 token,100 tokens/s 需要约八分钟,而 3000 tokens/s 只需不到二十秒。这个差异直接决定了什么样的产品可以成立。
内存带宽是真正的瓶颈
在 batch size 为 1 时,自回归解码由矩阵-向量运算主导。每个生成的 token 都必须将模型的所有活跃权重从 GPU 内存层次结构中搬运一次。FP16 精度下,一个模型权重占两个字节,每次乘加运算约产生 1 FLOP/byte。现代 AI GPU 提供的峰值 FLOPS 是 HBM 带宽的数百倍——NVIDIA H200 的峰值配比约为 400 FLOPS/byte。这意味着 token 生成速度在达到 FLOPS 限制之前,就已经被内存带宽牢牢限制住了。
对于一个 FP16 下约 4 GB 活跃权重的 2B 参数模型,理论上限为:8× H200 约 7700 tokens/s,8× MI300X 约 8400 tokens/s。KIE 在 MI300X 上实现的 3000 tokens/s 意味着约 36% 的内存带宽利用率。
标准推理栈丢失的微秒
在 3000 tokens/s 时,每个 token 的预算仅有约 333 微秒。一个 25 层的模型,每层如果多耗费 1 微秒,就会消耗 7.5% 的时间预算。
传统抽象栈——高层框架中的模型图逻辑,逐层降低为多个 kernel,由 CPU 运行时调度——对于 333 微秒的 token 预算来说过于笨重。仅 kernel 启动和清理成本约 4.5 微秒,十个 kernel 乘以 25 层就产生 1125 微秒的开销,直接将理论上限压到约 890 tokens/s。
Kog 的解决方案是单内核运行时(Monokernel Runtime):token 生成作为单一持久 GPU 程序运行,消除所有 kernel 边界和 CPU 侧调度对关键路径的影响。此外还有定制的 KCCL GPU 通信层(延迟低于 3 微秒)、IOD 感知的缓冲区放置、以及针对缓存的 kernel 设计。
现状与路线图
KIE 技术预览已在 playground.kog.ai 上线,运行的模型为 Laneformer 2B,在 HumanEval 编程基准上得分 50%,在 NVIDIA Nemotron v1 和 v2 数据集上预训练了 6T token。
下一步将支持大型第三方 MoE 模型。Kog 预估,在 36% 内存带宽利用率下,8× H200 节点运行 GPT-OSS-120B(5.1B 活跃参数)可实现约 2200 tokens/s,DeepSeek-V4-Flash(13B 活跃参数)约 1160 tokens/s。随着可用 HBM 带宽增长和 Kog 技术栈成熟,大型前沿 MoE 模型的速度有望达到 1000-5000 tokens/s/request。
参考来源:https://blog.kog.ai/real-time-llm-inference-on-standard-gpus-3-000-tokens-s-per-request/
